 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrototypeNAS: Rapid Design of Deep Neural Networks for Microcontroller Units
Mar 16, 2026Enabling efficient deep neural network (DNN) inference on edge devices with different hardware constraints is a challenging task that typically requires DNN architectures to be specialized for each device separately. To avoid the huge manual effort, one can use neural architecture search (NAS). However, many existing NAS methods are resource-intensive and time-consuming because they require the training of many different DNNs from scratch. Furthermore, they do not take the resource constraints of the target system into account. To address these shortcomings, we propose PrototypeNAS, a zero-shot NAS method to accelerate and automate the selection, compression, and specialization of DNNs to different target microcontroller units (MCUs). We propose a novel three-step search method that decouples DNN design and specialization from DNN training for a given target platform. First, we present a novel search space that not only cuts out smaller DNNs from a single large architecture, but instead combines the structural optimization of multiple architecture types, as well as optimization of their pruning and quantization configurations. Second, we explore the use of an ensemble of zero-shot proxies during optimization instead of a single one. Third, we propose the use of Hypervolume subset selection to distill DNN architectures from the Pareto front of the multi-objective optimization that represent the most meaningful tradeoffs between accuracy and FLOPs. We evaluate the effectiveness of PrototypeNAS on 12 different datasets in three different tasks: image classification, time series classification, and object detection. Our results demonstrate that PrototypeNAS is able to identify DNN models within minutes that are small enough to be deployed on off-the-shelf MCUs and still achieve accuracies comparable to the performance of large DNN models.
Pareto Optimal Benchmarking of AI Models on ARM Cortex Processors for Sustainable Embedded Systems
Feb 19, 2026This work presents a practical benchmarking framework for optimizing artificial intelligence (AI) models on ARM Cortex processors (M0+, M4, M7), focusing on energy efficiency, accuracy, and resource utilization in embedded systems. Through the design of an automated test bench, we provide a systematic approach to evaluate across key performance indicators (KPIs) and identify optimal combinations of processor and AI model. The research highlights a nearlinear correlation between floating-point operations (FLOPs) and inference time, offering a reliable metric for estimating computational demands. Using Pareto analysis, we demonstrate how to balance trade-offs between energy consumption and model accuracy, ensuring that AI applications meet performance requirements without compromising sustainability. Key findings indicate that the M7 processor is ideal for short inference cycles, while the M4 processor offers better energy efficiency for longer inference tasks. The M0+ processor, while less efficient for complex AI models, remains suitable for simpler tasks. This work provides insights for developers, guiding them to design energy-efficient AI systems that deliver high performance in realworld applications.
* 11 pages, 7 figures, Funding: GreenICT@FMD (BMFTR grant 16ME0491K)
Optimizing Quantum Circuits via ZX Diagrams using Reinforcement Learning and Graph Neural Networks
Apr 04, 2025



Quantum computing is currently strongly limited by the impact of noise, in particular introduced by the application of two-qubit gates. For this reason, reducing the number of two-qubit gates is of paramount importance on noisy intermediate-scale quantum hardware. To advance towards more reliable quantum computing, we introduce a framework based on ZX calculus, graph-neural networks and reinforcement learning for quantum circuit optimization. By combining reinforcement learning and tree search, our method addresses the challenge of selecting optimal sequences of ZX calculus rewrite rules. Instead of relying on existing heuristic rules for minimizing circuits, our method trains a novel reinforcement learning policy that directly operates on ZX-graphs, therefore allowing us to search through the space of all possible circuit transformations to find a circuit significantly minimizing the number of CNOT gates. This way we can scale beyond hard-coded rules towards discovering arbitrary optimization rules. We demonstrate our method's competetiveness with state-of-the-art circuit optimizers and generalization capabilities on large sets of diverse random circuits.
