 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVLidarNet: Real-Time Multi-Class Scene Understanding for Autonomous Driving Using Multiple Views
Paper and Code
Jun 09, 2020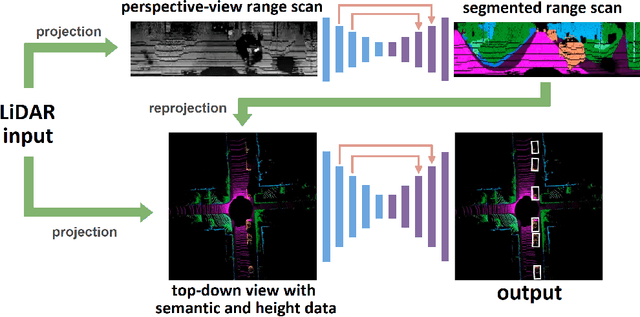
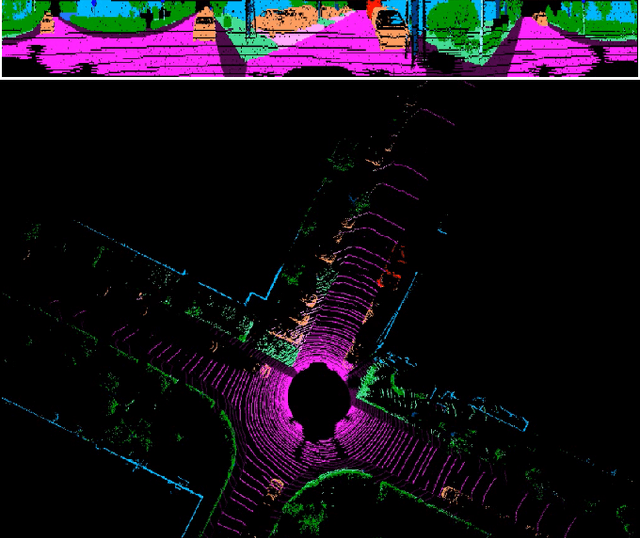


Autonomous driving requires the inference of actionable information such as detecting and classifying objects, and determining the drivable space. To this end, we present a two-stage deep neural network (MVLidarNet) for multi-class object detection and drivable segmentation using multiple views of a single LiDAR point cloud. The first stage processes the point cloud projected onto a perspective view in order to semantically segment the scene. The second stage then processes the point cloud (along with semantic labels from the first stage) projected onto a bird's eye view, to detect and classify objects. Both stages are simple encoder-decoders. We show that our multi-view, multi-stage, multi-class approach is able to detect and classify objects while simultaneously determining the drivable space using a single LiDAR scan as input, in challenging scenes with more than one hundred vehicles and pedestrians at a time. The system operates efficiently at 150 fps on an embedded GPU designed for a self-driving car, including a postprocessing step to maintain identities over time. We show results on both KITTI and a much larger internal dataset, thus demonstrating the method's ability to scale by an order of magnitude.