 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardware/Software Co-Design of RISC-V Extensions for Accelerating Sparse DNNs on FPGAs
Apr 28, 2025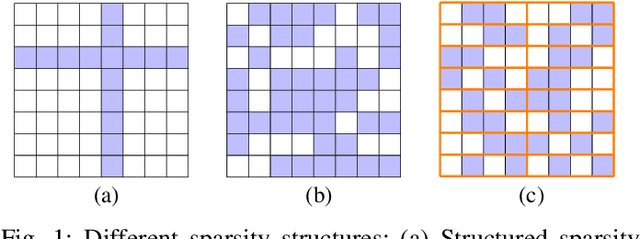
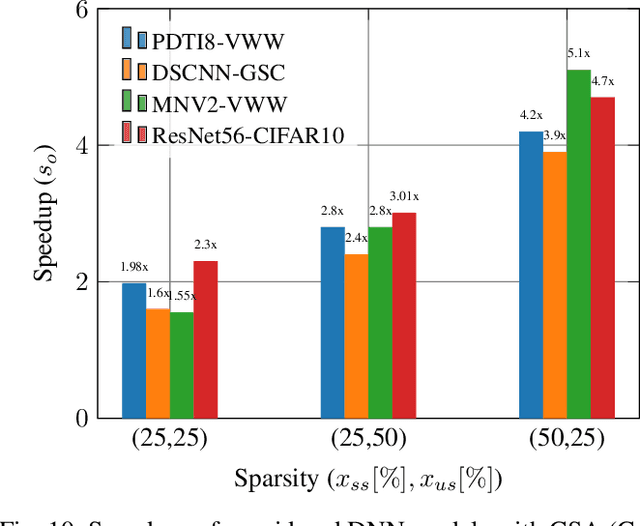
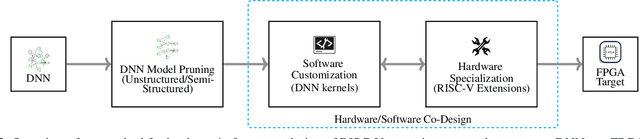
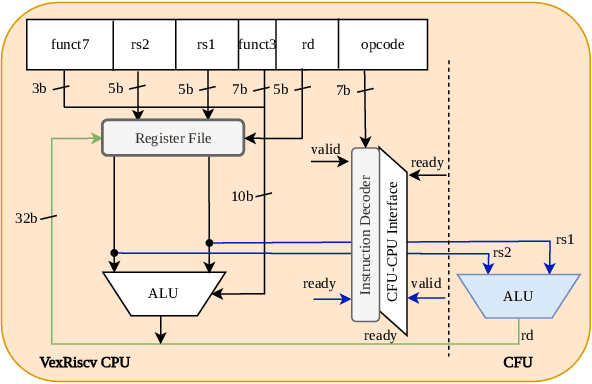
The customizability of RISC-V makes it an attractive choice for accelerating deep neural networks (DNNs). It can be achieved through instruction set extensions and corresponding custom functional units. Yet, efficiently exploiting these opportunities requires a hardware/software co-design approach in which the DNN model, software, and hardware are designed together. In this paper, we propose novel RISC-V extensions for accelerating DNN models containing semi-structured and unstructured sparsity. While the idea of accelerating structured and unstructured pruning is not new, our novel design offers various advantages over other designs. To exploit semi-structured sparsity, we take advantage of the fine-grained (bit-level) configurability of FPGAs and suggest reserving a few bits in a block of DNN weights to encode the information about sparsity in the succeeding blocks. The proposed custom functional unit utilizes this information to skip computations. To exploit unstructured sparsity, we propose a variable cycle sequential multiply-and-accumulate unit that performs only as many multiplications as the non-zero weights. Our implementation of unstructured and semi-structured pruning accelerators can provide speedups of up to a factor of 3 and 4, respectively. We then propose a combined design that can accelerate both types of sparsities, providing speedups of up to a factor of 5. Our designs consume a small amount of additional FPGA resources such that the resulting co-designs enable the acceleration of DNNs even on small FPGAs. We benchmark our designs on standard TinyML applications such as keyword spotting, image classification, and person detection.
