 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilizing Explainable AI for Quantization and Pruning of Deep Neural Networks
Aug 20, 2020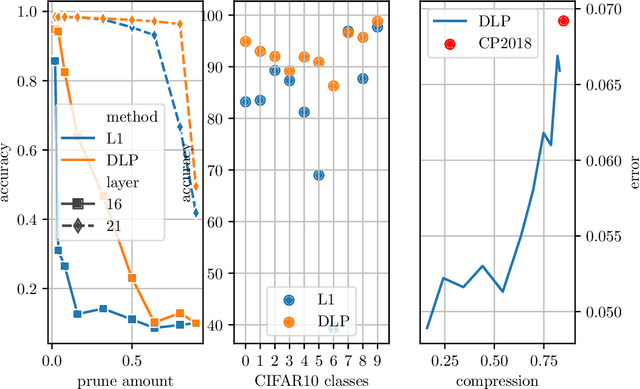

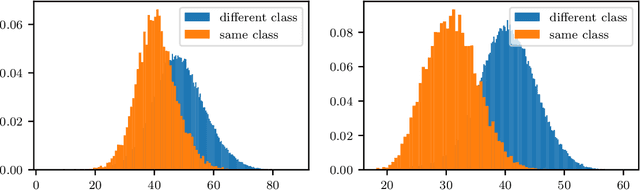
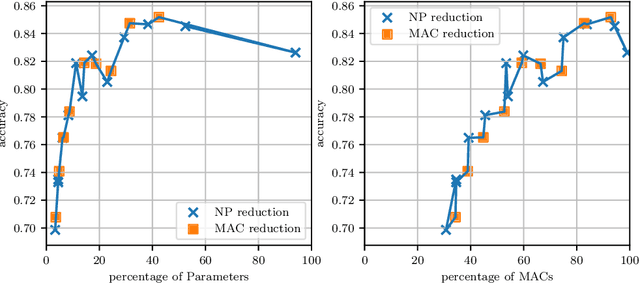
For many applications, utilizing DNNs (Deep Neural Networks) requires their implementation on a target architecture in an optimized manner concerning energy consumption, memory requirement, throughput, etc. DNN compression is used to reduce the memory footprint and complexity of a DNN before its deployment on hardware. Recent efforts to understand and explain AI (Artificial Intelligence) methods have led to a new research area, termed as explainable AI. Explainable AI methods allow us to understand better the inner working of DNNs, such as the importance of different neurons and features. The concepts from explainable AI provide an opportunity to improve DNN compression methods such as quantization and pruning in several ways that have not been sufficiently explored so far. In this paper, we utilize explainable AI methods: mainly DeepLIFT method. We use these methods for (1) pruning of DNNs; this includes structured and unstructured pruning of \ac{CNN} filters pruning as well as pruning weights of fully connected layers, (2) non-uniform quantization of DNN weights using clustering algorithm; this is also referred to as Weight Sharing, and (3) integer-based mixed-precision quantization; this is where each layer of a DNN may use a different number of integer bits. We use typical image classification datasets with common deep learning image classification models for evaluation. In all these three cases, we demonstrate significant improvements as well as new insights and opportunities from the use of explainable AI in DNN compression.