 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLPerf Power: Benchmarking the Energy Efficiency of Machine Learning Systems from μWatts to MWatts for Sustainable AI
Oct 15, 2024



Rapid adoption of machine learning (ML) technologies has led to a surge in power consumption across diverse systems, from tiny IoT devices to massive datacenter clusters. Benchmarking the energy efficiency of these systems is crucial for optimization, but presents novel challenges due to the variety of hardware platforms, workload characteristics, and system-level interactions. This paper introduces MLPerf Power, a comprehensive benchmarking methodology with capabilities to evaluate the energy efficiency of ML systems at power levels ranging from microwatts to megawatts. Developed by a consortium of industry professionals from more than 20 organizations, MLPerf Power establishes rules and best practices to ensure comparability across diverse architectures. We use representative workloads from the MLPerf benchmark suite to collect 1,841 reproducible measurements from 60 systems across the entire range of ML deployment scales. Our analysis reveals trade-offs between performance, complexity, and energy efficiency across this wide range of systems, providing actionable insights for designing optimized ML solutions from the smallest edge devices to the largest cloud infrastructures. This work emphasizes the importance of energy efficiency as a key metric in the evaluation and comparison of the ML system, laying the foundation for future research in this critical area. We discuss the implications for developing sustainable AI solutions and standardizing energy efficiency benchmarking for ML systems.
Dynamic Network selection for the Object Detection task: why it matters and what we (didn't) achieve
May 27, 2021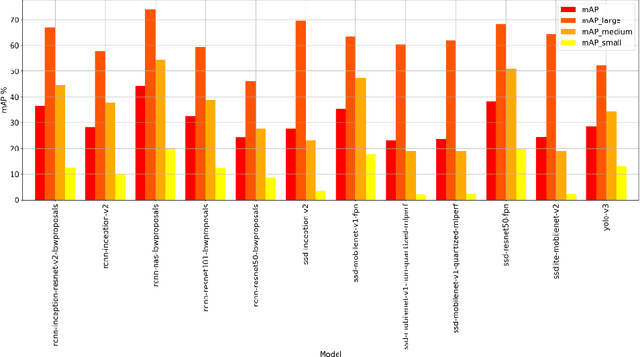

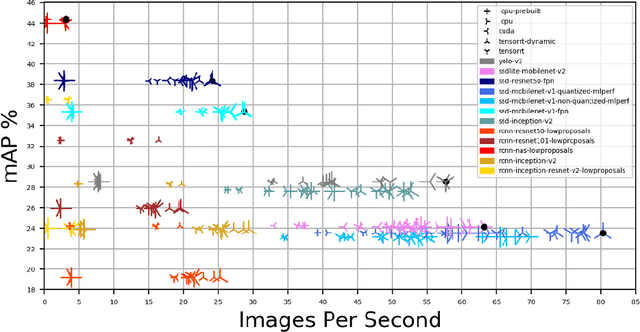

In this paper, we want to show the potential benefit of a dynamic auto-tuning approach for the inference process in the Deep Neural Network (DNN) context, tackling the object detection challenge. We benchmarked different neural networks to find the optimal detector for the well-known COCO 17 database, and we demonstrate that even if we only consider the quality of the prediction there is not a single optimal network. This is even more evident if we also consider the time to solution as a metric to evaluate, and then select, the most suitable network. This opens to the possibility for an adaptive methodology to switch among different object detection networks according to run-time requirements (e.g. maximum quality subject to a time-to-solution constraint). Moreover, we demonstrated by developing an ad hoc oracle, that an additional proactive methodology could provide even greater benefits, allowing us to select the best network among the available ones given some characteristics of the processed image. To exploit this method, we need to identify some image features that can be used to steer the decision on the most promising network. Despite the optimization opportunity that has been identified, we were not able to identify a predictor function that validates this attempt neither adopting classical image features nor by using a DNN classifier.
