 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Scaling Laws for End-to-End Autonomous Driving
Apr 06, 2025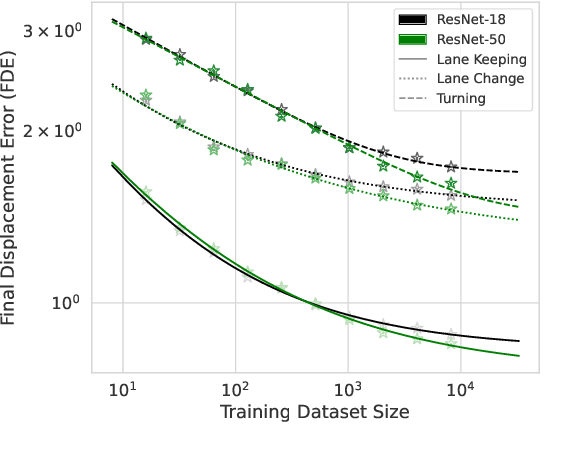
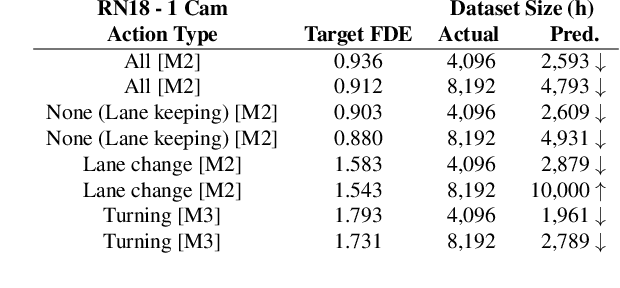

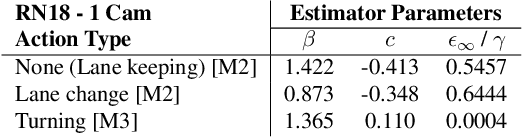
Autonomous vehicle (AV) stacks have traditionally relied on decomposed approaches, with separate modules handling perception, prediction, and planning. However, this design introduces information loss during inter-module communication, increases computational overhead, and can lead to compounding errors. To address these challenges, recent works have proposed architectures that integrate all components into an end-to-end differentiable model, enabling holistic system optimization. This shift emphasizes data engineering over software integration, offering the potential to enhance system performance by simply scaling up training resources. In this work, we evaluate the performance of a simple end-to-end driving architecture on internal driving datasets ranging in size from 16 to 8192 hours with both open-loop metrics and closed-loop simulations. Specifically, we investigate how much additional training data is needed to achieve a target performance gain, e.g., a 5% improvement in motion prediction accuracy. By understanding the relationship between model performance and training dataset size, we aim to provide insights for data-driven decision-making in autonomous driving development.
The NVIDIA PilotNet Experiments
Oct 17, 2020


Four years ago, an experimental system known as PilotNet became the first NVIDIA system to steer an autonomous car along a roadway. This system represents a departure from the classical approach for self-driving in which the process is manually decomposed into a series of modules, each performing a different task. In PilotNet, on the other hand, a single deep neural network (DNN) takes pixels as input and produces a desired vehicle trajectory as output; there are no distinct internal modules connected by human-designed interfaces. We believe that handcrafted interfaces ultimately limit performance by restricting information flow through the system and that a learned approach, in combination with other artificial intelligence systems that add redundancy, will lead to better overall performing systems. We continue to conduct research toward that goal. This document describes the PilotNet lane-keeping effort, carried out over the past five years by our NVIDIA PilotNet group in Holmdel, New Jersey. Here we present a snapshot of system status in mid-2020 and highlight some of the work done by the PilotNet group.
