 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Neural Nonlinearity as Gating
Jul 03, 2026Activation functions are considered an essential primitive for neural nonlinearity, i.e., they enable neural networks to serve as universal approximators. In this paper, we show that this nonlinearity can also be achieved by input-conditioned threshold gating through branches as a universal primitive. We demonstrate that standard activations -- whether piecewise-linear (ReLU, PReLU, Hardtanh) or smooth (SiLU, Sigmoid, Tanh, GELU) -- are in fact instances of a single Threshold Gating (TG) primitive. For softmax, we show that it admits an exact TG conversion via its equivalent per-element Sigmoid form. We then validate these equivalences by converting pretrained networks across CNNs, transformer-based models, and recurrent architectures, preserving model performance without requiring retraining. Threshold Gating also enables training from scratch that goes beyond replacing existing activations, enabling gains in model compression, performance, and shorter training. We also propose a 'Minimal Branch Theorem' which relates the minimum number of required branches in our primitive to the trainability of general deep neural networks. In terms of hardware implementation, TG maps to a unified implementation in the case of analog in-memory systems, addressing the bottleneck of analog-to-digital and digital-to-analog converters (ADC/DAC) that is known to significantly impact power consumption and on-chip area.
Hardware/Software Co-Design of RISC-V Extensions for Accelerating Sparse DNNs on FPGAs
Apr 28, 2025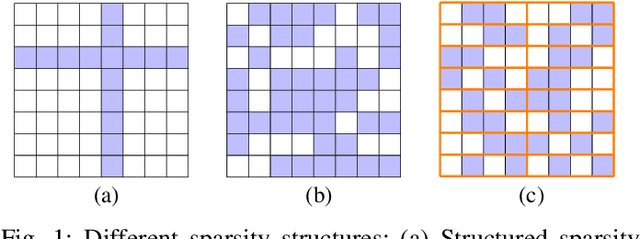
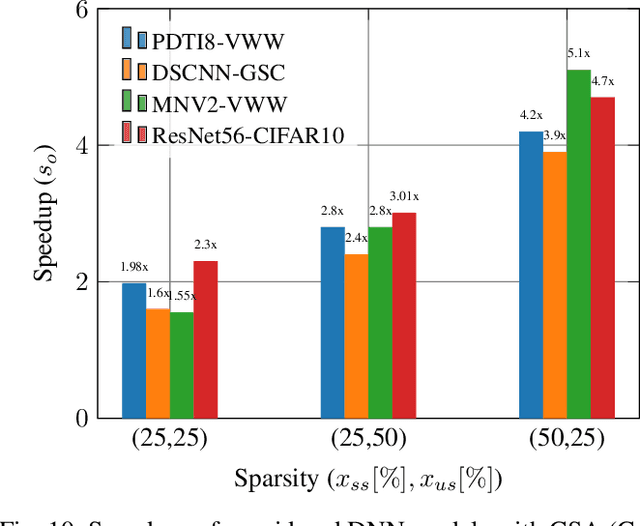
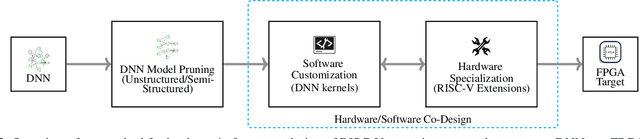
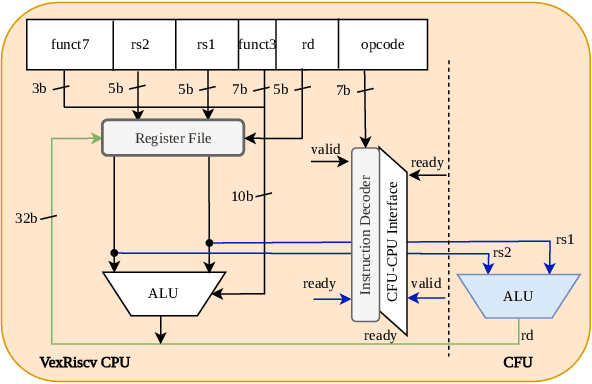
The customizability of RISC-V makes it an attractive choice for accelerating deep neural networks (DNNs). It can be achieved through instruction set extensions and corresponding custom functional units. Yet, efficiently exploiting these opportunities requires a hardware/software co-design approach in which the DNN model, software, and hardware are designed together. In this paper, we propose novel RISC-V extensions for accelerating DNN models containing semi-structured and unstructured sparsity. While the idea of accelerating structured and unstructured pruning is not new, our novel design offers various advantages over other designs. To exploit semi-structured sparsity, we take advantage of the fine-grained (bit-level) configurability of FPGAs and suggest reserving a few bits in a block of DNN weights to encode the information about sparsity in the succeeding blocks. The proposed custom functional unit utilizes this information to skip computations. To exploit unstructured sparsity, we propose a variable cycle sequential multiply-and-accumulate unit that performs only as many multiplications as the non-zero weights. Our implementation of unstructured and semi-structured pruning accelerators can provide speedups of up to a factor of 3 and 4, respectively. We then propose a combined design that can accelerate both types of sparsities, providing speedups of up to a factor of 5. Our designs consume a small amount of additional FPGA resources such that the resulting co-designs enable the acceleration of DNNs even on small FPGAs. We benchmark our designs on standard TinyML applications such as keyword spotting, image classification, and person detection.
