 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCutReg: A loss regularizer for enhancing the scalability of QML via adaptive circuit cutting
Jun 17, 2025Whether QML can offer a transformative advantage remains an open question. The severe constraints of NISQ hardware, particularly in circuit depth and connectivity, hinder both the validation of quantum advantage and the empirical investigation of major obstacles like barren plateaus. Circuit cutting techniques have emerged as a strategy to execute larger quantum circuits on smaller, less connected hardware by dividing them into subcircuits. However, this partitioning increases the number of samples needed to estimate the expectation value accurately through classical post-processing compared to estimating it directly from the full circuit. This work introduces a novel regularization term into the QML optimization process, directly penalizing the overhead associated with sampling. We demonstrate that this approach enables the optimizer to balance the advantages of gate cutting against the optimization of the typical ML cost function. Specifically, it navigates the trade-off between minimizing the cutting overhead and maintaining the overall accuracy of the QML model, paving the way to study larger complex problems in pursuit of quantum advantage.
Hype or Heuristic? Quantum Reinforcement Learning for Join Order Optimisation
May 13, 2024Identifying optimal join orders (JOs) stands out as a key challenge in database research and engineering. Owing to the large search space, established classical methods rely on approximations and heuristics. Recent efforts have successfully explored reinforcement learning (RL) for JO. Likewise, quantum versions of RL have received considerable scientific attention. Yet, it is an open question if they can achieve sustainable, overall practical advantages with improved quantum processors. In this paper, we present a novel approach that uses quantum reinforcement learning (QRL) for JO based on a hybrid variational quantum ansatz. It is able to handle general bushy join trees instead of resorting to simpler left-deep variants as compared to approaches based on quantum(-inspired) optimisation, yet requires multiple orders of magnitudes fewer qubits, which is a scarce resource even for post-NISQ systems. Despite moderate circuit depth, the ansatz exceeds current NISQ capabilities, which requires an evaluation by numerical simulations. While QRL may not significantly outperform classical approaches in solving the JO problem with respect to result quality (albeit we see parity), we find a drastic reduction in required trainable parameters. This benefits practically relevant aspects ranging from shorter training times compared to classical RL, less involved classical optimisation passes, or better use of available training data, and fits data-stream and low-latency processing scenarios. Our comprehensive evaluation and careful discussion delivers a balanced perspective on possible practical quantum advantage, provides insights for future systemic approaches, and allows for quantitatively assessing trade-offs of quantum approaches for one of the most crucial problems of database management systems.
Guided-SPSA: Simultaneous Perturbation Stochastic Approximation assisted by the Parameter Shift Rule
Apr 24, 2024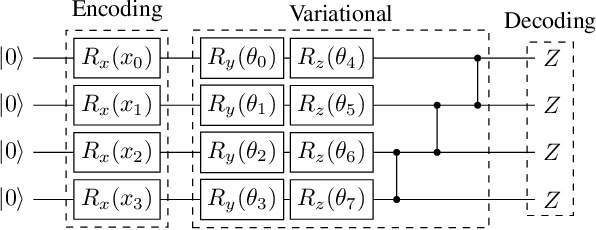
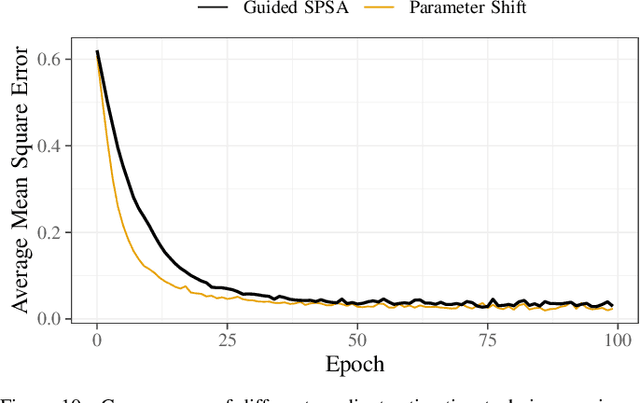
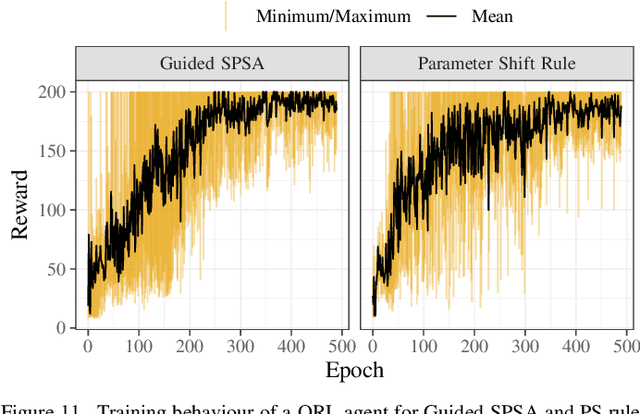

The study of variational quantum algorithms (VQCs) has received significant attention from the quantum computing community in recent years. These hybrid algorithms, utilizing both classical and quantum components, are well-suited for noisy intermediate-scale quantum devices. Though estimating exact gradients using the parameter-shift rule to optimize the VQCs is realizable in NISQ devices, they do not scale well for larger problem sizes. The computational complexity, in terms of the number of circuit evaluations required for gradient estimation by the parameter-shift rule, scales linearly with the number of parameters in VQCs. On the other hand, techniques that approximate the gradients of the VQCs, such as the simultaneous perturbation stochastic approximation (SPSA), do not scale with the number of parameters but struggle with instability and often attain suboptimal solutions. In this work, we introduce a novel gradient estimation approach called Guided-SPSA, which meaningfully combines the parameter-shift rule and SPSA-based gradient approximation. The Guided-SPSA results in a 15% to 25% reduction in the number of circuit evaluations required during training for a similar or better optimality of the solution found compared to the parameter-shift rule. The Guided-SPSA outperforms standard SPSA in all scenarios and outperforms the parameter-shift rule in scenarios such as suboptimal initialization of the parameters. We demonstrate numerically the performance of Guided-SPSA on different paradigms of quantum machine learning, such as regression, classification, and reinforcement learning.