Invertible Autoencoder for domain adaptation
Feb 10, 2018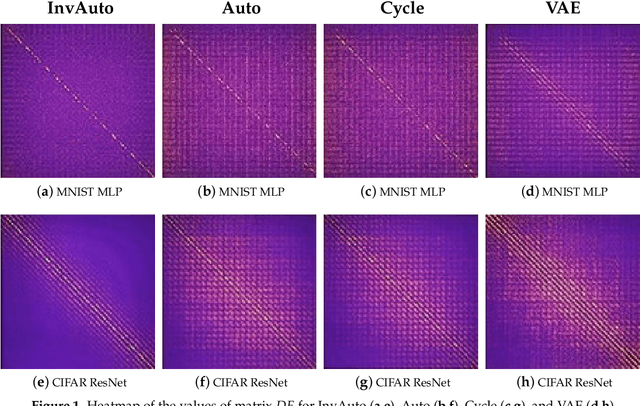
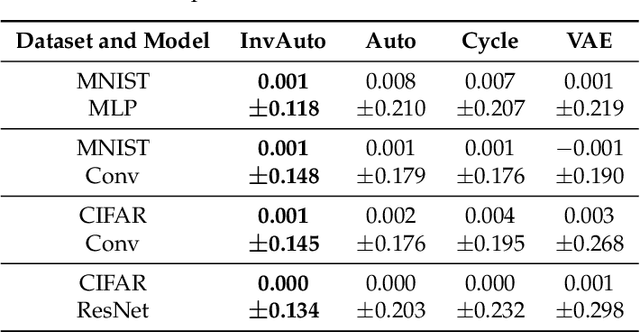
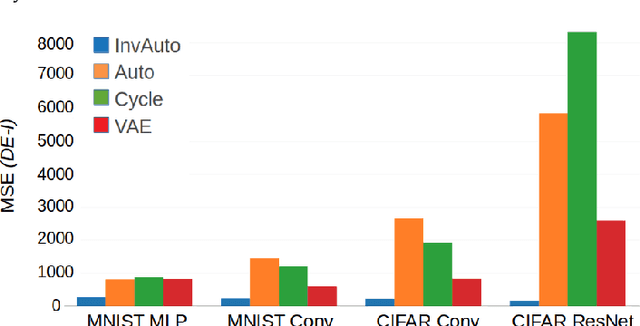
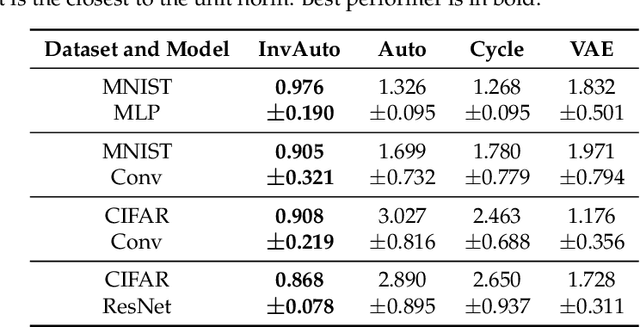
The unsupervised image-to-image translation aims at finding a mapping between the source ($A$) and target ($B$) image domains, where in many applications aligned image pairs are not available at training. This is an ill-posed learning problem since it requires inferring the joint probability distribution from marginals. Joint learning of coupled mappings $F_{AB}: A \rightarrow B$ and $F_{BA}: B \rightarrow A$ is commonly used by the state-of-the-art methods, like CycleGAN [Zhu et al., 2017], to learn this translation by introducing cycle consistency requirement to the learning problem, i.e. $F_{AB}(F_{BA}(B)) \approx B$ and $F_{BA}(F_{AB}(A)) \approx A$. Cycle consistency enforces the preservation of the mutual information between input and translated images. However, it does not explicitly enforce $F_{BA}$ to be an inverse operation to $F_{AB}$. We propose a new deep architecture that we call invertible autoencoder (InvAuto) to explicitly enforce this relation. This is done by forcing an encoder to be an inverted version of the decoder, where corresponding layers perform opposite mappings and share parameters. The mappings are constrained to be orthonormal. The resulting architecture leads to the reduction of the number of trainable parameters (up to $2$ times). We present image translation results on benchmark data sets and demonstrate state-of-the art performance of our approach. Finally, we test the proposed domain adaptation method on the task of road video conversion. We demonstrate that the videos converted with InvAuto have high quality and show that the NVIDIA neural-network-based end-to-end learning system for autonomous driving, known as PilotNet, trained on real road videos performs well when tested on the converted ones.