microYOLO: Towards Single-Shot Object Detection on Microcontrollers
Aug 28, 2024This work-in-progress paper presents results on the feasibility of single-shot object detection on microcontrollers using YOLO. Single-shot object detectors like YOLO are widely used, however due to their complexity mainly on larger GPU-based platforms. We present microYOLO, which can be used on Cortex-M based microcontrollers, such as the OpenMV H7 R2, achieving about 3.5 FPS when classifying 128x128 RGB images while using less than 800 KB Flash and less than 350 KB RAM. Furthermore, we share experimental results for three different object detection tasks, analyzing the accuracy of microYOLO on them.
On-Device Training of Fully Quantized Deep Neural Networks on Cortex-M Microcontrollers
Jul 15, 2024On-device training of DNNs allows models to adapt and fine-tune to newly collected data or changing domains while deployed on microcontroller units (MCUs). However, DNN training is a resource-intensive task, making the implementation and execution of DNN training algorithms on MCUs challenging due to low processor speeds, constrained throughput, limited floating-point support, and memory constraints. In this work, we explore on-device training of DNNs for Cortex-M MCUs. We present a method that enables efficient training of DNNs completely in place on the MCU using fully quantized training (FQT) and dynamic partial gradient updates. We demonstrate the feasibility of our approach on multiple vision and time-series datasets and provide insights into the tradeoff between training accuracy, memory overhead, energy, and latency on real hardware.
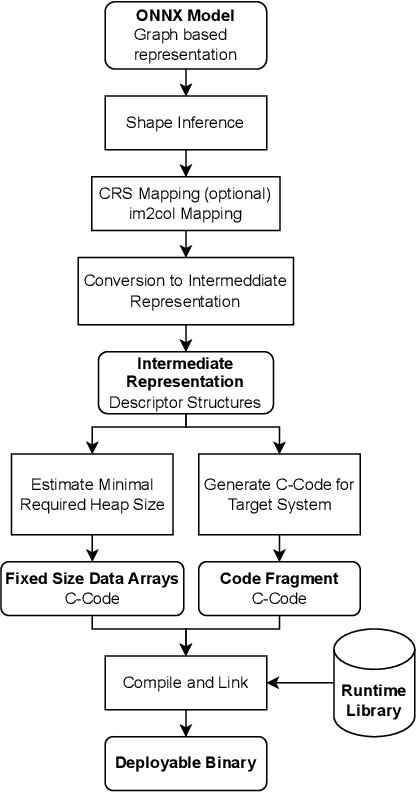
OpTC -- A Toolchain for Deployment of Neural Networks on AURIX TC3xx Microcontrollers
Apr 24, 2024The AURIX 2xx and 3xx families of TriCore microcontrollers are widely used in the automotive industry and, recently, also in applications that involve machine learning tasks. Yet, these applications are mainly engineered manually, and only little tool support exists for bringing neural networks to TriCore microcontrollers. Thus, we propose OpTC, an end-to-end toolchain for automatic compression, conversion, code generation, and deployment of neural networks on TC3xx microcontrollers. OpTC supports various types of neural networks and provides compression using layer-wise pruning based on sensitivity analysis for a given neural network. The flexibility in supporting different types of neural networks, such as multi-layer perceptrons (MLP), convolutional neural networks (CNN), and recurrent neural networks (RNN), is shown in case studies for a TC387 microcontroller. Automotive applications for predicting the temperature in electric motors and detecting anomalies are thereby used to demonstrate the effectiveness and the wide range of applications supported by OpTC.
