 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrototypeNAS: Rapid Design of Deep Neural Networks for Microcontroller Units
Mar 16, 2026Enabling efficient deep neural network (DNN) inference on edge devices with different hardware constraints is a challenging task that typically requires DNN architectures to be specialized for each device separately. To avoid the huge manual effort, one can use neural architecture search (NAS). However, many existing NAS methods are resource-intensive and time-consuming because they require the training of many different DNNs from scratch. Furthermore, they do not take the resource constraints of the target system into account. To address these shortcomings, we propose PrototypeNAS, a zero-shot NAS method to accelerate and automate the selection, compression, and specialization of DNNs to different target microcontroller units (MCUs). We propose a novel three-step search method that decouples DNN design and specialization from DNN training for a given target platform. First, we present a novel search space that not only cuts out smaller DNNs from a single large architecture, but instead combines the structural optimization of multiple architecture types, as well as optimization of their pruning and quantization configurations. Second, we explore the use of an ensemble of zero-shot proxies during optimization instead of a single one. Third, we propose the use of Hypervolume subset selection to distill DNN architectures from the Pareto front of the multi-objective optimization that represent the most meaningful tradeoffs between accuracy and FLOPs. We evaluate the effectiveness of PrototypeNAS on 12 different datasets in three different tasks: image classification, time series classification, and object detection. Our results demonstrate that PrototypeNAS is able to identify DNN models within minutes that are small enough to be deployed on off-the-shelf MCUs and still achieve accuracies comparable to the performance of large DNN models.
microYOLO: Towards Single-Shot Object Detection on Microcontrollers
Aug 28, 2024This work-in-progress paper presents results on the feasibility of single-shot object detection on microcontrollers using YOLO. Single-shot object detectors like YOLO are widely used, however due to their complexity mainly on larger GPU-based platforms. We present microYOLO, which can be used on Cortex-M based microcontrollers, such as the OpenMV H7 R2, achieving about 3.5 FPS when classifying 128x128 RGB images while using less than 800 KB Flash and less than 350 KB RAM. Furthermore, we share experimental results for three different object detection tasks, analyzing the accuracy of microYOLO on them.
On-Device Training of Fully Quantized Deep Neural Networks on Cortex-M Microcontrollers
Jul 15, 2024On-device training of DNNs allows models to adapt and fine-tune to newly collected data or changing domains while deployed on microcontroller units (MCUs). However, DNN training is a resource-intensive task, making the implementation and execution of DNN training algorithms on MCUs challenging due to low processor speeds, constrained throughput, limited floating-point support, and memory constraints. In this work, we explore on-device training of DNNs for Cortex-M MCUs. We present a method that enables efficient training of DNNs completely in place on the MCU using fully quantized training (FQT) and dynamic partial gradient updates. We demonstrate the feasibility of our approach on multiple vision and time-series datasets and provide insights into the tradeoff between training accuracy, memory overhead, energy, and latency on real hardware.
Augmented Random Search for Multi-Objective Bayesian Optimization of Neural Networks
May 23, 2023Deploying Deep Neural Networks (DNNs) on tiny devices is a common trend to process the increasing amount of sensor data being generated. Multi-objective optimization approaches can be used to compress DNNs by applying network pruning and weight quantization to minimize the memory footprint (RAM), the number of parameters (ROM) and the number of floating point operations (FLOPs) while maintaining the predictive accuracy. In this paper, we show that existing multi-objective Bayesian optimization (MOBOpt) approaches can fall short in finding optimal candidates on the Pareto front and propose a novel solver based on an ensemble of competing parametric policies trained using an Augmented Random Search Reinforcement Learning (RL) agent. Our methodology aims at finding feasible tradeoffs between a DNN's predictive accuracy, memory consumption on a given target system, and computational complexity. Our experiments show that we outperform existing MOBOpt approaches consistently on different data sets and architectures such as ResNet-18 and MobileNetV3.