Guided-SPSA: Simultaneous Perturbation Stochastic Approximation assisted by the Parameter Shift Rule
Apr 24, 2024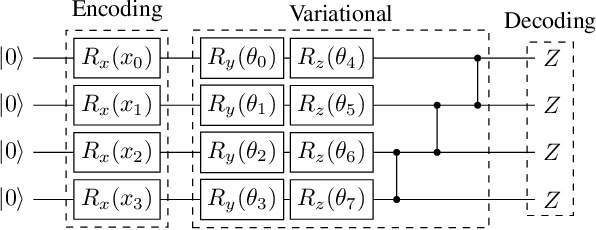
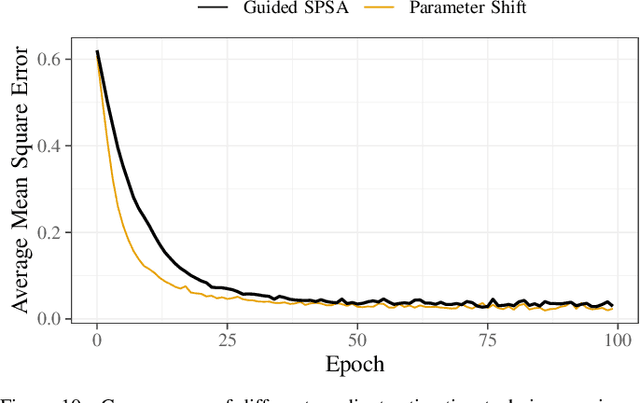
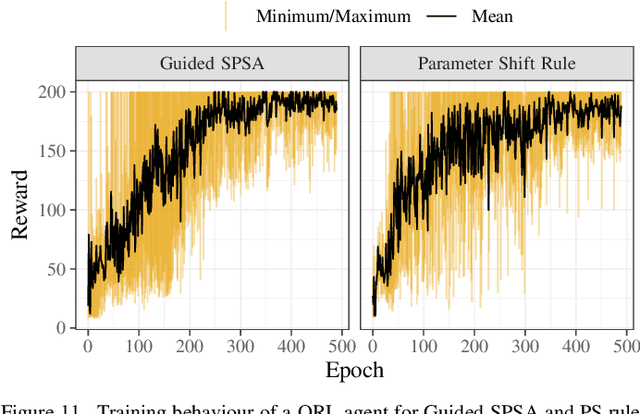

The study of variational quantum algorithms (VQCs) has received significant attention from the quantum computing community in recent years. These hybrid algorithms, utilizing both classical and quantum components, are well-suited for noisy intermediate-scale quantum devices. Though estimating exact gradients using the parameter-shift rule to optimize the VQCs is realizable in NISQ devices, they do not scale well for larger problem sizes. The computational complexity, in terms of the number of circuit evaluations required for gradient estimation by the parameter-shift rule, scales linearly with the number of parameters in VQCs. On the other hand, techniques that approximate the gradients of the VQCs, such as the simultaneous perturbation stochastic approximation (SPSA), do not scale with the number of parameters but struggle with instability and often attain suboptimal solutions. In this work, we introduce a novel gradient estimation approach called Guided-SPSA, which meaningfully combines the parameter-shift rule and SPSA-based gradient approximation. The Guided-SPSA results in a 15% to 25% reduction in the number of circuit evaluations required during training for a similar or better optimality of the solution found compared to the parameter-shift rule. The Guided-SPSA outperforms standard SPSA in all scenarios and outperforms the parameter-shift rule in scenarios such as suboptimal initialization of the parameters. We demonstrate numerically the performance of Guided-SPSA on different paradigms of quantum machine learning, such as regression, classification, and reinforcement learning.
Warm-Start Variational Quantum Policy Iteration
Apr 16, 2024



Reinforcement learning is a powerful framework aiming to determine optimal behavior in highly complex decision-making scenarios. This objective can be achieved using policy iteration, which requires to solve a typically large linear system of equations. We propose the variational quantum policy iteration (VarQPI) algorithm, realizing this step with a NISQ-compatible quantum-enhanced subroutine. Its scalability is supported by an analysis of the structure of generic reinforcement learning environments, laying the foundation for potential quantum advantage with utility-scale quantum computers. Furthermore, we introduce the warm-start initialization variant (WS-VarQPI) that significantly reduces resource overhead. The algorithm solves a large FrozenLake environment with an underlying 256x256-dimensional linear system, indicating its practical robustness.
