 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiplier-free In-Memory Vector-Matrix Multiplication Using Distributed Arithmetic
Oct 02, 2025Vector-Matrix Multiplication (VMM) is the fundamental and frequently required computation in inference of Neural Networks (NN). Due to the large data movement required during inference, VMM can benefit greatly from in-memory computing. However, ADC/DACs required for in-memory VMM consume significant power and area. `Distributed Arithmetic (DA)', a technique in computer architecture prevalent in 1980s was used to achieve inner product or dot product of two vectors without using a hard-wired multiplier when one of the vectors is a constant. In this work, we extend the DA technique to multiply an input vector with a constant matrix. By storing the sum of the weights in memory, DA achieves VMM using shift-and-add circuits in the periphery of ReRAM memory. We verify functional and also estimate non-functional properties (latency, energy, area) by performing transistor-level simulations. Using energy-efficient sensing and fine grained pipelining, our approach achieves 4.5 x less latency and 12 x less energy than VMM performed in memory conventionally by bit slicing. Furthermore, DA completely eliminated the need for power-hungry ADCs which are the main source of area and energy consumption in the current VMM implementations in memory.
Implementation of Real-Time Automotive SAR Imaging
Jun 16, 2023



This paper presents measures to reduce the computation time of automotive synthetic aperture radar (SAR) imaging to achieve real-time capability. For this, the image formation, which is based on the Back-Projection algorithm, was thoroughly analyzed. Various optimizations were individually tested and analyzed on graphics processing units (GPU). Apart from the time reduction gained from these measures, the data size needed for processing was also drastically decreased. With a combination of all measures, a high-resolution SAR image of 30 m by 30 m that combines 8192 chirps can be reconstructed in less than 30 ms using a standard GPU. It is thus demonstrated that a real-time implementation of automotive SAR is possible.
Estimation of Non-Functional Properties for Embedded Hardware with Application to Image Processing
Mar 03, 2022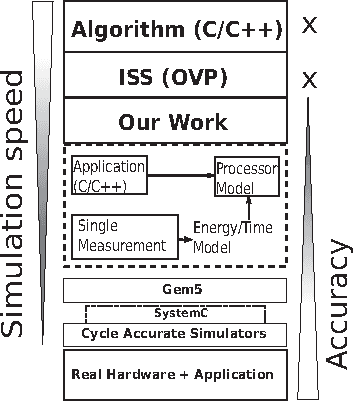
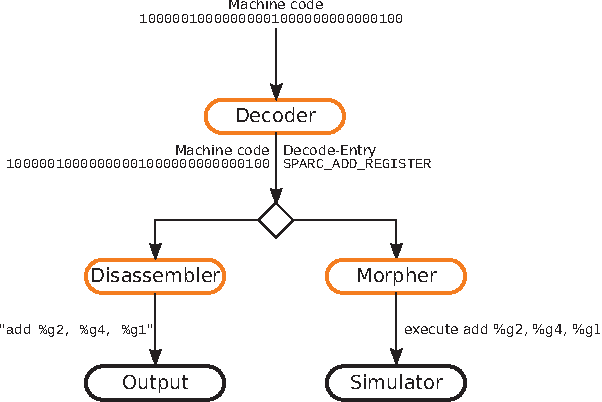
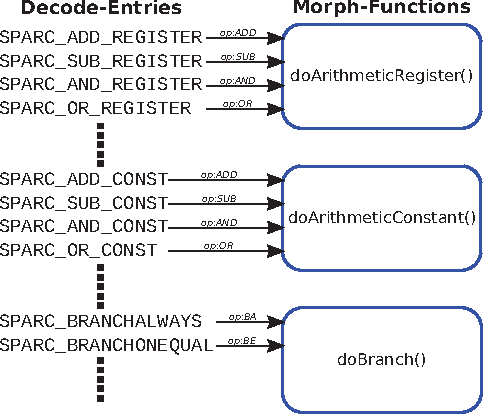
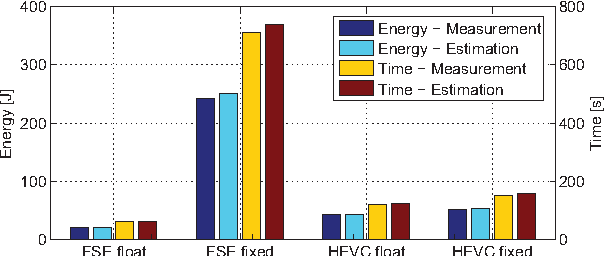
In recent years, due to a higher demand for portable devices, which provide restricted amounts of processing capacity and battery power, the need for energy and time efficient hard- and software solutions has increased. Preliminary estimations of time and energy consumption can thus be valuable to improve implementations and design decisions. To this end, this paper presents a method to estimate the time and energy consumption of a given software solution, without having to rely on the use of a traditional Cycle Accurate Simulator (CAS). Instead, we propose to utilize a combination of high-level functional simulation with a mechanistic extension to include non-functional properties: Instruction counts from virtual execution are multiplied with corresponding specific energies and times. By evaluating two common image processing algorithms on an FPGA-based CPU, where a mean relative estimation error of 3% is achieved for cacheless systems, we show that this estimation tool can be a valuable aid in the development of embedded processor architectures. The tool allows the developer to reach well-suited design decisions regarding the optimal processor hardware configuration for a given algorithm at an early stage in the design process.
