 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition Paper: Rethinking AI/ML for Air Interface in Wireless Networks
Jun 13, 2025AI/ML research has predominantly been driven by domains such as computer vision, natural language processing, and video analysis. In contrast, the application of AI/ML to wireless networks, particularly at the air interface, remains in its early stages. Although there are emerging efforts to explore this intersection, fully realizing the potential of AI/ML in wireless communications requires a deep interdisciplinary understanding of both fields. We provide an overview of AI/ML-related discussions in 3GPP standardization, highlighting key use cases, architectural considerations, and technical requirements. We outline open research challenges and opportunities where academic and industrial communities can contribute to shaping the future of AI-enabled wireless systems.
Benchmarking Quantum Reinforcement Learning
Jan 27, 2025Benchmarking and establishing proper statistical validation metrics for reinforcement learning (RL) remain ongoing challenges, where no consensus has been established yet. The emergence of quantum computing and its potential applications in quantum reinforcement learning (QRL) further complicate benchmarking efforts. To enable valid performance comparisons and to streamline current research in this area, we propose a novel benchmarking methodology, which is based on a statistical estimator for sample complexity and a definition of statistical outperformance. Furthermore, considering QRL, our methodology casts doubt on some previous claims regarding its superiority. We conducted experiments on a novel benchmarking environment with flexible levels of complexity. While we still identify possible advantages, our findings are more nuanced overall. We discuss the potential limitations of these results and explore their implications for empirical research on quantum advantage in QRL.
C-MCTS: Safe Planning with Monte Carlo Tree Search
May 25, 2023Many real-world decision-making tasks, such as safety-critical scenarios, cannot be fully described in a single-objective setting using the Markov Decision Process (MDP) framework, as they include hard constraints. These can instead be modeled with additional cost functions within the Constrained Markov Decision Process (CMDP) framework. Even though CMDPs have been extensively studied in the Reinforcement Learning literature, little attention has been given to sampling-based planning algorithms such as MCTS for solving them. Previous approaches use Monte Carlo cost estimates to avoid constraint violations. However, these suffer from high variance which results in conservative performance with respect to costs. We propose Constrained MCTS (C-MCTS), an algorithm that estimates cost using a safety critic. The safety critic training is based on Temporal Difference learning in an offline phase prior to agent deployment. This critic limits the exploration of the search tree and removes unsafe trajectories within MCTS during deployment. C-MCTS satisfies cost constraints but operates closer to the constraint boundary, achieving higher rewards compared to previous work. As a nice byproduct, the planner is more efficient requiring fewer planning steps. Most importantly, we show that under model mismatch between the planner and the real world, our approach is less susceptible to cost violations than previous work.
Augmented Random Search for Multi-Objective Bayesian Optimization of Neural Networks
May 23, 2023Deploying Deep Neural Networks (DNNs) on tiny devices is a common trend to process the increasing amount of sensor data being generated. Multi-objective optimization approaches can be used to compress DNNs by applying network pruning and weight quantization to minimize the memory footprint (RAM), the number of parameters (ROM) and the number of floating point operations (FLOPs) while maintaining the predictive accuracy. In this paper, we show that existing multi-objective Bayesian optimization (MOBOpt) approaches can fall short in finding optimal candidates on the Pareto front and propose a novel solver based on an ensemble of competing parametric policies trained using an Augmented Random Search Reinforcement Learning (RL) agent. Our methodology aims at finding feasible tradeoffs between a DNN's predictive accuracy, memory consumption on a given target system, and computational complexity. Our experiments show that we outperform existing MOBOpt approaches consistently on different data sets and architectures such as ResNet-18 and MobileNetV3.