Comprehensive Library of Variational LSE Solvers
Apr 15, 2024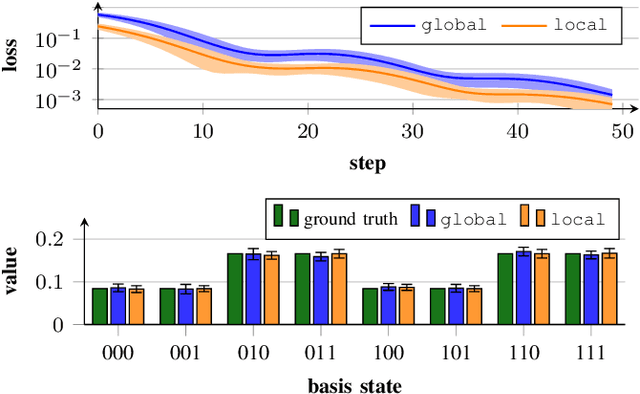


Linear systems of equations can be found in various mathematical domains, as well as in the field of machine learning. By employing noisy intermediate-scale quantum devices, variational solvers promise to accelerate finding solutions for large systems. Although there is a wealth of theoretical research on these algorithms, only fragmentary implementations exist. To fill this gap, we have developed the variational-lse-solver framework, which realizes existing approaches in literature, and introduces several enhancements. The user-friendly interface is designed for researchers that work at the abstraction level of identifying and developing end-to-end applications.
Qiskit-Torch-Module: Fast Prototyping of Quantum Neural Networks
Apr 09, 2024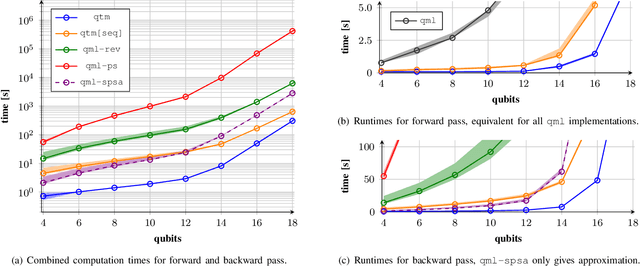
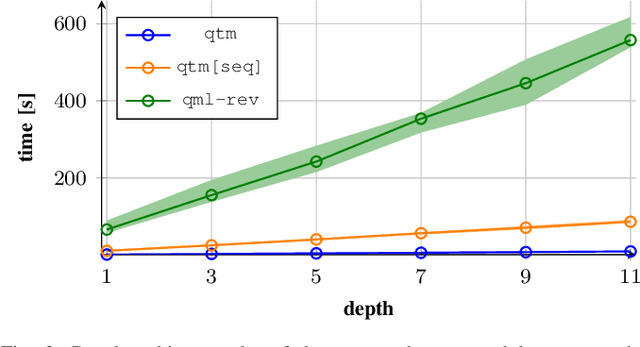
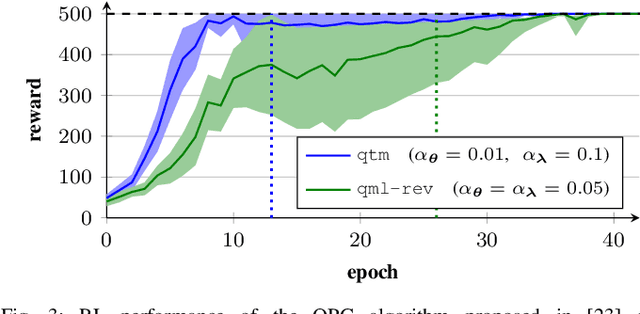
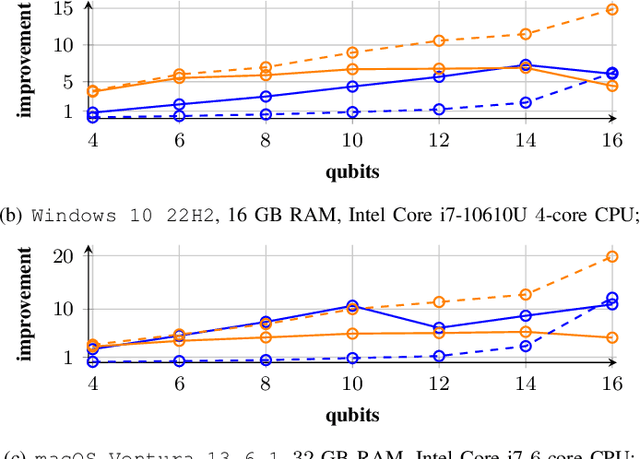
Quantum computer simulation software is an integral tool for the research efforts in the quantum computing community. An important aspect is the efficiency of respective frameworks, especially for training variational quantum algorithms. Focusing on the widely used Qiskit software environment, we develop the qiskit-torch-module. It improves runtime performance by two orders of magnitude over comparable libraries, while facilitating low-overhead integration with existing codebases. Moreover, the framework provides advanced tools for integrating quantum neural networks with PyTorch. The pipeline is tailored for single-machine compute systems, which constitute a widely employed setup in day-to-day research efforts.
C-MCTS: Safe Planning with Monte Carlo Tree Search
May 25, 2023