Deployment of Energy-Efficient Deep Learning Models on Cortex-M based Microcontrollers using Deep Compression
May 20, 2022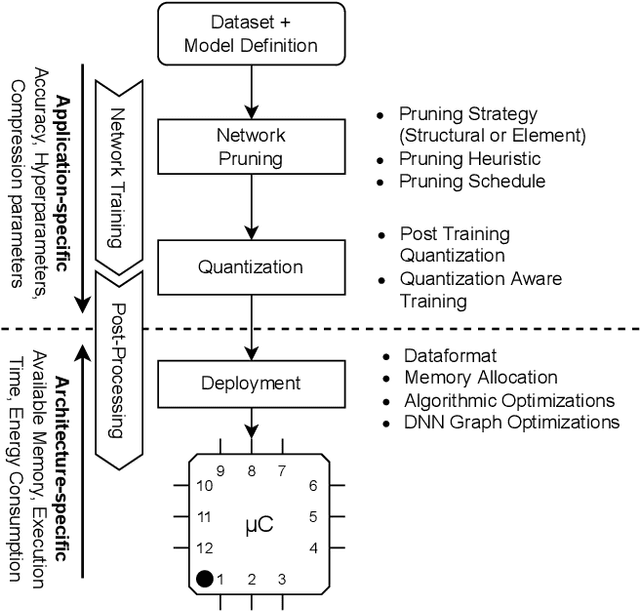
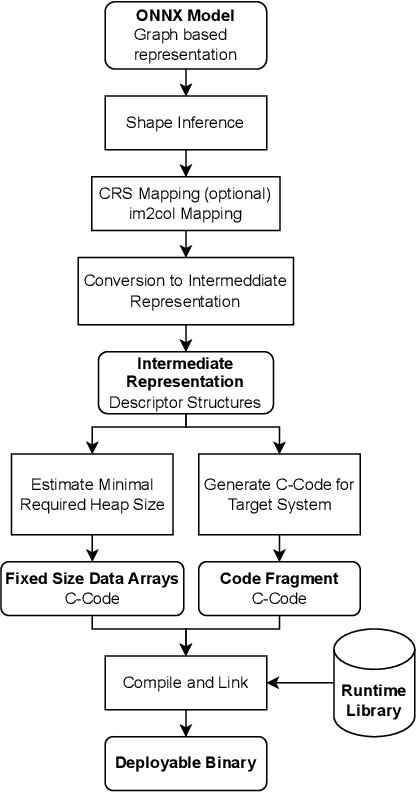

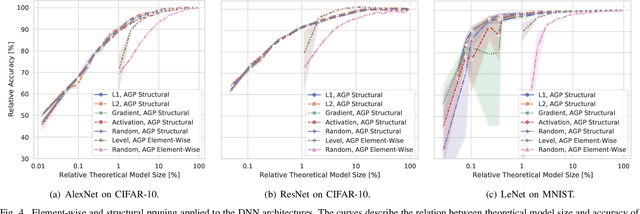
Large Deep Neural Networks (DNNs) are the backbone of today's artificial intelligence due to their ability to make accurate predictions when being trained on huge datasets. With advancing technologies, such as the Internet of Things, interpreting large quantities of data generated by sensors is becoming an increasingly important task. However, in many applications not only the predictive performance but also the energy consumption of deep learning models is of major interest. This paper investigates the efficient deployment of deep learning models on resource-constrained microcontroller architectures via network compression. We present a methodology for the systematic exploration of different DNN pruning, quantization, and deployment strategies, targeting different ARM Cortex-M based low-power systems. The exploration allows to analyze trade-offs between key metrics such as accuracy, memory consumption, execution time, and power consumption. We discuss experimental results on three different DNN architectures and show that we can compress them to below 10\% of their original parameter count before their predictive quality decreases. This also allows us to deploy and evaluate them on Cortex-M based microcontrollers.