VisualBackProp: efficient visualization of CNNs
May 19, 2017
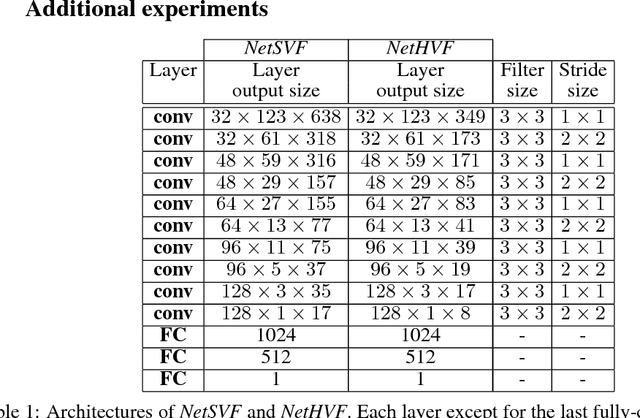
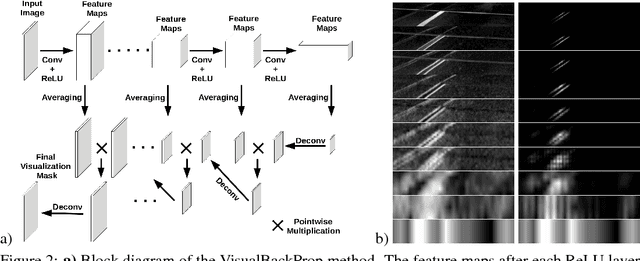

This paper proposes a new method, that we call VisualBackProp, for visualizing which sets of pixels of the input image contribute most to the predictions made by the convolutional neural network (CNN). The method heavily hinges on exploring the intuition that the feature maps contain less and less irrelevant information to the prediction decision when moving deeper into the network. The technique we propose was developed as a debugging tool for CNN-based systems for steering self-driving cars and is therefore required to run in real-time, i.e. it was designed to require less computations than a forward propagation. This makes the presented visualization method a valuable debugging tool which can be easily used during both training and inference. We furthermore justify our approach with theoretical arguments and theoretically confirm that the proposed method identifies sets of input pixels, rather than individual pixels, that collaboratively contribute to the prediction. Our theoretical findings stand in agreement with the experimental results. The empirical evaluation shows the plausibility of the proposed approach on the road video data as well as in other applications and reveals that it compares favorably to the layer-wise relevance propagation approach, i.e. it obtains similar visualization results and simultaneously achieves order of magnitude speed-ups.