On-Device Training of Fully Quantized Deep Neural Networks on Cortex-M Microcontrollers
Jul 15, 2024On-device training of DNNs allows models to adapt and fine-tune to newly collected data or changing domains while deployed on microcontroller units (MCUs). However, DNN training is a resource-intensive task, making the implementation and execution of DNN training algorithms on MCUs challenging due to low processor speeds, constrained throughput, limited floating-point support, and memory constraints. In this work, we explore on-device training of DNNs for Cortex-M MCUs. We present a method that enables efficient training of DNNs completely in place on the MCU using fully quantized training (FQT) and dynamic partial gradient updates. We demonstrate the feasibility of our approach on multiple vision and time-series datasets and provide insights into the tradeoff between training accuracy, memory overhead, energy, and latency on real hardware.
OpTC -- A Toolchain for Deployment of Neural Networks on AURIX TC3xx Microcontrollers
Apr 24, 2024The AURIX 2xx and 3xx families of TriCore microcontrollers are widely used in the automotive industry and, recently, also in applications that involve machine learning tasks. Yet, these applications are mainly engineered manually, and only little tool support exists for bringing neural networks to TriCore microcontrollers. Thus, we propose OpTC, an end-to-end toolchain for automatic compression, conversion, code generation, and deployment of neural networks on TC3xx microcontrollers. OpTC supports various types of neural networks and provides compression using layer-wise pruning based on sensitivity analysis for a given neural network. The flexibility in supporting different types of neural networks, such as multi-layer perceptrons (MLP), convolutional neural networks (CNN), and recurrent neural networks (RNN), is shown in case studies for a TC387 microcontroller. Automotive applications for predicting the temperature in electric motors and detecting anomalies are thereby used to demonstrate the effectiveness and the wide range of applications supported by OpTC.
To Spike or Not to Spike? A Quantitative Comparison of SNN and CNN FPGA Implementations
Jun 22, 2023Convolutional Neural Networks (CNNs) are widely employed to solve various problems, e.g., image classification. Due to their compute- and data-intensive nature, CNN accelerators have been developed as ASICs or on FPGAs. Increasing complexity of applications has caused resource costs and energy requirements of these accelerators to grow. Spiking Neural Networks (SNNs) are an emerging alternative to CNN implementations, promising higher resource and energy efficiency. The main research question addressed in this paper is whether SNN accelerators truly meet these expectations of reduced energy requirements compared to their CNN equivalents. For this purpose, we analyze multiple SNN hardware accelerators for FPGAs regarding performance and energy efficiency. We present a novel encoding scheme of spike event queues and a novel memory organization technique to improve SNN energy efficiency further. Both techniques have been integrated into a state-of-the-art SNN architecture and evaluated for MNIST, SVHN, and CIFAR-10 datasets and corresponding network architectures on two differently sized modern FPGA platforms. For small-scale benchmarks such as MNIST, SNN designs provide rather no or little latency and energy efficiency advantages over corresponding CNN implementations. For more complex benchmarks such as SVHN and CIFAR-10, the trend reverses.
Proceedings of the DATE Friday Workshop on System-level Design Methods for Deep Learning on Heterogeneous Architectures
Jan 27, 2021This volume contains the papers accepted at the first DATE Friday Workshop on System-level Design Methods for Deep Learning on Heterogeneous Architectures (SLOHA 2021), held virtually on February 5, 2021. SLOHA 2021 was co-located with the Conference on Design, Automation and Test in Europe (DATE).
HipaccVX: Wedding of OpenVX and DSL-based Code Generation
Aug 26, 2020
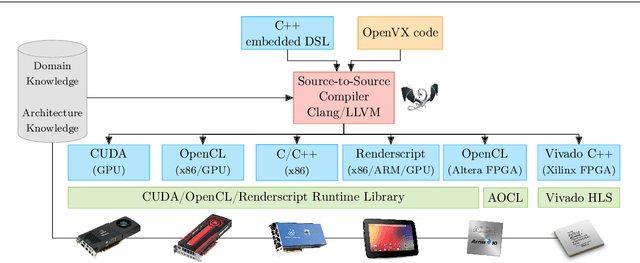


Writing programs for heterogeneous platforms optimized for high performance is hard since this requires the code to be tuned at a low level with architecture-specific optimizations that are most times based on fundamentally differing programming paradigms and languages. OpenVX promises to solve this issue for computer vision applications with a royalty-free industry standard that is based on a graph-execution model. Yet, the OpenVX' algorithm space is constrained to a small set of vision functions. This hinders accelerating computations that are not included in the standard. In this paper, we analyze OpenVX vision functions to find an orthogonal set of computational abstractions. Based on these abstractions, we couple an existing Domain-Specific Language (DSL) back end to the OpenVX environment and provide language constructs to the programmer for the definition of user-defined nodes. In this way, we enable optimizations that are not possible to detect with OpenVX graph implementations using the standard computer vision functions. These optimizations can double the throughput on an Nvidia GTX GPU and decrease the resource usage of a Xilinx Zynq FPGA by 50% for our benchmarks. Finally, we show that our proposed compiler framework, called HipaccVX, can achieve better results than the state-of-the-art approaches Nvidia VisionWorks and Halide-HLS.
