 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Scaling Laws for End-to-End Autonomous Driving
Apr 06, 2025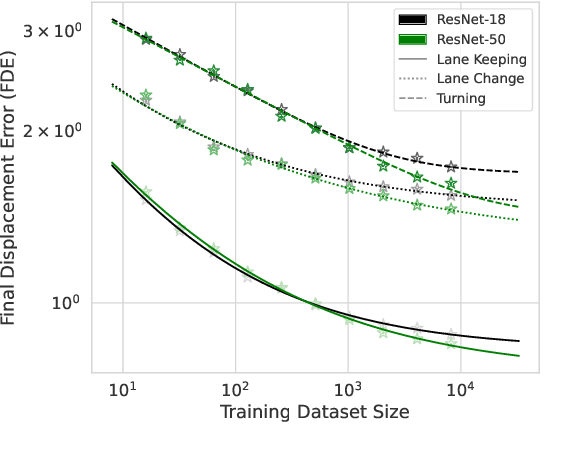
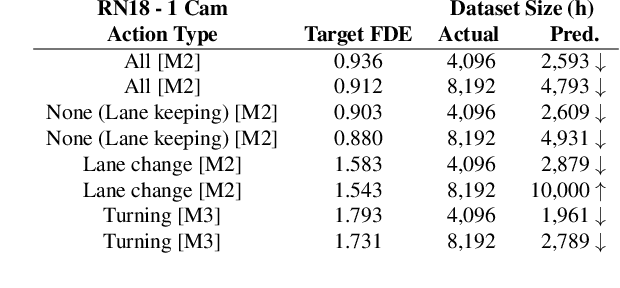

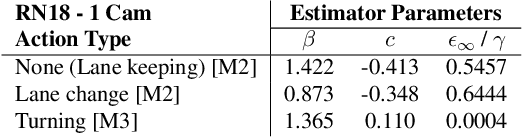
Autonomous vehicle (AV) stacks have traditionally relied on decomposed approaches, with separate modules handling perception, prediction, and planning. However, this design introduces information loss during inter-module communication, increases computational overhead, and can lead to compounding errors. To address these challenges, recent works have proposed architectures that integrate all components into an end-to-end differentiable model, enabling holistic system optimization. This shift emphasizes data engineering over software integration, offering the potential to enhance system performance by simply scaling up training resources. In this work, we evaluate the performance of a simple end-to-end driving architecture on internal driving datasets ranging in size from 16 to 8192 hours with both open-loop metrics and closed-loop simulations. Specifically, we investigate how much additional training data is needed to achieve a target performance gain, e.g., a 5% improvement in motion prediction accuracy. By understanding the relationship between model performance and training dataset size, we aim to provide insights for data-driven decision-making in autonomous driving development.
Warm-Start Variational Quantum Policy Iteration
Apr 16, 2024



Reinforcement learning is a powerful framework aiming to determine optimal behavior in highly complex decision-making scenarios. This objective can be achieved using policy iteration, which requires to solve a typically large linear system of equations. We propose the variational quantum policy iteration (VarQPI) algorithm, realizing this step with a NISQ-compatible quantum-enhanced subroutine. Its scalability is supported by an analysis of the structure of generic reinforcement learning environments, laying the foundation for potential quantum advantage with utility-scale quantum computers. Furthermore, we introduce the warm-start initialization variant (WS-VarQPI) that significantly reduces resource overhead. The algorithm solves a large FrozenLake environment with an underlying 256x256-dimensional linear system, indicating its practical robustness.
NVRadarNet: Real-Time Radar Obstacle and Free Space Detection for Autonomous Driving
Sep 29, 2022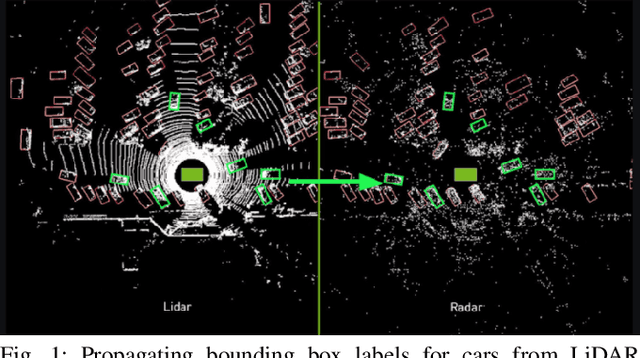