To Spike or Not to Spike? A Quantitative Comparison of SNN and CNN FPGA Implementations
Jun 22, 2023Convolutional Neural Networks (CNNs) are widely employed to solve various problems, e.g., image classification. Due to their compute- and data-intensive nature, CNN accelerators have been developed as ASICs or on FPGAs. Increasing complexity of applications has caused resource costs and energy requirements of these accelerators to grow. Spiking Neural Networks (SNNs) are an emerging alternative to CNN implementations, promising higher resource and energy efficiency. The main research question addressed in this paper is whether SNN accelerators truly meet these expectations of reduced energy requirements compared to their CNN equivalents. For this purpose, we analyze multiple SNN hardware accelerators for FPGAs regarding performance and energy efficiency. We present a novel encoding scheme of spike event queues and a novel memory organization technique to improve SNN energy efficiency further. Both techniques have been integrated into a state-of-the-art SNN architecture and evaluated for MNIST, SVHN, and CIFAR-10 datasets and corresponding network architectures on two differently sized modern FPGA platforms. For small-scale benchmarks such as MNIST, SNN designs provide rather no or little latency and energy efficiency advantages over corresponding CNN implementations. For more complex benchmarks such as SVHN and CIFAR-10, the trend reverses.
Augmented Random Search for Multi-Objective Bayesian Optimization of Neural Networks
May 23, 2023Deploying Deep Neural Networks (DNNs) on tiny devices is a common trend to process the increasing amount of sensor data being generated. Multi-objective optimization approaches can be used to compress DNNs by applying network pruning and weight quantization to minimize the memory footprint (RAM), the number of parameters (ROM) and the number of floating point operations (FLOPs) while maintaining the predictive accuracy. In this paper, we show that existing multi-objective Bayesian optimization (MOBOpt) approaches can fall short in finding optimal candidates on the Pareto front and propose a novel solver based on an ensemble of competing parametric policies trained using an Augmented Random Search Reinforcement Learning (RL) agent. Our methodology aims at finding feasible tradeoffs between a DNN's predictive accuracy, memory consumption on a given target system, and computational complexity. Our experiments show that we outperform existing MOBOpt approaches consistently on different data sets and architectures such as ResNet-18 and MobileNetV3.