Explaining How a Deep Neural Network Trained with End-to-End Learning Steers a Car
Apr 25, 2017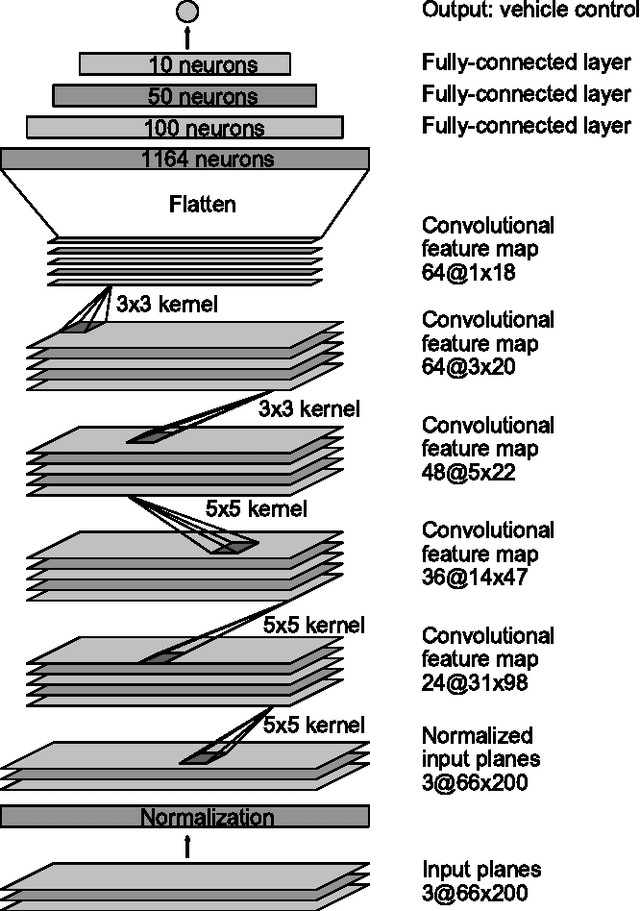
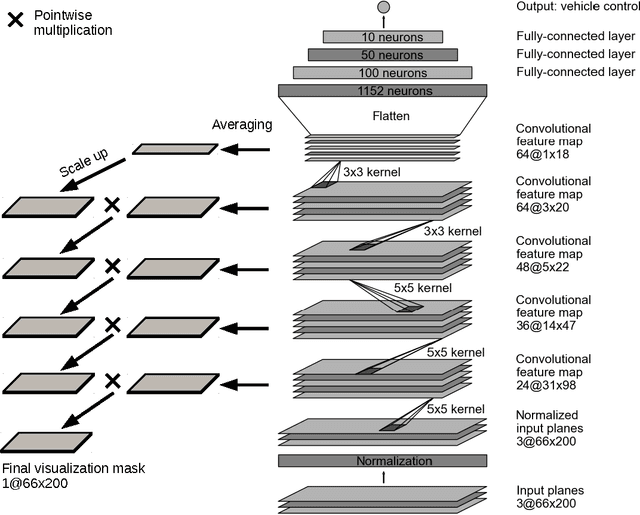

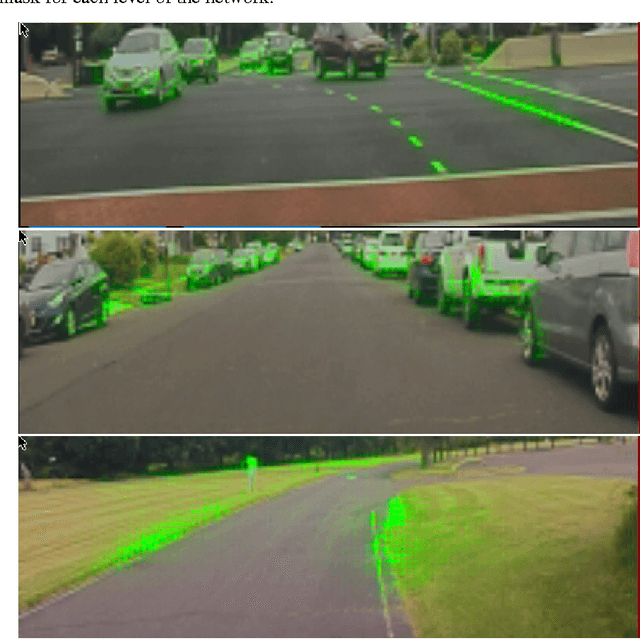
As part of a complete software stack for autonomous driving, NVIDIA has created a neural-network-based system, known as PilotNet, which outputs steering angles given images of the road ahead. PilotNet is trained using road images paired with the steering angles generated by a human driving a data-collection car. It derives the necessary domain knowledge by observing human drivers. This eliminates the need for human engineers to anticipate what is important in an image and foresee all the necessary rules for safe driving. Road tests demonstrated that PilotNet can successfully perform lane keeping in a wide variety of driving conditions, regardless of whether lane markings are present or not. The goal of the work described here is to explain what PilotNet learns and how it makes its decisions. To this end we developed a method for determining which elements in the road image most influence PilotNet's steering decision. Results show that PilotNet indeed learns to recognize relevant objects on the road. In addition to learning the obvious features such as lane markings, edges of roads, and other cars, PilotNet learns more subtle features that would be hard to anticipate and program by engineers, for example, bushes lining the edge of the road and atypical vehicle classes.
