 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriver Dojo: A Benchmark for Generalizable Reinforcement Learning for Autonomous Driving
Jul 23, 2022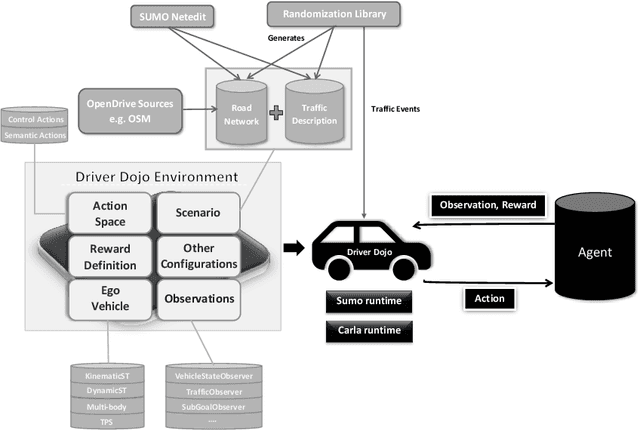


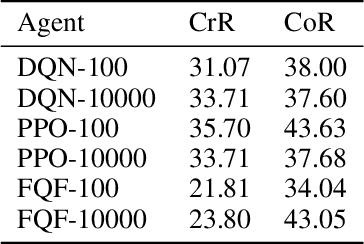
Reinforcement learning (RL) has shown to reach super human-level performance across a wide range of tasks. However, unlike supervised machine learning, learning strategies that generalize well to a wide range of situations remains one of the most challenging problems for real-world RL. Autonomous driving (AD) provides a multi-faceted experimental field, as it is necessary to learn the correct behavior over many variations of road layouts and large distributions of possible traffic situations, including individual driver personalities and hard-to-predict traffic events. In this paper we propose a challenging benchmark for generalizable RL for AD based on a configurable, flexible, and performant code base. Our benchmark uses a catalog of randomized scenario generators, including multiple mechanisms for road layout and traffic variations, different numerical and visual observation types, distinct action spaces, diverse vehicle models, and allows for use under static scenario definitions. In addition to purely algorithmic insights, our application-oriented benchmark also enables a better understanding of the impact of design decisions such as action and observation space on the generalizability of policies. Our benchmark aims to encourage researchers to propose solutions that are able to successfully generalize across scenarios, a task in which current RL methods fail. The code for the benchmark is available at https://github.com/seawee1/driver-dojo.
How to Learn from Risk: Explicit Risk-Utility Reinforcement Learning for Efficient and Safe Driving Strategies
Mar 16, 2022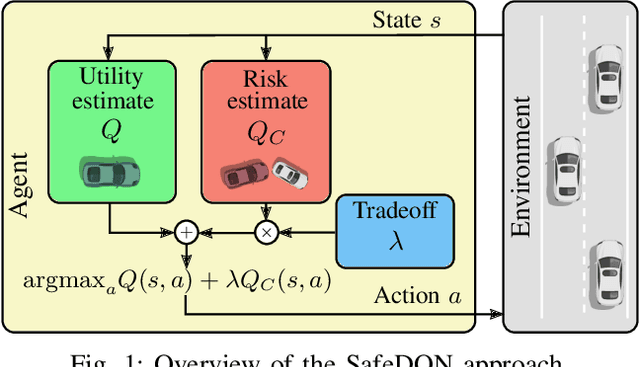
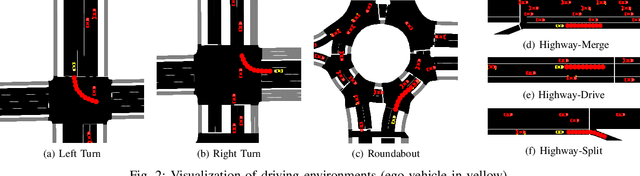
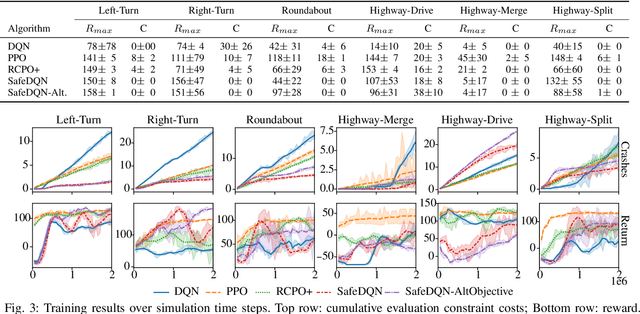
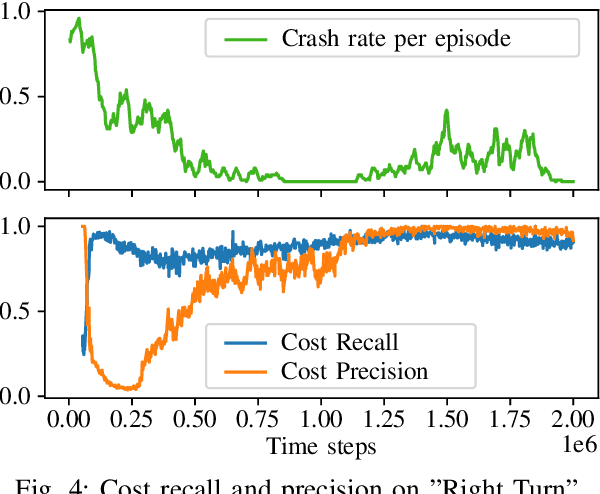
Autonomous driving has the potential to revolutionize mobility and is hence an active area of research. In practice, the behavior of autonomous vehicles must be acceptable, i.e., efficient, safe, and interpretable. While vanilla reinforcement learning (RL) finds performant behavioral strategies, they are often unsafe and uninterpretable. Safety is introduced through Safe RL approaches, but they still mostly remain uninterpretable as the learned behaviour is jointly optimized for safety and performance without modeling them separately. Interpretable machine learning is rarely applied to RL. This paper proposes SafeDQN, which allows to make the behavior of autonomous vehicles safe and interpretable while still being efficient. SafeDQN offers an understandable, semantic trade-off between the expected risk and the utility of actions while being algorithmically transparent. We show that SafeDQN finds interpretable and safe driving policies for a variety of scenarios and demonstrate how state-of-the-art saliency techniques can help to assess both risk and utility.