 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Optimization of Hardware Accelerators for Image Processing
Feb 26, 2015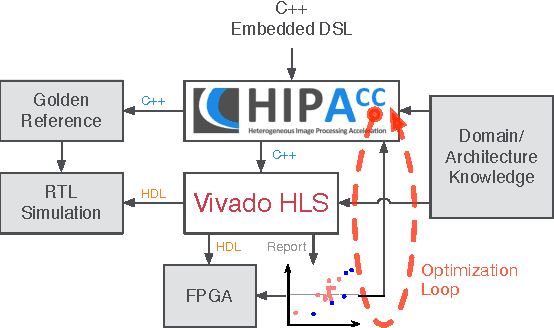
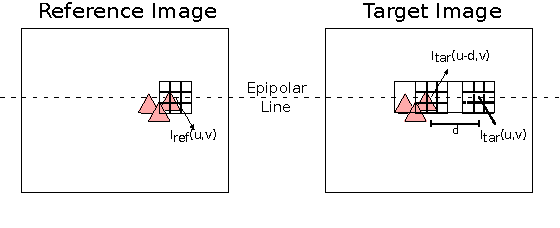
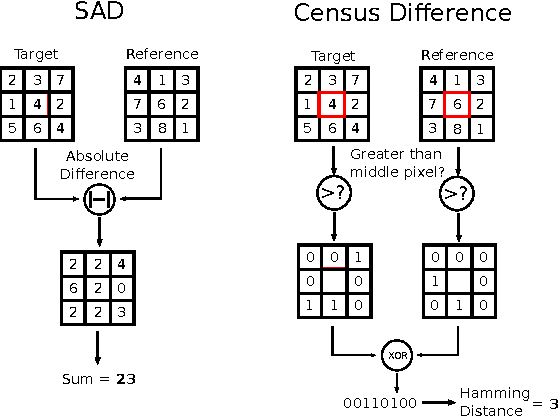
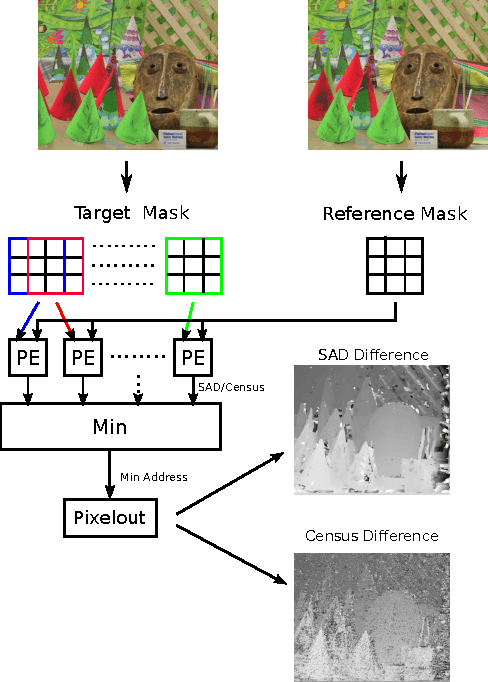
In the domain of image processing, often real-time constraints are required. In particular, in safety-critical applications, such as X-ray computed tomography in medical imaging or advanced driver assistance systems in the automotive domain, timing is of utmost importance. A common approach to maintain real-time capabilities of compute-intensive applications is to offload those computations to dedicated accelerator hardware, such as Field Programmable Gate Arrays (FPGAs). Programming such architectures is a challenging task, with respect to the typical FPGA-specific design criteria: Achievable overall algorithm latency and resource usage of FPGA primitives (BRAM, FF, LUT, and DSP). High-Level Synthesis (HLS) dramatically simplifies this task by enabling the description of algorithms in well-known higher languages (C/C++) and its automatic synthesis that can be accomplished by HLS tools. However, algorithm developers still need expert knowledge about the target architecture, in order to achieve satisfying results. Therefore, in previous work, we have shown that elevating the description of image algorithms to an even higher abstraction level, by using a Domain-Specific Language (DSL), can significantly cut down the complexity for designing such algorithms for FPGAs. To give the developer even more control over the common trade-off, latency vs. resource usage, we will present an automatic optimization process where these criteria are analyzed and fed back to the DSL compiler, in order to generate code that is closer to the desired design specifications. Finally, we generate code for stereo block matching algorithms and compare it with handwritten implementations to quantify the quality of our results.