Structured adaptive and random spinners for fast machine learning computations
Nov 26, 2016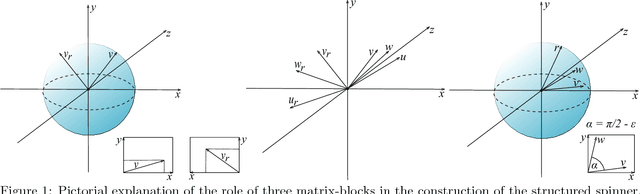
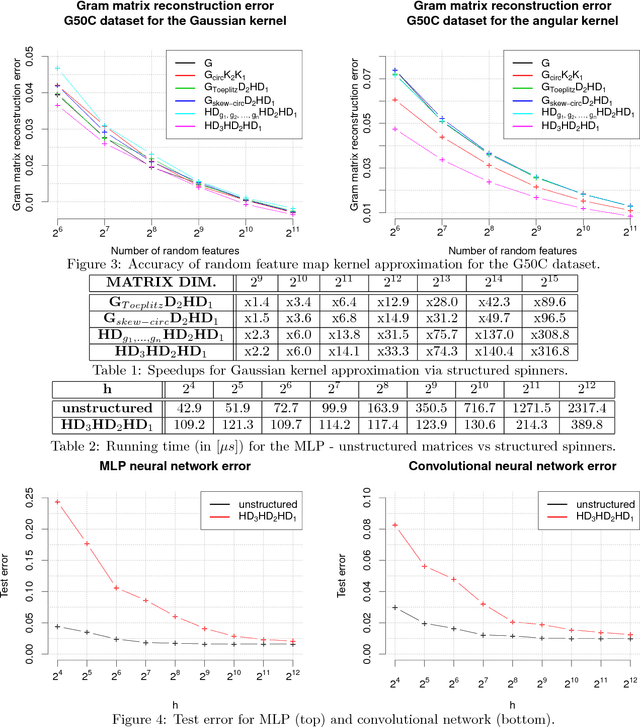
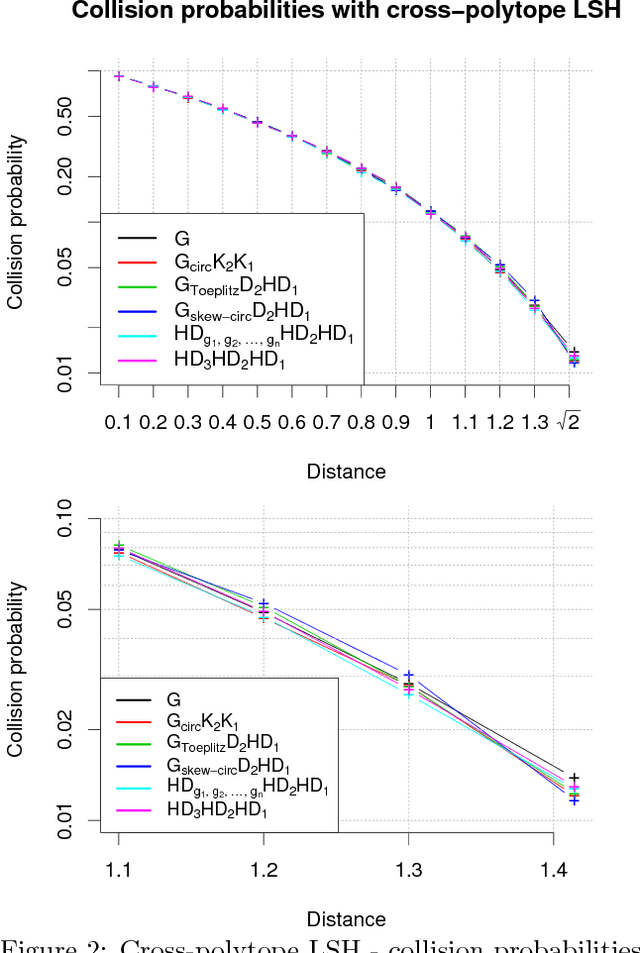
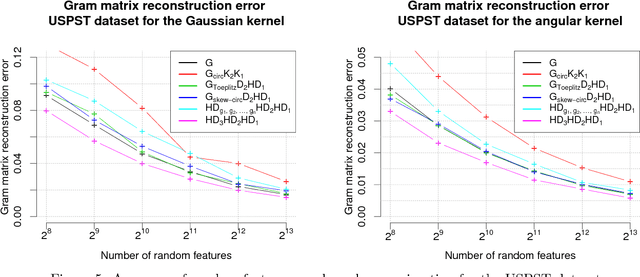
We consider an efficient computational framework for speeding up several machine learning algorithms with almost no loss of accuracy. The proposed framework relies on projections via structured matrices that we call Structured Spinners, which are formed as products of three structured matrix-blocks that incorporate rotations. The approach is highly generic, i.e. i) structured matrices under consideration can either be fully-randomized or learned, ii) our structured family contains as special cases all previously considered structured schemes, iii) the setting extends to the non-linear case where the projections are followed by non-linear functions, and iv) the method finds numerous applications including kernel approximations via random feature maps, dimensionality reduction algorithms, new fast cross-polytope LSH techniques, deep learning, convex optimization algorithms via Newton sketches, quantization with random projection trees, and more. The proposed framework comes with theoretical guarantees characterizing the capacity of the structured model in reference to its unstructured counterpart and is based on a general theoretical principle that we describe in the paper. As a consequence of our theoretical analysis, we provide the first theoretical guarantees for one of the most efficient existing LSH algorithms based on the HD3HD2HD1 structured matrix [Andoni et al., 2015]. The exhaustive experimental evaluation confirms the accuracy and efficiency of structured spinners for a variety of different applications.