Many real-world decision-making tasks, such as safety-critical scenarios, cannot be fully described in a single-objective setting using the Markov Decision Process (MDP) framework, as they include hard constraints. These can instead be modeled with additional cost functions within the Constrained Markov Decision Process (CMDP) framework. Even though CMDPs have been extensively studied in the Reinforcement Learning literature, little attention has been given to sampling-based planning algorithms such as MCTS for solving them. Previous approaches use Monte Carlo cost estimates to avoid constraint violations. However, these suffer from high variance which results in conservative performance with respect to costs. We propose Constrained MCTS (C-MCTS), an algorithm that estimates cost using a safety critic. The safety critic training is based on Temporal Difference learning in an offline phase prior to agent deployment. This critic limits the exploration of the search tree and removes unsafe trajectories within MCTS during deployment. C-MCTS satisfies cost constraints but operates closer to the constraint boundary, achieving higher rewards compared to previous work. As a nice byproduct, the planner is more efficient requiring fewer planning steps. Most importantly, we show that under model mismatch between the planner and the real world, our approach is less susceptible to cost violations than previous work.
An Empirical Comparison of Optimizers for Quantum Machine Learning with SPSA-based Gradients
Apr 27, 2023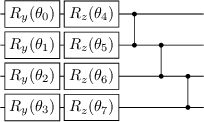
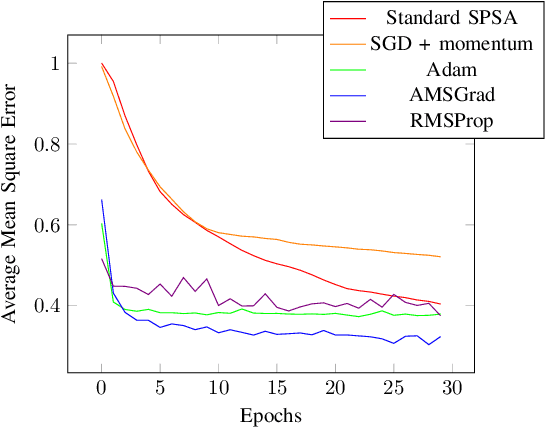
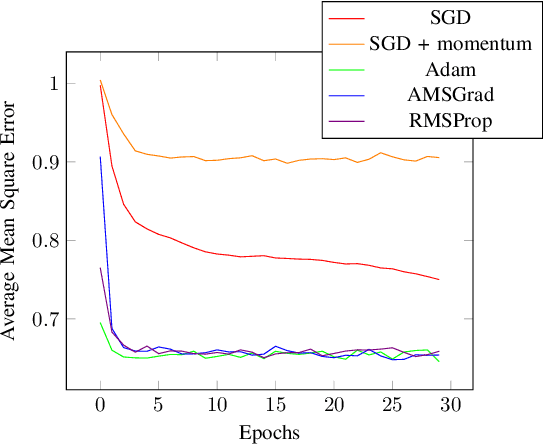

VQA have attracted a lot of attention from the quantum computing community for the last few years. Their hybrid quantum-classical nature with relatively shallow quantum circuits makes them a promising platform for demonstrating the capabilities of NISQ devices. Although the classical machine learning community focuses on gradient-based parameter optimization, finding near-exact