Code Generation for High-Level Synthesis of Multiresolution Applications on FPGAs
Aug 20, 2014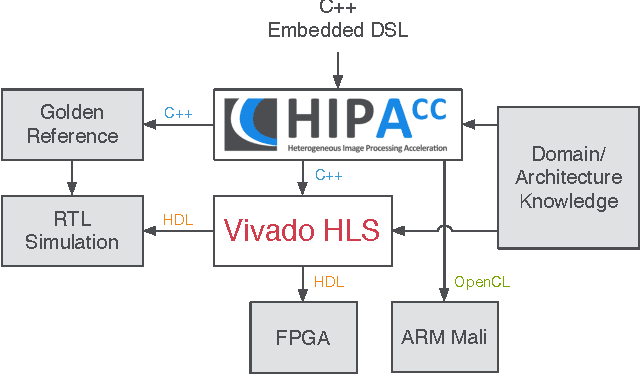
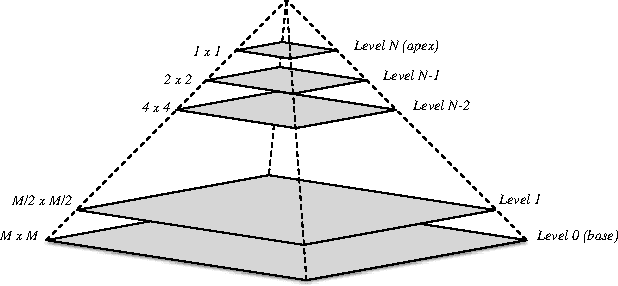
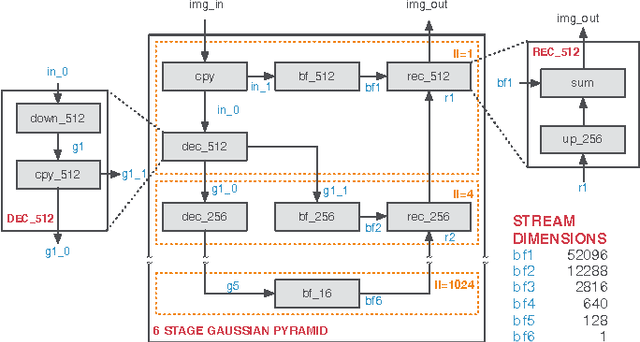
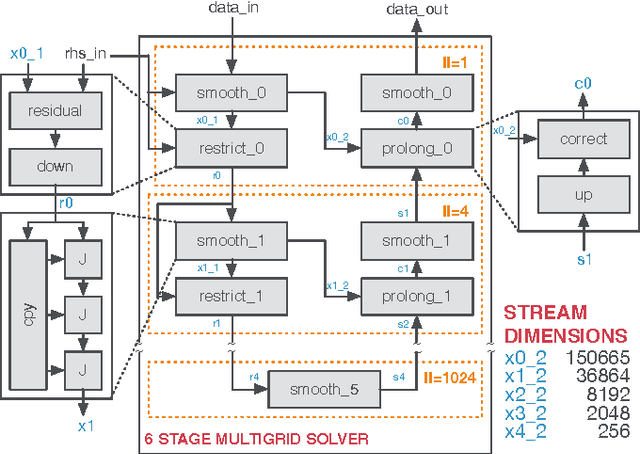
Multiresolution Analysis (MRA) is a mathematical method that is based on working on a problem at different scales. One of its applications is medical imaging where processing at multiple scales, based on the concept of Gaussian and Laplacian image pyramids, is a well-known technique. It is often applied to reduce noise while preserving image detail on different levels of granularity without modifying the filter kernel. In scientific computing, multigrid methods are a popular choice, as they are asymptotically optimal solvers for elliptic Partial Differential Equations (PDEs). As such algorithms have a very high computational complexity that would overwhelm CPUs in the presence of real-time constraints, application-specific processors come into consideration for implementation. Despite of huge advancements in leveraging productivity in the respective fields, designers are still required to have detailed knowledge about coding techniques and the targeted architecture to achieve efficient solutions. Recently, the HIPAcc framework was proposed as a means for automatic code generation of image processing algorithms, based on a Domain-Specific Language (DSL). From the same code base, it is possible to generate code for efficient implementations on several accelerator technologies including different types of Graphics Processing Units (GPUs) as well as reconfigurable logic (FPGAs). In this work, we demonstrate the ability of HIPAcc to generate code for the implementation of multiresolution applications on FPGAs and embedded GPUs.