Binary embeddings with structured hashed projections
Jul 01, 2016
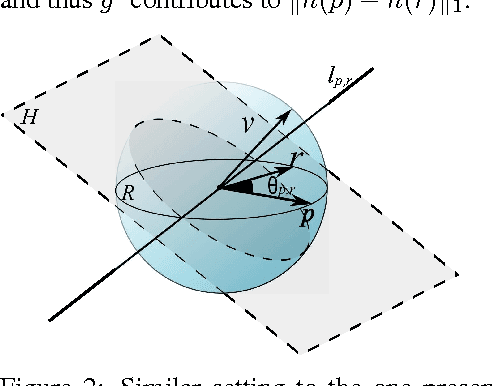

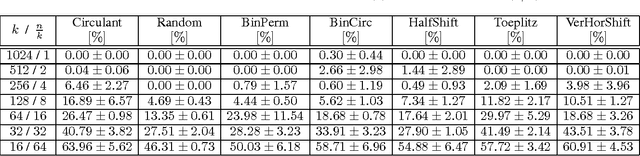
We consider the hashing mechanism for constructing binary embeddings, that involves pseudo-random projections followed by nonlinear (sign function) mappings. The pseudo-random projection is described by a matrix, where not all entries are independent random variables but instead a fixed "budget of randomness" is distributed across the matrix. Such matrices can be efficiently stored in sub-quadratic or even linear space, provide reduction in randomness usage (i.e. number of required random values), and very often lead to computational speed ups. We prove several theoretical results showing that projections via various structured matrices followed by nonlinear mappings accurately preserve the angular distance between input high-dimensional vectors. To the best of our knowledge, these results are the first that give theoretical ground for the use of general structured matrices in the nonlinear setting. In particular, they generalize previous extensions of the Johnson-Lindenstrauss lemma and prove the plausibility of the approach that was so far only heuristically confirmed for some special structured matrices. Consequently, we show that many structured matrices can be used as an efficient information compression mechanism. Our findings build a better understanding of certain deep architectures, which contain randomly weighted and untrained layers, and yet achieve high performance on different learning tasks. We empirically verify our theoretical findings and show the dependence of learning via structured hashed projections on the performance of neural network as well as nearest neighbor classifier.
On the boosting ability of top-down decision tree learning algorithm for multiclass classification
May 17, 2016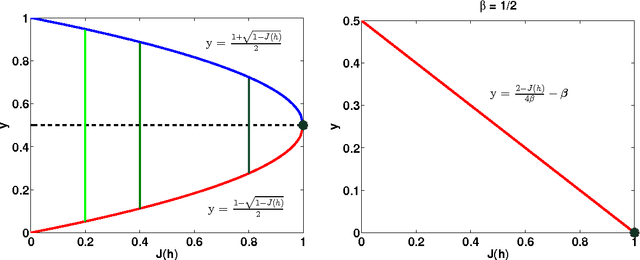
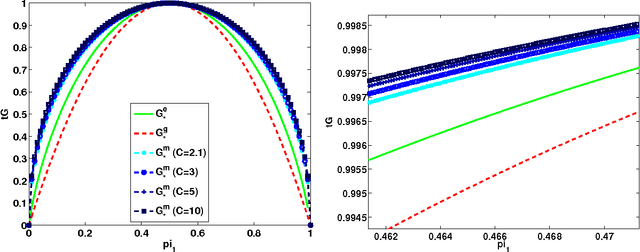
We analyze the performance of the top-down multiclass classification algorithm for decision tree learning called LOMtree, recently proposed in the literature Choromanska and Langford (2014) for solving efficiently classification problems with very large number of classes. The algorithm online optimizes the objective function which simultaneously controls the depth of the tree and its statistical accuracy. We prove important properties of this objective and explore its connection to three well-known entropy-based decision tree objectives, i.e. Shannon entropy, Gini-entropy and its modified version, for which instead online optimization schemes were not yet developed. We show, via boosting-type guarantees, that maximizing the considered objective leads also to the reduction of all of these entropy-based objectives. The bounds we obtain critically depend on the strong-concavity properties of the entropy-based criteria, where the mildest dependence on the number of classes (only logarithmic) corresponds to the Shannon entropy.