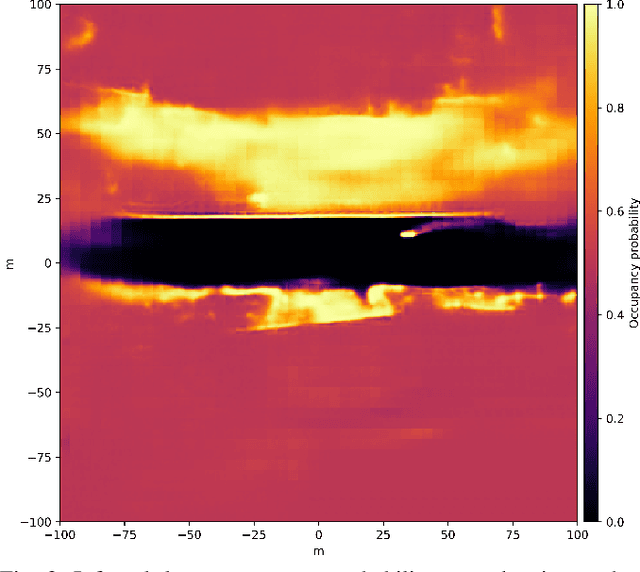

Detecting obstacles is crucial for safe and efficient autonomous driving. To this end, we present NVRadarNet, a deep neural network (DNN) that detects dynamic obstacles and drivable free space using automotive RADAR sensors. The network utilizes temporally accumulated data from multiple RADAR sensors to detect dynamic obstacles and compute their orientation in a top-down bird's-eye view (BEV). The network also regresses drivable free space to detect unclassified obstacles. Our DNN is the first of its kind to utilize sparse RADAR signals in order to perform obstacle and free space detection in real time from RADAR data only. The network has been successfully used for perception on our autonomous vehicles in real self-driving scenarios. The network runs faster than real time on an embedded GPU and shows good generalization across geographic regions.
MVLidarNet: Real-Time Multi-Class Scene Understanding for Autonomous Driving Using Multiple Views
Jun 09, 2020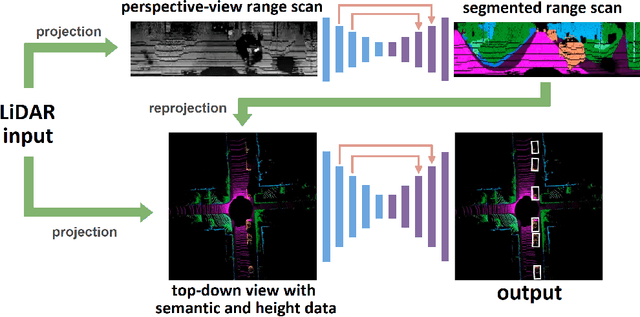
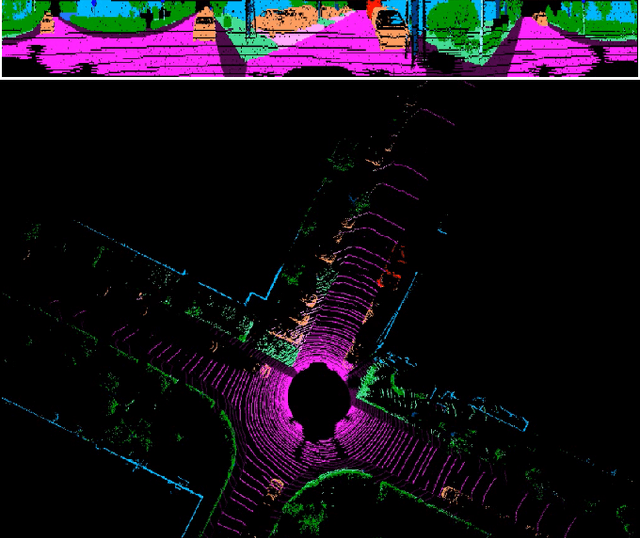