Utilizing Explainable AI for Quantization and Pruning of Deep Neural Networks
Aug 20, 2020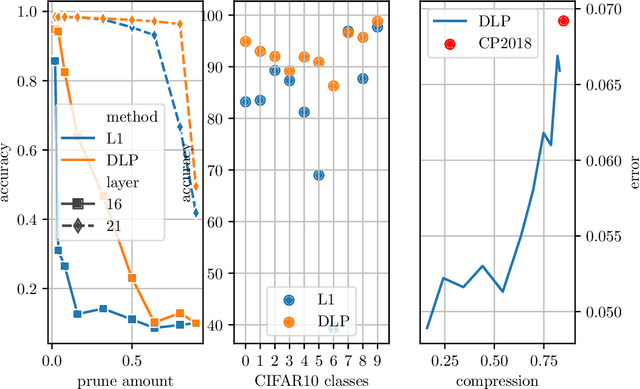

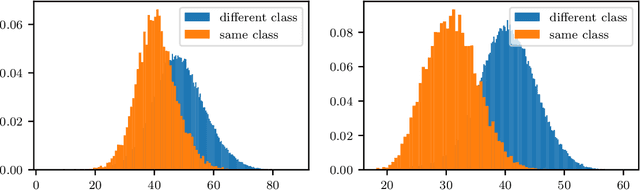
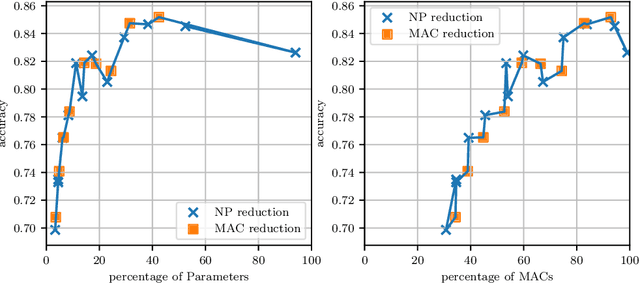
For many applications, utilizing DNNs (Deep Neural Networks) requires their implementation on a target architecture in an optimized manner concerning energy consumption, memory requirement, throughput, etc. DNN compression is used to reduce the memory footprint and complexity of a DNN before its deployment on hardware. Recent efforts to understand and explain AI (Artificial Intelligence) methods have led to a new research area, termed as explainable AI. Explainable AI methods allow us to understand better the inner working of DNNs, such as the importance of different neurons and features. The concepts from explainable AI provide an opportunity to improve DNN compression methods such as quantization and pruning in several ways that have not been sufficiently explored so far. In this paper, we utilize explainable AI methods: mainly DeepLIFT method. We use these methods for (1) pruning of DNNs; this includes structured and unstructured pruning of \ac{CNN} filters pruning as well as pruning weights of fully connected layers, (2) non-uniform quantization of DNN weights using clustering algorithm; this is also referred to as Weight Sharing, and (3) integer-based mixed-precision quantization; this is where each layer of a DNN may use a different number of integer bits. We use typical image classification datasets with common deep learning image classification models for evaluation. In all these three cases, we demonstrate significant improvements as well as new insights and opportunities from the use of explainable AI in DNN compression.