Deployment of Energy-Efficient Deep Learning Models on Cortex-M based Microcontrollers using Deep Compression
May 20, 2022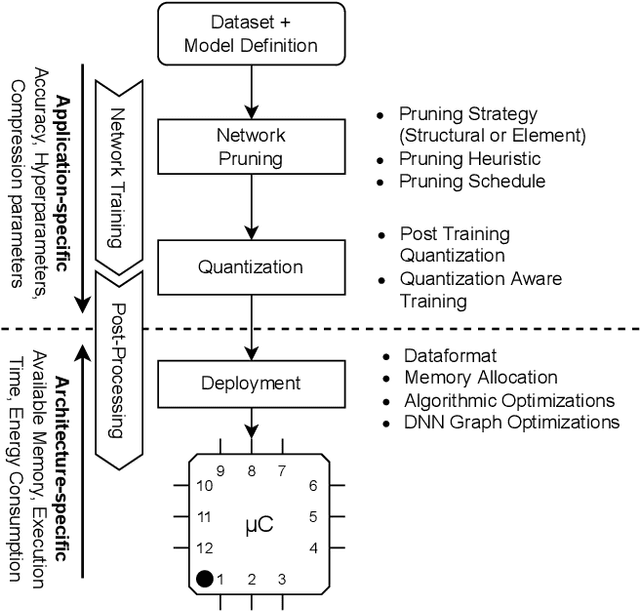

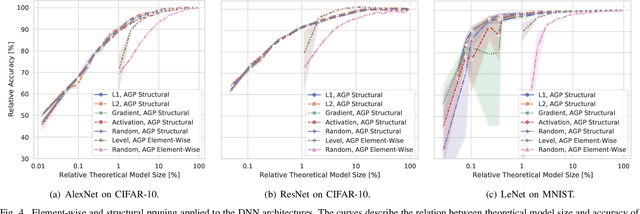
Large Deep Neural Networks (DNNs) are the backbone of today's artificial intelligence due to their ability to make accurate predictions when being trained on huge datasets. With advancing technologies, such as the Internet of Things, interpreting large quantities of data generated by sensors is becoming an increasingly important task. However, in many applications not only the predictive performance but also the energy consumption of deep learning models is of major interest. This paper investigates the efficient deployment of deep learning models on resource-constrained microcontroller architectures via network compression. We present a methodology for the systematic exploration of different DNN pruning, quantization, and deployment strategies, targeting different ARM Cortex-M based low-power systems. The exploration allows to analyze trade-offs between key metrics such as accuracy, memory consumption, execution time, and power consumption. We discuss experimental results on three different DNN architectures and show that we can compress them to below 10\% of their original parameter count before their predictive quality decreases. This also allows us to deploy and evaluate them on Cortex-M based microcontrollers.
Efficient Hardware Acceleration of Sparsely Active Convolutional Spiking Neural Networks
Mar 23, 2022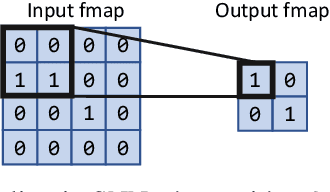
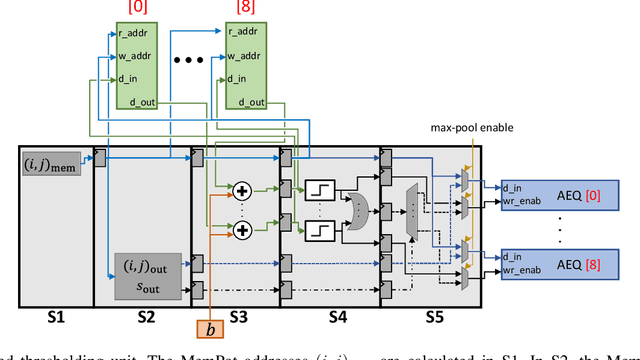
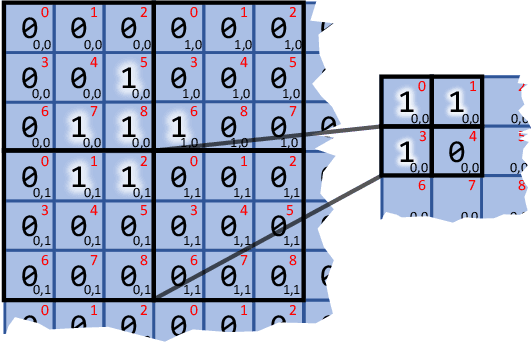
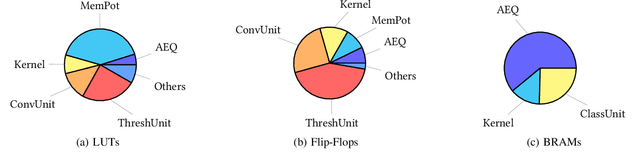
Spiking Neural Networks (SNNs) compute in an event-based matter to achieve a more efficient computation than standard Neural Networks. In SNNs, neuronal outputs (i.e. activations) are not encoded with real-valued activations but with sequences of binary spikes. The motivation of using SNNs over conventional neural networks is rooted in the special computational aspects of SNNs, especially the very high degree of sparsity of neural output activations. Well established architectures for conventional Convolutional Neural Networks (CNNs) feature large spatial arrays of Processing Elements (PEs) that remain highly underutilized in the