 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollective Mind, Part II: Towards Performance- and Cost-Aware Software Engineering as a Natural Science
Paper and Code
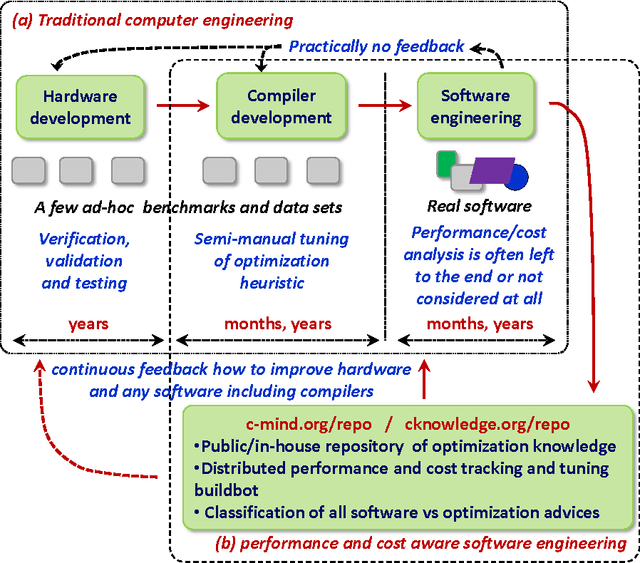


Nowadays, engineers have to develop software often without even knowing which hardware it will eventually run on in numerous mobile phones, tablets, desktops, laptops, data centers, supercomputers and cloud services. Unfortunately, optimizing compilers are not keeping pace with ever increasing complexity of computer systems anymore and may produce severely underperforming executable codes while wasting expensive resources and energy. We present our practical and collaborative solution to this problem via light-weight wrappers around any software piece when more than one implementation or optimization choice available. These wrappers are connected with a public Collective Mind autotuning infrastructure and repository of knowledge (c-mind.org/repo) to continuously monitor various important characteristics of these pieces (computational species) across numerous existing hardware configurations together with randomly selected optimizations. Similar to natural sciences, we can now continuously track winning solutions (optimizations for a given hardware) that minimize all costs of a computation (execution time, energy spent, code size, failures, memory and storage footprint, optimization time, faults, contentions, inaccuracy and so on) of a given species on a Pareto frontier along with any unexpected behavior. The community can then collaboratively classify solutions, prune redundant ones, and correlate them with various features of software, its inputs (data sets) and used hardware either manually or using powerful predictive analytics techniques. Our approach can then help create a large, realistic, diverse, representative, and continuously evolving benchmark with related optimization knowledge while gradually covering all possible software and hardware to be able to predict best optimizations and improve compilers and hardware depending on usage scenarios and requirements.