A Holistic Approach for Modeling and Synthesis of Image Processing Applications for Heterogeneous Computing Architectures
Feb 26, 2015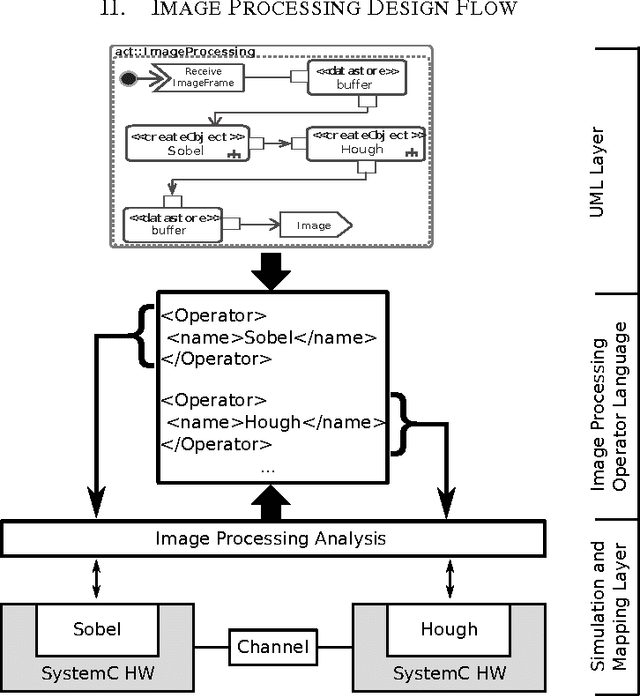
Image processing applications are common in every field of our daily life. However, most of them are very complex and contain several tasks with different complexities which result in varying requirements for computing architectures. Nevertheless, a general processing scheme in every image processing application has a similar structure, called image processing pipeline: (1) capturing an image, (2) pre-processing using local operators, (3) processing with global operators and (4) post-processing using complex operations. Therefore, application-specialized hardware solutions based on heterogeneous architectures are used for image processing. Unfortunately the development of applications for heterogeneous hardware architectures is challenging due to the distribution of computational tasks among processors and programmable logic units. Nowadays, image processing systems are started from scratch which is time-consuming, error-prone and inflexible. A new methodology for modeling and implementing is needed in order to reduce the development time of heterogenous image processing systems. This paper introduces a new holistic top down approach for image processing systems. Two challenges have to be investigated. First, designers ought to be able to model their complete image processing pipeline on an abstract layer using UML. Second, we want to close the gap between the abstract system and the system architecture.