face of activation sparsity. We propose a novel architecture that is optimized for the processing of Convolutional SNNs (CSNNs) that feature a high degree of activation sparsity. In our architecture, the main strategy is to use less but highly utilized PEs. The PE array used to perform the convolution is only as large as the kernel size, allowing all PEs to be active as long as there are spikes to process. This constant flow of spikes is ensured by compressing the feature maps (i.e. the activations) into queues that can then be processed spike by spike. This compression is performed in run-time using dedicated circuitry, leading to a self-timed scheduling. This allows the processing time to scale directly with the number of spikes. A novel memory organization scheme called memory interlacing is used to efficiently store and retrieve the membrane potentials of the individual neurons using multiple small parallel on-chip RAMs. Each RAM is hardwired to its PE, reducing switching circuitry and allowing RAMs to be located in close proximity to the respective PE. We implemented the proposed architecture on an FPGA and achieved a significant speedup compared to other implementations while needing less hardware resources and maintaining a lower energy consumption.
Multi-Objective Design Space Exploration for the Optimization of the HEVC Mode Decision Process
Mar 03, 2022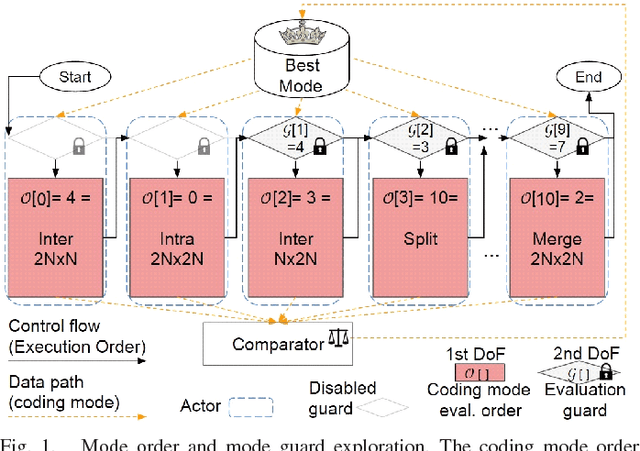


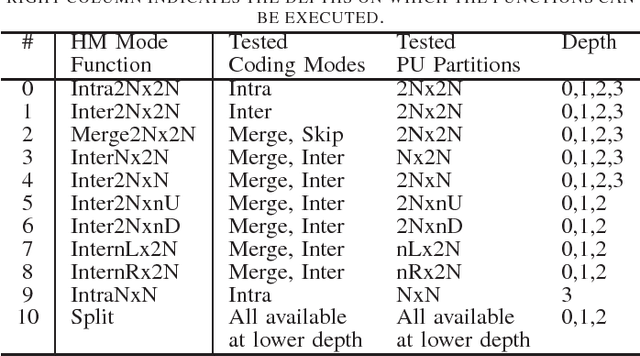
Finding the best possible encoding decisions for compressing a video sequence is a highly complex problem. In this work, we propose a multi-objective Design Space Exploration (DSE) method to automatically find HEVC encoder implementations that are optimized for several different criteria. The DSE shall optimize the coding mode evaluation order of the mode decision process and jointly explore early skip conditions to minimize the four objectives a) bitrate, b) distortion, c) encoding time, and d) decoding energy. In this context, we use a SystemC-based actor model of the HM test model encoder for the evaluation of each explored solution. The evaluation that is based on real measurements shows that our framework can automatically generate encoder solutions that save more than 60% of encoding time or 3% of decoding energy when accepting bitrate increases of around 3%.