 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProGiDiff: Prompt-Guided Diffusion-Based Medical Image Segmentation
Jan 22, 2026Widely adopted medical image segmentation methods, although efficient, are primarily deterministic and remain poorly amenable to natural language prompts. Thus, they lack the capability to estimate multiple proposals, human interaction, and cross-modality adaptation. Recently, text-to-image diffusion models have shown potential to bridge the gap. However, training them from scratch requires a large dataset-a limitation for medical image segmentation. Furthermore, they are often limited to binary segmentation and cannot be conditioned on a natural language prompt. To this end, we propose a novel framework called ProGiDiff that leverages existing image generation models for medical image segmentation purposes. Specifically, we propose a ControlNet-style conditioning mechanism with a custom encoder, suitable for image conditioning, to steer a pre-trained diffusion model to output segmentation masks. It naturally extends to a multi-class setting simply by prompting the target organ. Our experiment on organ segmentation from CT images demonstrates strong performance compared to previous methods and could greatly benefit from an expert-in-the-loop setting to leverage multiple proposals. Importantly, we demonstrate that the learned conditioning mechanism can be easily transferred through low-rank, few-shot adaptation to segment MR images.
Uncertainty-Aware Likelihood Ratio Estimation for Pixel-Wise Out-of-Distribution Detection
Aug 01, 2025Semantic segmentation models trained on known object classes often fail in real-world autonomous driving scenarios by confidently misclassifying unknown objects. While pixel-wise out-of-distribution detection can identify unknown objects, existing methods struggle in complex scenes where rare object classes are often confused with truly unknown objects. We introduce an uncertainty-aware likelihood ratio estimation method that addresses these limitations. Our approach uses an evidential classifier within a likelihood ratio test to distinguish between known and unknown pixel features from a semantic segmentation model, while explicitly accounting for uncertainty. Instead of producing point estimates, our method outputs probability distributions that capture uncertainty from both rare training examples and imperfect synthetic outliers. We show that by incorporating uncertainty in this way, outlier exposure can be leveraged more effectively. Evaluated on five standard benchmark datasets, our method achieves the lowest average false positive rate (2.5%) among state-of-the-art while maintaining high average precision (90.91%) and incurring only negligible computational overhead. Code is available at https://github.com/glasbruch/ULRE.
An Empirical Comparison of Optimizers for Quantum Machine Learning with SPSA-based Gradients
Apr 27, 2023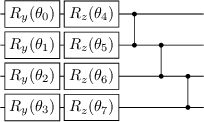
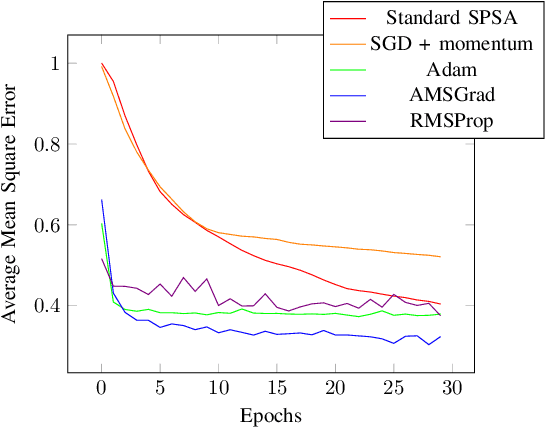
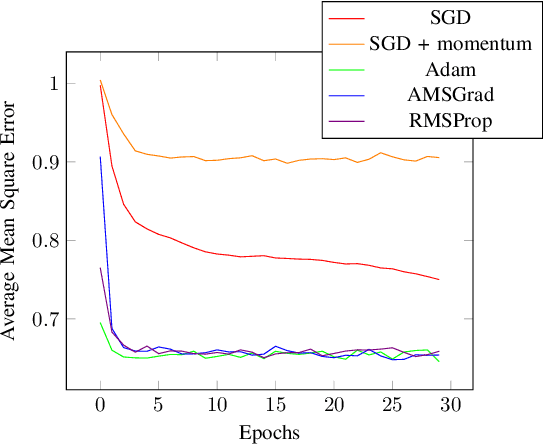

VQA have attracted a lot of attention from the quantum computing community for the last few years. Their hybrid quantum-classical nature with relatively shallow quantum circuits makes them a promising platform for demonstrating the capabilities of NISQ devices. Although the classical machine learning community focuses on gradient-based parameter optimization, finding near-exact gradients for VQC with the parameter-shift rule introduces a large sampling overhead. Therefore, gradient-free optimizers have gained popularity in quantum machine learning circles. Among the most promising candidates is the SPSA algorithm, due to its low computational cost and inherent noise resilience. We introduce a novel approach that uses the approximated gradient from SPSA in combination with state-of-the-art gradient-based classical optimizers. We demonstrate numerically that this outperforms both standard SPSA and the parameter-shift rule in terms of convergence rate and absolute error in simple regression tasks. The improvement of our novel approach over SPSA with stochastic gradient decent is even amplified when shot- and hardware-noise are taken into account. We also demonstrate that error mitigation does not significantly affect our results.
Batch Quantum Reinforcement Learning
Apr 27, 2023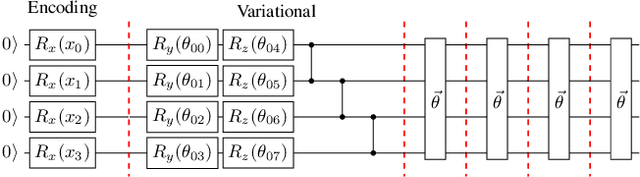
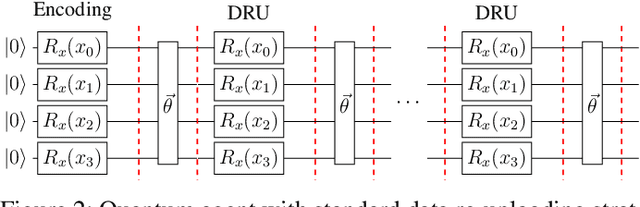
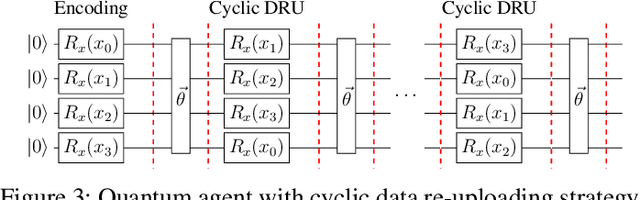
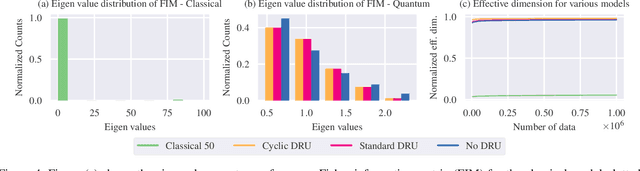
Training DRL agents is often a time-consuming process as a large number of samples and environment interactions is required. This effect is even amplified in the case of Batch RL, where the agent is trained without environment interactions solely based on a set of previously collected data. Novel approaches based on quantum computing suggest an advantage compared to classical approaches in terms of sample efficiency. To investigate this advantage, we propose a batch RL algorithm leveraging VQC as function approximators in the discrete BCQ algorithm. Additionally, we present a novel data re-uploading scheme based on cyclically shifting the input variables' order in the data encoding layers. We show the efficiency of our algorithm on the OpenAI CartPole environment and compare its performance to classical neural network-based discrete BCQ.