Efficient Beam Search for Initial Access Using Collaborative Filtering
Sep 14, 2022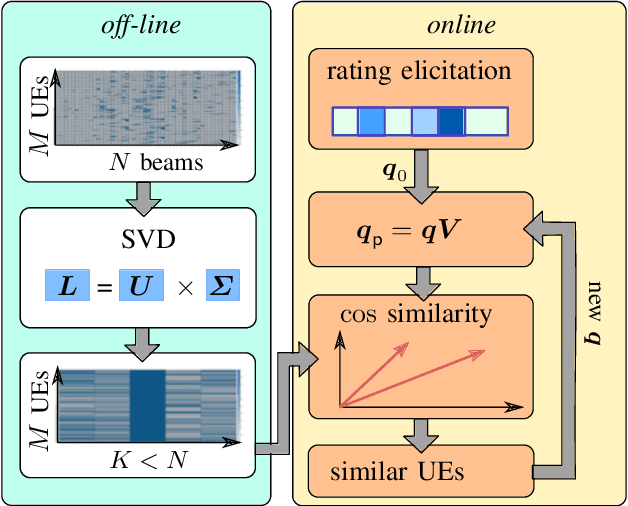
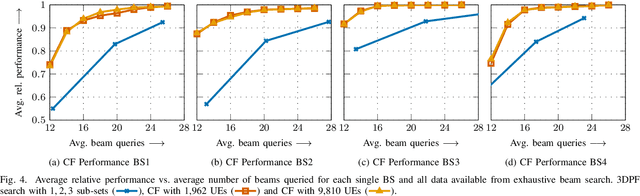
Beamforming-capable antenna arrays overcome the high free-space path loss at higher carrier frequencies. However, the beams must be properly aligned to ensure that the highest power is radiated towards (and received by) the user equipment (UE). While there are methods that improve upon an exhaustive search for optimal beams by some form of hierarchical search, they can be prone to return only locally optimal solutions with small beam gains. Other approaches address this problem by exploiting contextual information, e.g., the position of the UE or information from neighboring base stations (BS), but the burden of computing and communicating this additional information can be high. Methods based on machine learning so far suffer from the accompanying training, performance monitoring and deployment complexity that hinders their application at scale. This paper proposes a novel method for solving the initial beam-discovery problem. It is scalable, and easy to tune and to implement. Our algorithm is based on a recommender system that associates groups (i.e., UEs) and preferences (i.e., beams from a codebook) based on a training data set. Whenever a new UE needs to be served our algorithm returns the best beams in this user cluster. Our simulation results demonstrate the efficiency and robustness of our approach, not only in single BS setups but also in setups that require a coordination among several BSs. Our method consistently outperforms standard baseline algorithms in the given task.
Driver Dojo: A Benchmark for Generalizable Reinforcement Learning for Autonomous Driving
Jul 23, 2022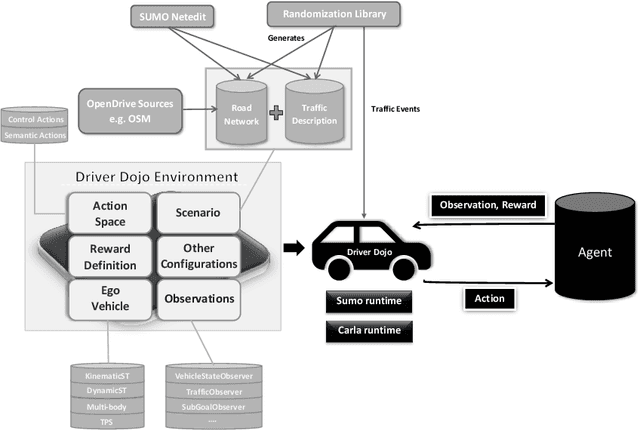


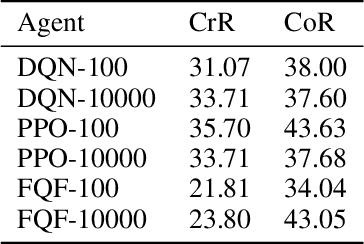
Reinforcement learning (RL) has shown to reach super human-level performance across a wide range of tasks. However, unlike supervised machine learning, learning strategies that generalize well to a wide range of situations remains one of the most challenging problems for real-world RL. Autonomous driving (AD) provides a multi-faceted experimental field, as it is necessary to learn the correct behavior over many variations of road layouts and large distributions of possible traffic situations, including individual driver personalities and hard-to-predict traffic events. In this paper we propose a challenging benchmark for generalizable RL for AD based on a configurable, flexible, and performant code base. Our benchmark uses a catalog of randomized scenario generators, including multiple mechanisms for road layout and traffic variations, different numerical and visual observation types, distinct action spaces, diverse vehicle models, and allows for use under static scenario definitions. In addition to purely algorithmic insights, our application-oriented benchmark also enables a better understanding of the impact of design decisions such as action and observation space on the generalizability of policies. Our benchmark aims to encourage researchers to propose solutions that are able to successfully generalize across scenarios, a task in which current RL methods fail. The code for the benchmark is available at https://github.com/seawee1/driver-dojo.