Automatic Optimization of Hardware Accelerators for Image Processing
Feb 26, 2015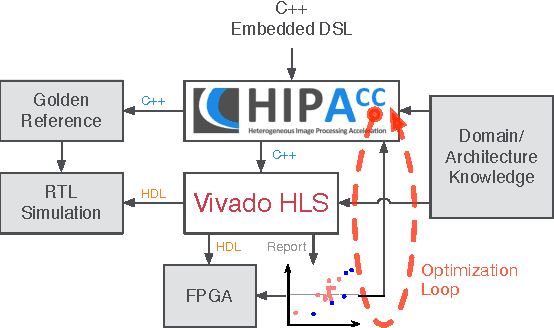
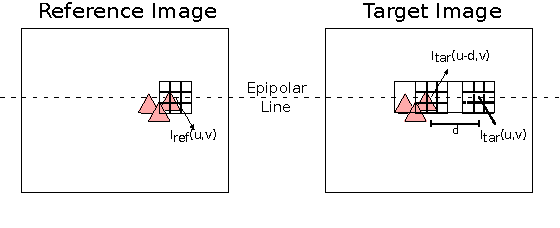
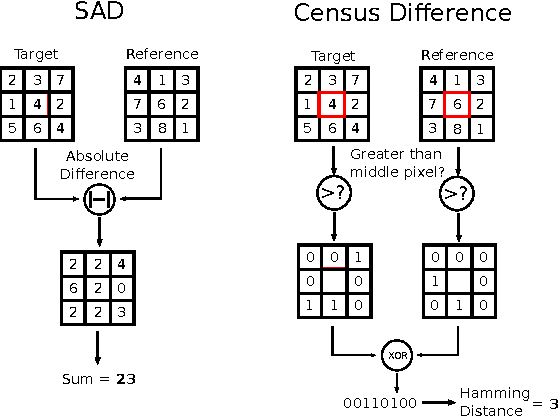
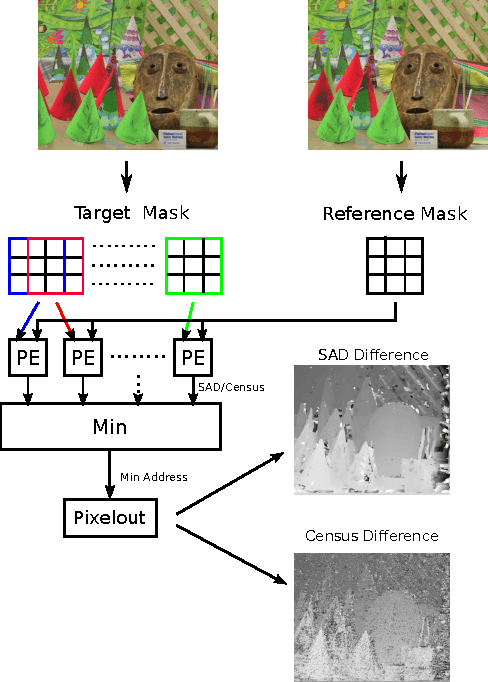
In the domain of image processing, often real-time constraints are required. In particular, in safety-critical applications, such as X-ray computed tomography in medical imaging or advanced driver assistance systems in the automotive domain, timing is of utmost importance. A common approach to maintain real-time capabilities of compute-intensive applications is to offload those computations to dedicated accelerator hardware, such as Field Programmable Gate Arrays (FPGAs). Programming such architectures is a challenging task, with respect to the typical FPGA-specific design criteria: Achievable overall algorithm latency and resource usage of FPGA primitives (BRAM, FF, LUT, and DSP). High-Level Synthesis (HLS) dramatically simplifies this task by enabling the description of algorithms in well-known higher languages (C/C++) and its automatic synthesis that can be accomplished by HLS tools. However, algorithm developers still need expert knowledge about the target architecture, in order to achieve satisfying results. Therefore, in previous work, we have shown that elevating the description of image algorithms to an even higher abstraction level, by using a Domain-Specific Language (DSL), can significantly cut down the complexity for designing such algorithms for FPGAs. To give the developer even more control over the common trade-off, latency vs. resource usage, we will present an automatic optimization process where these criteria are analyzed and fed back to the DSL compiler, in order to generate code that is closer to the desired design specifications. Finally, we generate code for stereo block matching algorithms and compare it with handwritten implementations to quantify the quality of our results.
Proceedings of the DATE Friday Workshop on Heterogeneous Architectures and Design Methods for Embedded Image Systems
Feb 26, 2015This volume contains the papers accepted at the DATE Friday Workshop on Heterogeneous Architectures and Design Methods for Embedded Image Systems (HIS 2015), held in Grenoble, France, March 13, 2015. HIS 2015 was co-located with the Conference on Design, Automation and Test in Europe (DATE).