Automatic Optimization of Hardware Accelerators for Image Processing
Feb 26, 2015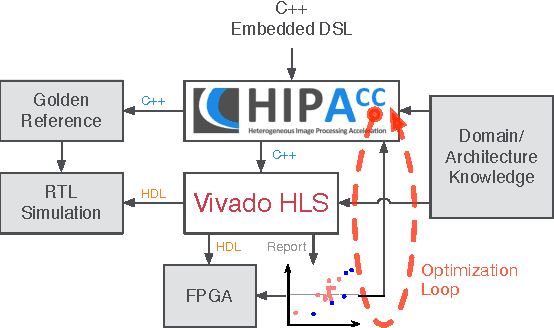
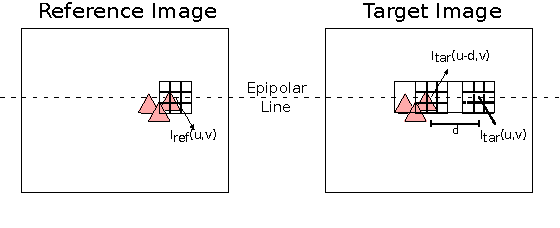
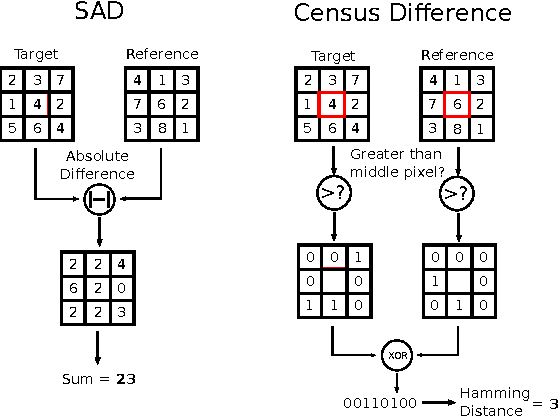
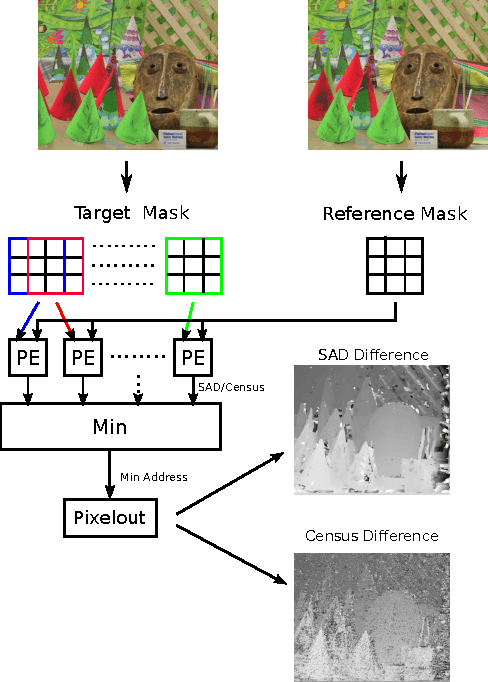
In the domain of image processing, often real-time constraints are required. In particular, in safety-critical applications, such as X-ray computed tomography in medical imaging or advanced driver assistance systems in the automotive domain, timing is of utmost importance. A common approach to maintain real-time capabilities of compute-intensive applications is to offload those computations to dedicated accelerator hardware, such as Field Programmable Gate Arrays (FPGAs). Programming such architectures is a challenging task, with respect to the typical FPGA-specific design criteria: Achievable overall algorithm latency and resource usage of FPGA primitives (BRAM, FF, LUT, and DSP). High-Level Synthesis (HLS) dramatically simplifies this task by enabling the description of algorithms in well-known higher languages (C/C++) and its automatic synthesis that can be accomplished by HLS tools. However, algorithm developers still need expert knowledge about the target architecture, in order to achieve satisfying results. Therefore, in previous work, we have shown that elevating the description of image algorithms to an even higher abstraction level, by using a Domain-Specific Language (DSL), can significantly cut down the complexity for designing such algorithms for FPGAs. To give the developer even more control over the common trade-off, latency vs. resource usage, we will present an automatic optimization process where these criteria are analyzed and fed back to the DSL compiler, in order to generate code that is closer to the desired design specifications. Finally, we generate code for stereo block matching algorithms and compare it with handwritten implementations to quantify the quality of our results.
Proceedings of the DATE Friday Workshop on Heterogeneous Architectures and Design Methods for Embedded Image Systems
Feb 26, 2015This volume contains the papers accepted at the DATE Friday Workshop on Heterogeneous Architectures and Design Methods for Embedded Image Systems (HIS 2015), held in Grenoble, France, March 13, 2015. HIS 2015 was co-located with the Conference on Design, Automation and Test in Europe (DATE).