Uncovering Instabilities in Variational-Quantum Deep Q-Networks
Feb 10, 2022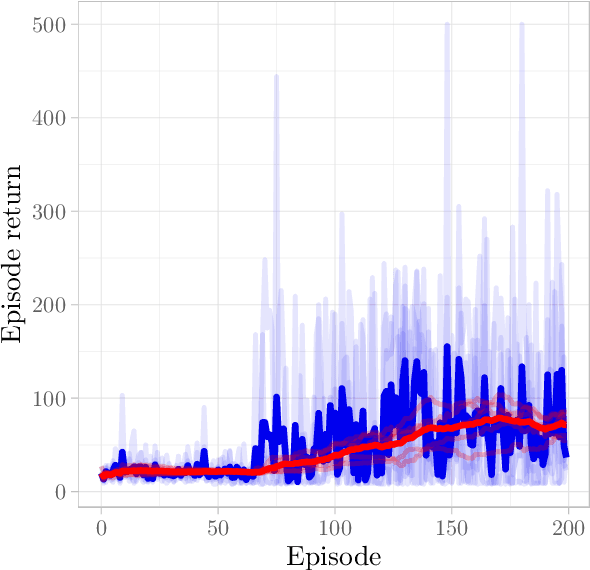
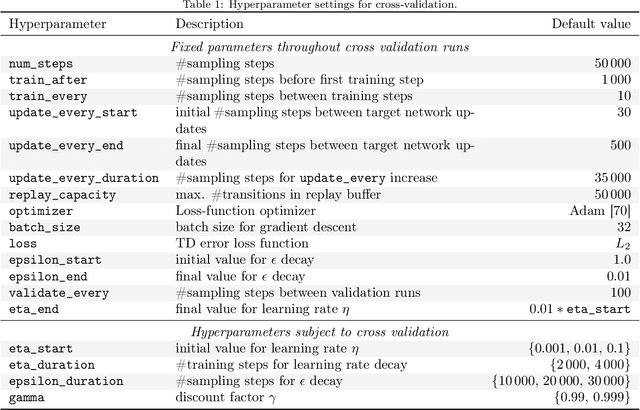
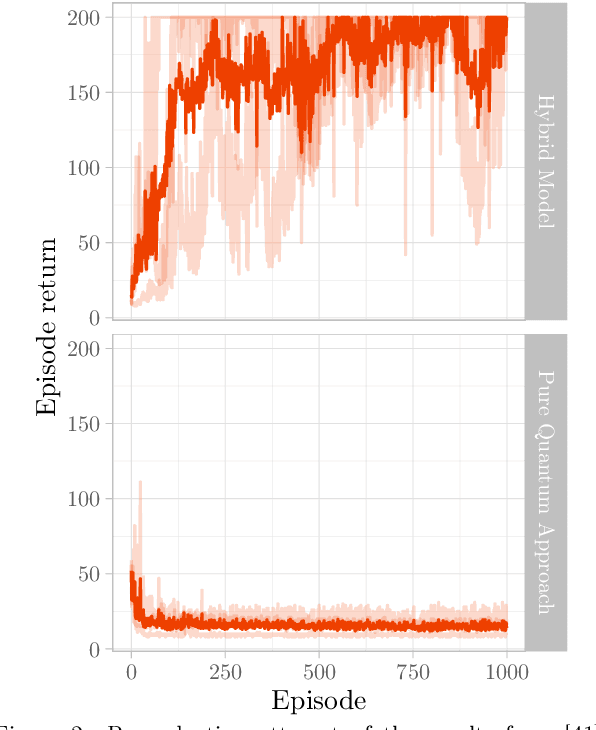
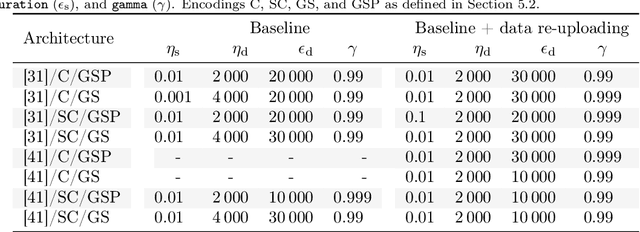
Deep Reinforcement Learning (RL) has considerably advanced over the past decade. At the same time, state-of-the-art RL algorithms require a large computational budget in terms of training time to converge. Recent work has started to approach this problem through the lens of quantum computing, which promises theoretical speed-ups for several traditionally hard tasks. In this work, we examine a class of hybrid quantumclassical RL algorithms that we collectively refer to as variational quantum deep Q-networks (VQ-DQN). We show that VQ-DQN approaches are subject to instabilities that cause the learned policy to diverge, study the extent to which this afflicts reproduciblity of established results based on classical simulation, and perform systematic experiments to identify potential explanations for the observed instabilities. Additionally, and in contrast to most existing work on quantum reinforcement learning, we execute RL algorithms on an actual quantum processing unit (an IBM Quantum Device) and investigate differences in behaviour between simulated and physical quantum systems that suffer from implementation deficiencies. Our experiments show that, contrary to opposite claims in the literature, it cannot be conclusively decided if known quantum approaches, even if simulated without physical imperfections, can provide an advantage as compared to classical approaches. Finally, we provide a robust, universal and well-tested implementation of VQ-DQN as a reproducible testbed for future experiments.