Code Generation for High-Level Synthesis of Multiresolution Applications on FPGAs
Aug 20, 2014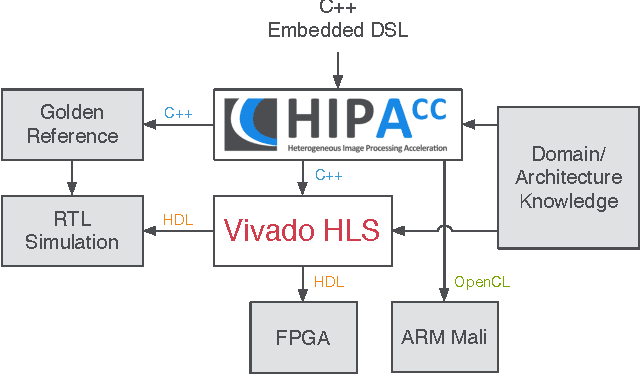
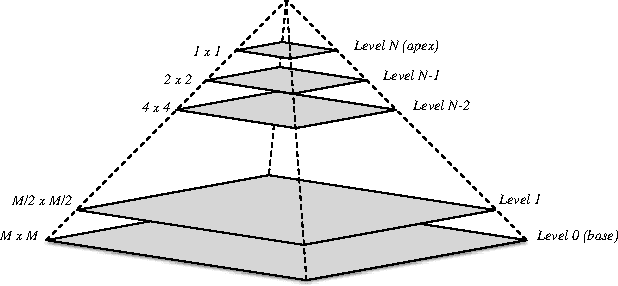
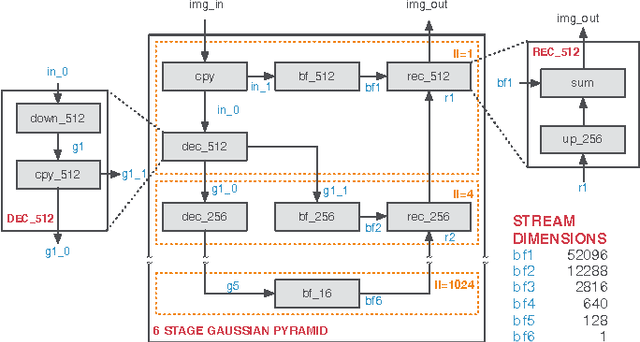
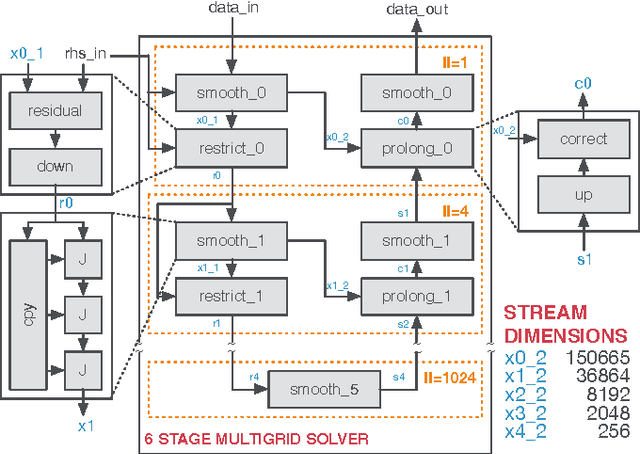
Multiresolution Analysis (MRA) is a mathematical method that is based on working on a problem at different scales. One of its applications is medical imaging where processing at multiple scales, based on the concept of Gaussian and Laplacian image pyramids, is a well-known technique. It is often applied to reduce noise while preserving image detail on different levels of granularity without modifying the filter kernel. In scientific computing, multigrid methods are a popular choice, as they are asymptotically optimal solvers for elliptic Partial Differential Equations (PDEs). As such algorithms have a very high computational complexity that would overwhelm CPUs in the presence of real-time constraints, application-specific processors come into consideration for implementation. Despite of huge advancements in leveraging productivity in the respective fields, designers are still required to have detailed knowledge about coding techniques and the targeted architecture to achieve efficient solutions. Recently, the HIPAcc framework was proposed as a means for automatic code generation of image processing algorithms, based on a Domain-Specific Language (DSL). From the same code base, it is possible to generate code for efficient implementations on several accelerator technologies including different types of Graphics Processing Units (GPUs) as well as reconfigurable logic (FPGAs). In this work, we demonstrate the ability of HIPAcc to generate code for the implementation of multiresolution applications on FPGAs and embedded GPUs.