Benchmarking TinyML Systems: Challenges and Direction
Mar 10, 2020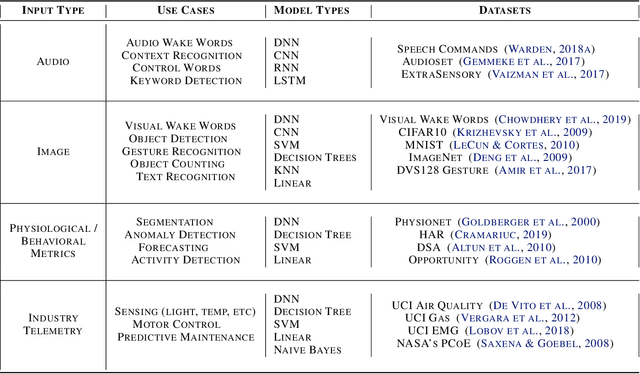
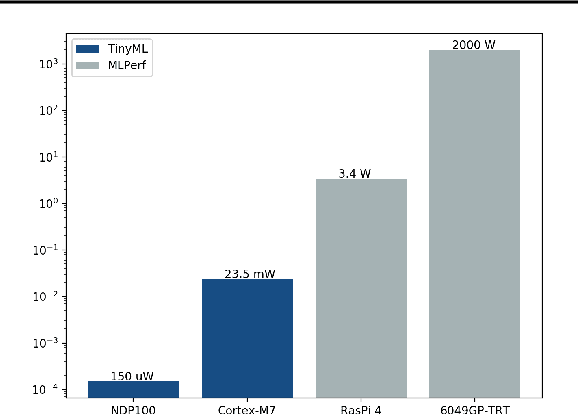
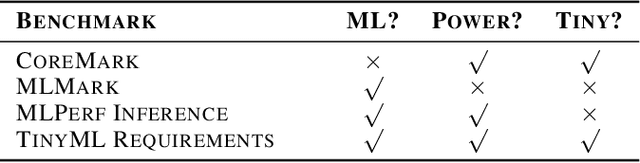
Recent advancements in ultra-low-power machine learning (TinyML) hardware promises to unlock an entirely new class of smart applications. However, continued progress is limited by the lack of a widely accepted benchmark for these systems. Benchmarking allows us to measure and thereby systematically compare, evaluate, and improve the performance of systems. In this position paper, we present the current landscape of TinyML and discuss the challenges and direction towards developing a fair and useful hardware benchmark for TinyML workloads. Our viewpoints reflect the collective thoughts of the TinyMLPerf working group that is comprised of 30 organizations.
MLPerf Inference Benchmark
Nov 06, 2019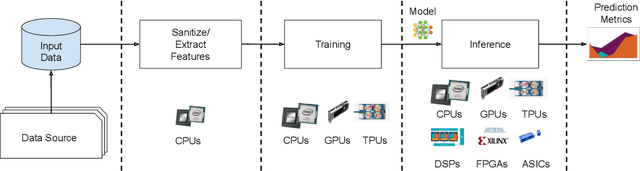
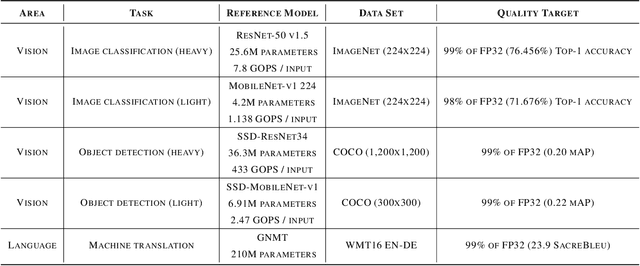
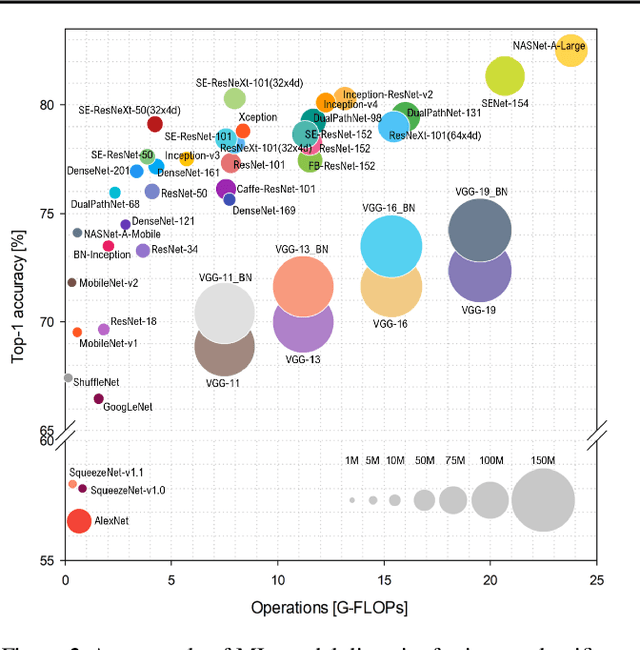
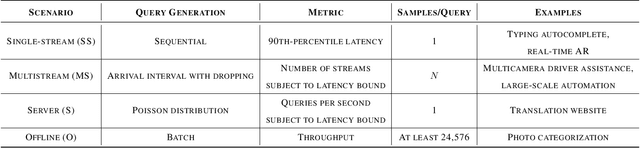
Machine-learning (ML) hardware and software system demand is burgeoning. Driven by ML applications, the number of different ML inference systems has exploded. Over 100 organizations are building ML inference chips, and the systems that incorporate existing models span at least three orders of magnitude in power consumption and four orders of magnitude in performance; they range from embedded devices to data-center solutions. Fueling the hardware are a dozen or more software frameworks and libraries. The myriad combinations of ML hardware and ML software make assessing ML-system performance in an architecture-neutral, representative, and reproducible manner challenging. There is a clear need for industry-wide standard ML benchmarking and evaluation criteria. MLPerf Inference answers that call. Driven by more than 30 organizations as well as more than 200 ML engineers and practitioners, MLPerf implements a set of rules and practices to ensure comparability across systems with wildly differing architectures. In this paper, we present the method and design principles of the initial MLPerf Inference release. The first call for submissions garnered more than 600 inference-performance measurements from 14 organizations, representing over 30 systems that show a range of capabilities.