End to End Learning for Self-Driving Cars
Apr 25, 2016


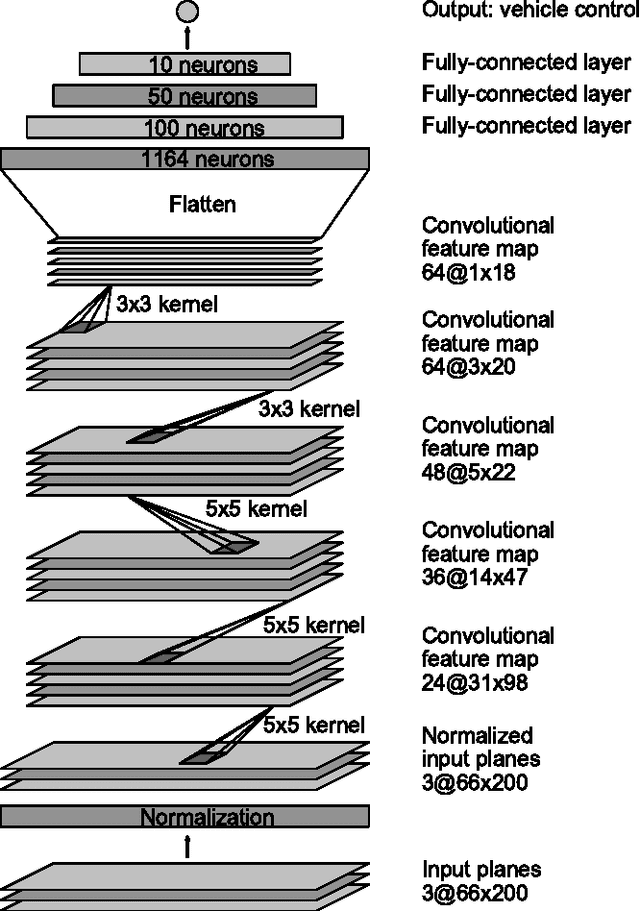
We trained a convolutional neural network (CNN) to map raw pixels from a single front-facing camera directly to steering commands. This end-to-end approach proved surprisingly powerful. With minimum training data from humans the system learns to drive in traffic on local roads with or without lane markings and on highways. It also operates in areas with unclear visual guidance such as in parking lots and on unpaved roads. The system automatically learns internal representations of the necessary processing steps such as detecting useful road features with only the human steering angle as the training signal. We never explicitly trained it to detect, for example, the outline of roads. Compared to explicit decomposition of the problem, such as lane marking detection, path planning, and control, our end-to-end system optimizes all processing steps simultaneously. We argue that this will eventually lead to better performance and smaller systems. Better performance will result because the internal components self-optimize to maximize overall system performance, instead of optimizing human-selected intermediate criteria, e.g., lane detection. Such criteria understandably are selected for ease of human interpretation which doesn't automatically guarantee maximum system performance. Smaller networks are possible because the system learns to solve the problem with the minimal number of processing steps. We used an NVIDIA DevBox and Torch 7 for training and an NVIDIA DRIVE(TM) PX self-driving car computer also running Torch 7 for determining where to drive. The system operates at 30 frames per second (FPS).