gradients for VQC with the parameter-shift rule introduces a large sampling overhead. Therefore, gradient-free optimizers have gained popularity in quantum machine learning circles. Among the most promising candidates is the SPSA algorithm, due to its low computational cost and inherent noise resilience. We introduce a novel approach that uses the approximated gradient from SPSA in combination with state-of-the-art gradient-based classical optimizers. We demonstrate numerically that this outperforms both standard SPSA and the parameter-shift rule in terms of convergence rate and absolute error in simple regression tasks. The improvement of our novel approach over SPSA with stochastic gradient decent is even amplified when shot- and hardware-noise are taken into account. We also demonstrate that error mitigation does not significantly affect our results.
Batch Quantum Reinforcement Learning
Apr 27, 2023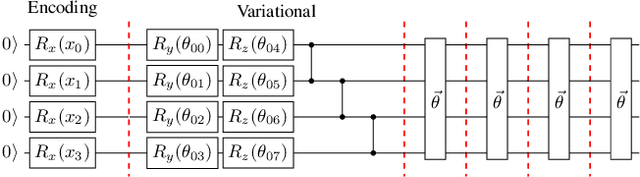
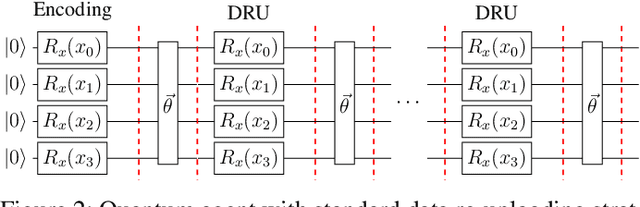
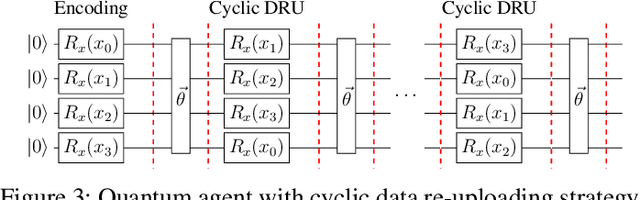
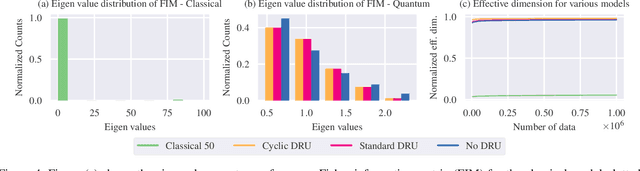
Training DRL agents is often a time-consuming process as a large number of samples and environment interactions is required. This effect is even amplified in the case of Batch RL, where the agent is trained without environment interactions solely based on a set of previously collected data. Novel approaches based on quantum computing suggest an advantage compared to classical approaches in terms of sample efficiency. To investigate this advantage, we propose a batch RL algorithm leveraging VQC as function approximators in the discrete BCQ algorithm. Additionally, we present a novel data re-uploading scheme based on cyclically shifting the input variables' order in the data encoding layers. We show the efficiency of our algorithm on the OpenAI CartPole environment and compare its performance to classical neural network-based discrete BCQ.