Introducing ReQuEST: an Open Platform for Reproducible and Quality-Efficient Systems-ML Tournaments
Jan 19, 2018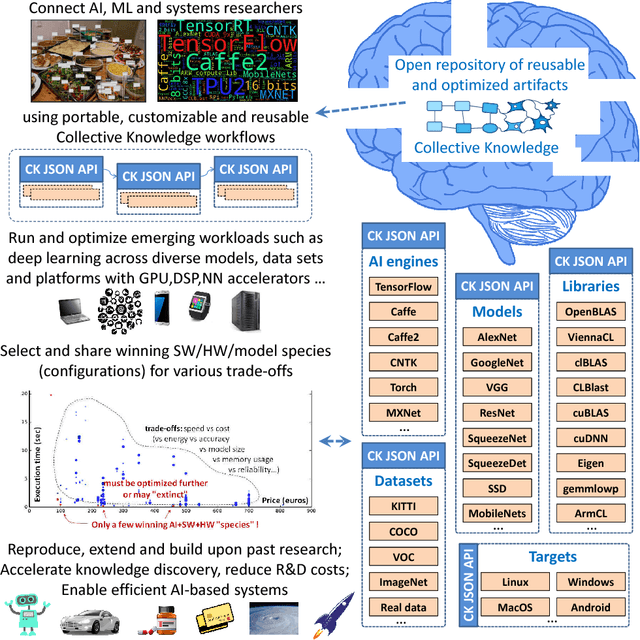
Co-designing efficient machine learning based systems across the whole hardware/software stack to trade off speed, accuracy, energy and costs is becoming extremely complex and time consuming. Researchers often struggle to evaluate and compare different published works across rapidly evolving software frameworks, heterogeneous hardware platforms, compilers, libraries, algorithms, data sets, models, and environments. We present our community effort to develop an open co-design tournament platform with an online public scoreboard. It will gradually incorporate best research practices while providing a common way for multidisciplinary researchers to optimize and compare the quality vs. efficiency Pareto optimality of various workloads on diverse and complete hardware/software systems. We want to leverage the open-source Collective Knowledge framework and the ACM artifact evaluation methodology to validate and share the complete machine learning system implementations in a standardized, portable, and reproducible fashion. We plan to hold regular multi-objective optimization and co-design tournaments for emerging workloads such as deep learning, starting with ASPLOS'18 (ACM conference on Architectural Support for Programming Languages and Operating Systems - the premier forum for multidisciplinary systems research spanning computer architecture and hardware, programming languages and compilers, operating systems and networking) to build a public repository of the most efficient machine learning algorithms and systems which can be easily customized, reused and built upon.
