 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHype or Heuristic? Quantum Reinforcement Learning for Join Order Optimisation
May 13, 2024Identifying optimal join orders (JOs) stands out as a key challenge in database research and engineering. Owing to the large search space, established classical methods rely on approximations and heuristics. Recent efforts have successfully explored reinforcement learning (RL) for JO. Likewise, quantum versions of RL have received considerable scientific attention. Yet, it is an open question if they can achieve sustainable, overall practical advantages with improved quantum processors. In this paper, we present a novel approach that uses quantum reinforcement learning (QRL) for JO based on a hybrid variational quantum ansatz. It is able to handle general bushy join trees instead of resorting to simpler left-deep variants as compared to approaches based on quantum(-inspired) optimisation, yet requires multiple orders of magnitudes fewer qubits, which is a scarce resource even for post-NISQ systems. Despite moderate circuit depth, the ansatz exceeds current NISQ capabilities, which requires an evaluation by numerical simulations. While QRL may not significantly outperform classical approaches in solving the JO problem with respect to result quality (albeit we see parity), we find a drastic reduction in required trainable parameters. This benefits practically relevant aspects ranging from shorter training times compared to classical RL, less involved classical optimisation passes, or better use of available training data, and fits data-stream and low-latency processing scenarios. Our comprehensive evaluation and careful discussion delivers a balanced perspective on possible practical quantum advantage, provides insights for future systemic approaches, and allows for quantitatively assessing trade-offs of quantum approaches for one of the most crucial problems of database management systems.
Uncovering Instabilities in Variational-Quantum Deep Q-Networks
Feb 10, 2022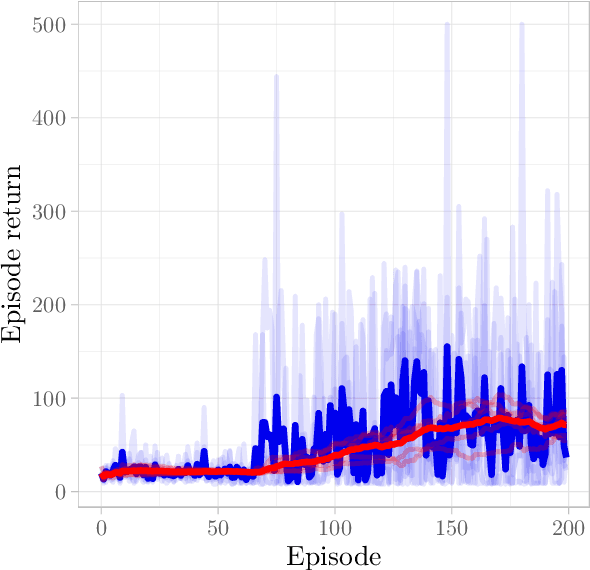
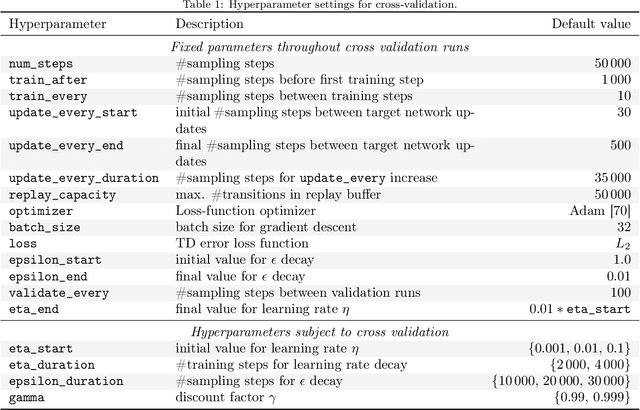
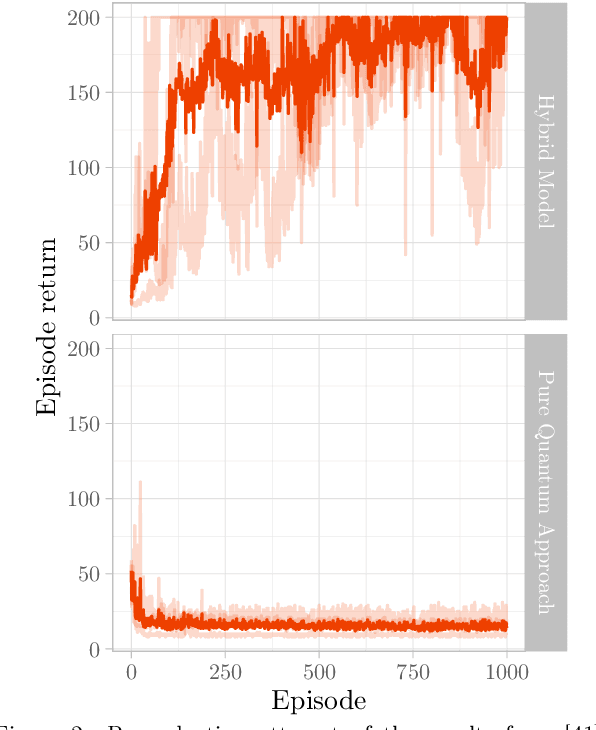
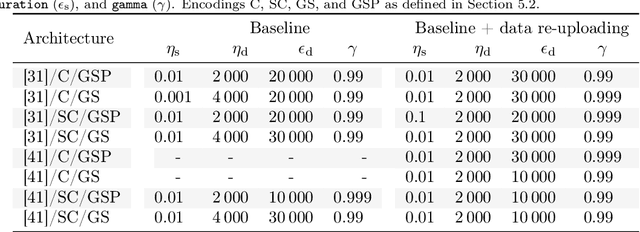
Deep Reinforcement Learning (RL) has considerably advanced over the past decade. At the same time, state-of-the-art RL algorithms require a large computational budget in terms of training time to converge. Recent work has started to approach this problem through the lens of quantum computing, which promises theoretical speed-ups for several traditionally hard tasks. In this work, we examine a class of hybrid quantumclassical RL algorithms that we collectively refer to as variational quantum deep Q-networks (VQ-DQN). We show that VQ-DQN approaches are subject to instabilities that cause the learned policy to diverge, study the extent to which this afflicts reproduciblity of established results based on classical simulation, and perform systematic experiments to identify potential explanations for the observed instabilities. Additionally, and in contrast to most existing work on quantum reinforcement learning, we execute RL algorithms on an actual quantum processing unit (an IBM Quantum Device) and investigate differences in behaviour between simulated and physical quantum systems that suffer from implementation deficiencies. Our experiments show that, contrary to opposite claims in the literature, it cannot be conclusively decided if known quantum approaches, even if simulated without physical imperfections, can provide an advantage as compared to classical approaches. Finally, we provide a robust, universal and well-tested implementation of VQ-DQN as a reproducible testbed for future experiments.