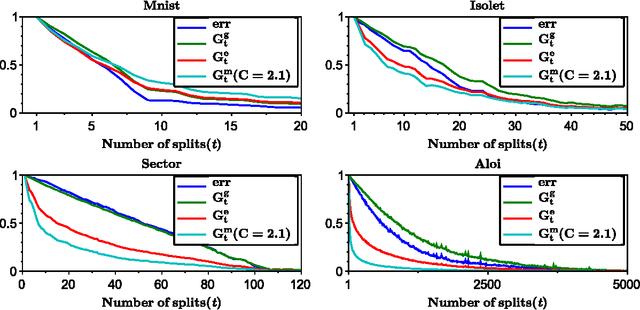
Differentially- and non-differentially-private random decision trees
Feb 05, 2015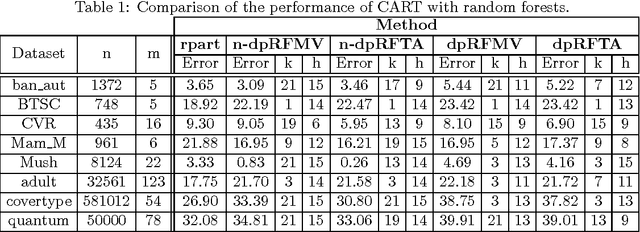
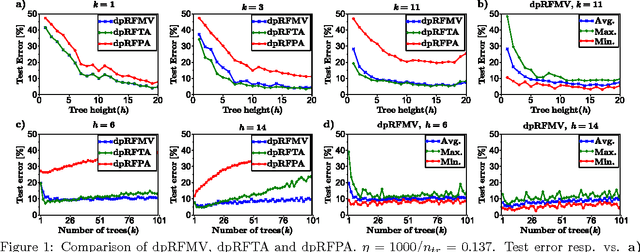
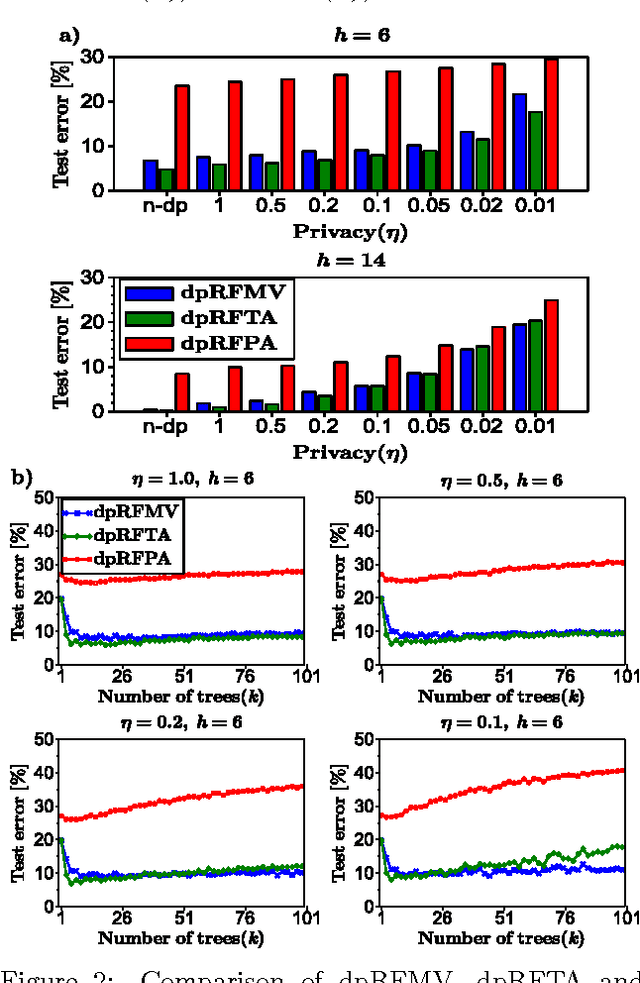
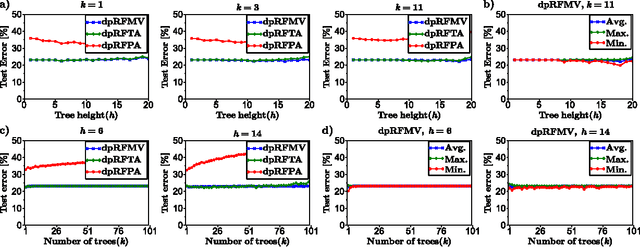
We consider supervised learning with random decision trees, where the tree construction is completely random. The method is popularly used and works well in practice despite the simplicity of the setting, but its statistical mechanism is not yet well-understood. In this paper we provide strong theoretical guarantees regarding learning with random decision trees. We analyze and compare three different variants of the algorithm that have minimal memory requirements: majority voting, threshold averaging and probabilistic averaging. The random structure of the tree enables us to adapt these methods to a differentially-private setting thus we also propose differentially-private versions of all three schemes. We give upper-bounds on the generalization error and mathematically explain how the accuracy depends on the number of random decision trees. Furthermore, we prove that only logarithmic (in the size of the dataset) number of independently selected random decision trees suffice to correctly classify most of the data, even when differential-privacy guarantees must be maintained. We empirically show that majority voting and threshold averaging give the best accuracy, also for conservative users requiring high privacy guarantees. Furthermore, we demonstrate that a simple majority voting rule is an especially good candidate for the differentially-private classifier since it is much less sensitive to the choice of forest parameters than other methods.