Collective Mind, Part II: Towards Performance- and Cost-Aware Software Engineering as a Natural Science
Jun 20, 2015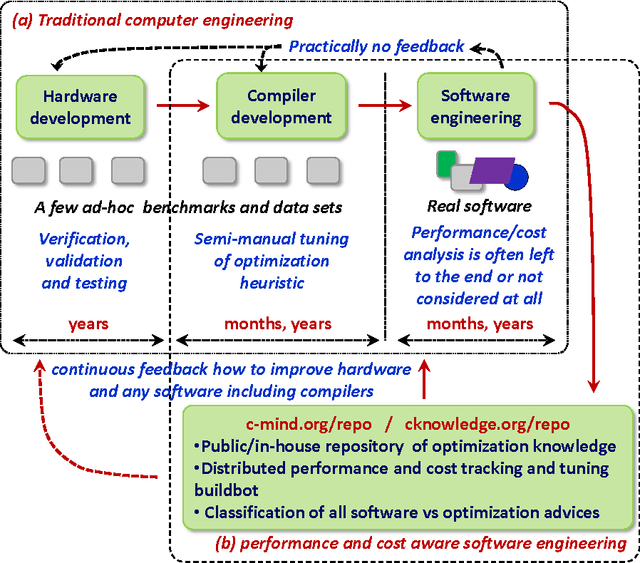


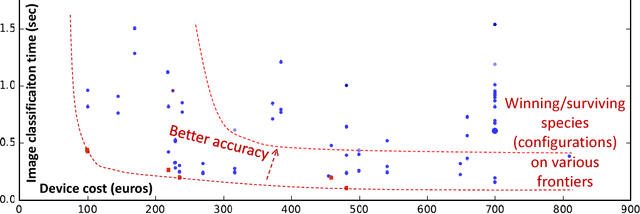
Nowadays, engineers have to develop software often without even knowing which hardware it will eventually run on in numerous mobile phones, tablets, desktops, laptops, data centers, supercomputers and cloud services. Unfortunately, optimizing compilers are not keeping pace with ever increasing complexity of computer systems anymore and may produce severely underperforming executable codes while wasting expensive resources and energy. We present our practical and collaborative solution to this problem via light-weight wrappers around any software piece when more than one implementation or optimization choice available. These wrappers are connected with a public Collective Mind autotuning infrastructure and repository of knowledge (c-mind.org/repo) to continuously monitor various important characteristics of these pieces (computational species) across numerous existing hardware configurations together with randomly selected optimizations. Similar to natural sciences, we can now continuously track winning solutions (optimizations for a given hardware) that minimize all costs of a computation (execution time, energy spent, code size, failures, memory and storage footprint, optimization time, faults, contentions, inaccuracy and so on) of a given species on a Pareto frontier along with any unexpected behavior. The community can then collaboratively classify solutions, prune redundant ones, and correlate them with various features of software, its inputs (data sets) and used hardware either manually or using powerful predictive analytics techniques. Our approach can then help create a large, realistic, diverse, representative, and continuously evolving benchmark with related optimization knowledge while gradually covering all possible software and hardware to be able to predict best optimizations and improve compilers and hardware depending on usage scenarios and requirements.
Proceedings of the DATE Friday Workshop on Heterogeneous Architectures and Design Methods for Embedded Image Systems
Feb 26, 2015This volume contains the papers accepted at the DATE Friday Workshop on Heterogeneous Architectures and Design Methods for Embedded Image Systems (HIS 2015), held in Grenoble, France, March 13, 2015. HIS 2015 was co-located with the Conference on Design, Automation and Test in Europe (DATE).