Autonomous driving requires the inference of actionable information such as detecting and classifying objects, and determining the drivable space. To this end, we present a two-stage deep neural network (MVLidarNet) for multi-class object detection and drivable segmentation using multiple views of a single LiDAR point cloud. The first stage processes the point cloud projected onto a perspective view in order to semantically segment the scene. The second stage then processes the point cloud (along with semantic labels from the first stage) projected onto a bird's eye view, to detect and classify objects. Both stages are simple encoder-decoders. We show that our multi-view, multi-stage, multi-class approach is able to detect and classify objects while simultaneously determining the drivable space using a single LiDAR scan as input, in challenging scenes with more than one hundred vehicles and pedestrians at a time. The system operates efficiently at 150 fps on an embedded GPU designed for a self-driving car, including a postprocessing step to maintain identities over time. We show results on both KITTI and a much larger internal dataset, thus demonstrating the method's ability to scale by an order of magnitude.
Autonomous 3D Reconstruction Using a MAV
Jun 23, 2015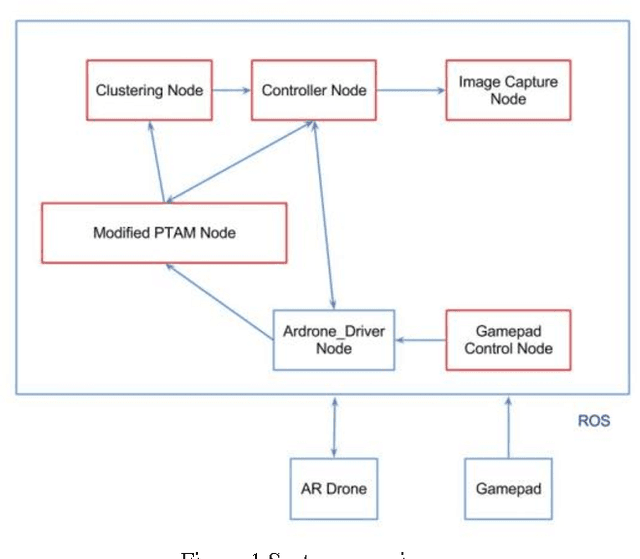
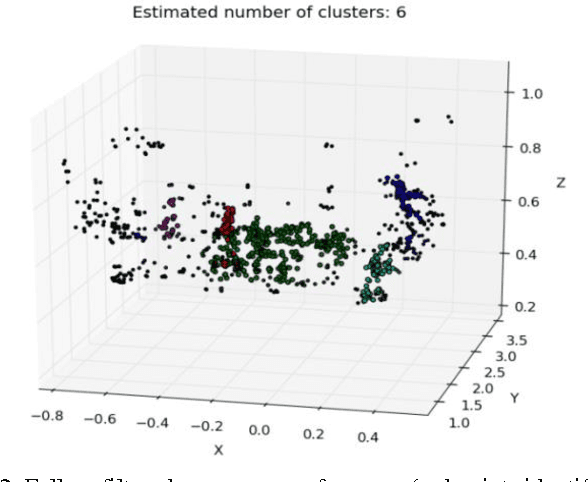

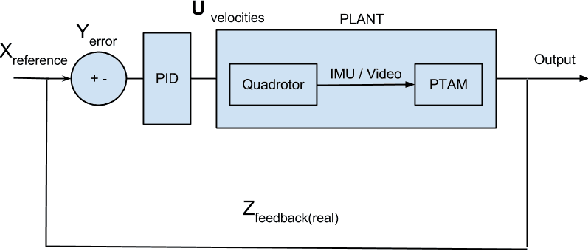
An approach is proposed for high resolution 3D reconstruction of an object using a Micro Air Vehicle (MAV). A system is described which autonomously captures images and performs a dense 3D reconstruction via structure from motion with no prior knowledge of the environment. Only the MAVs own sensors, the front facing camera and the Inertial Measurement Unit (IMU) are utilized. Precision agriculture is considered as an example application for the system.