 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Attention: A Context-Aware Alignment Function for Machine Reading
Jun 26, 2017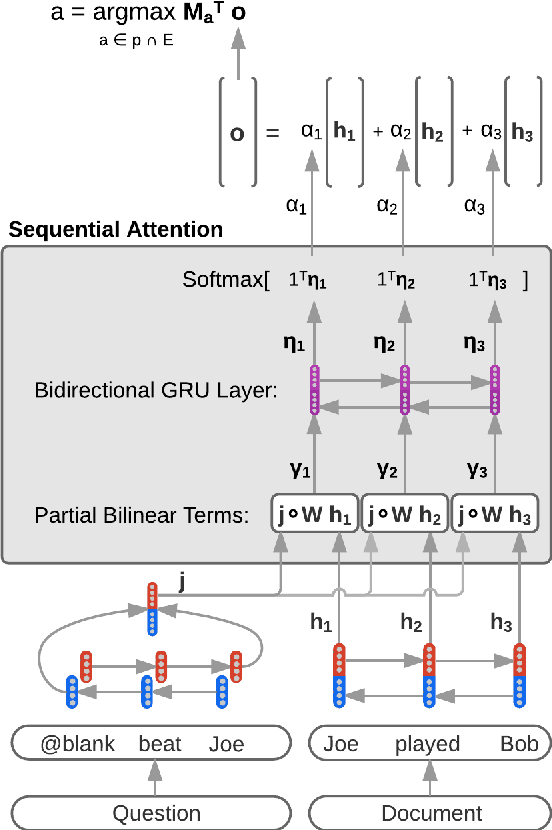


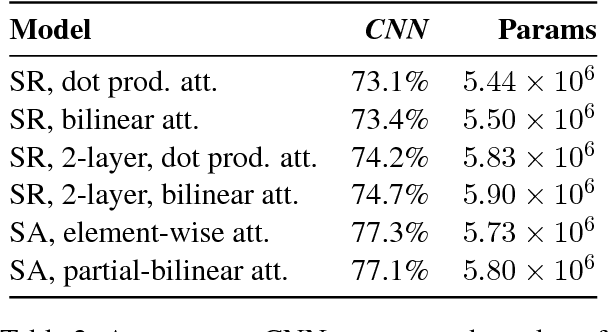
In this paper we propose a neural network model with a novel Sequential Attention layer that extends soft attention by assigning weights to words in an input sequence in a way that takes into account not just how well that word matches a query, but how well surrounding words match. We evaluate this approach on the task of reading comprehension (on the Who did What and CNN datasets) and show that it dramatically improves a strong baseline--the Stanford Reader--and is competitive with the state of the art.
Explaining How a Deep Neural Network Trained with End-to-End Learning Steers a Car
Apr 25, 2017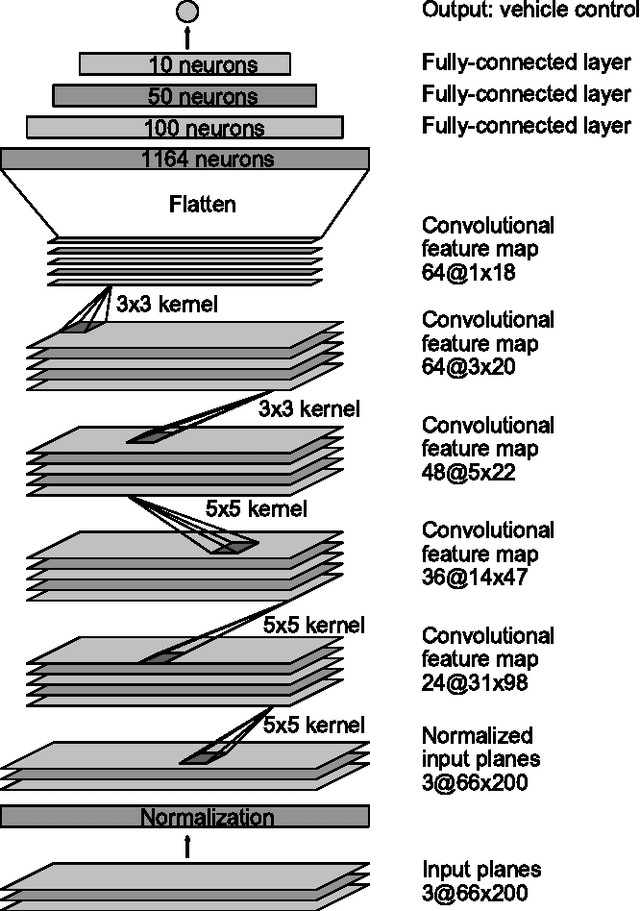
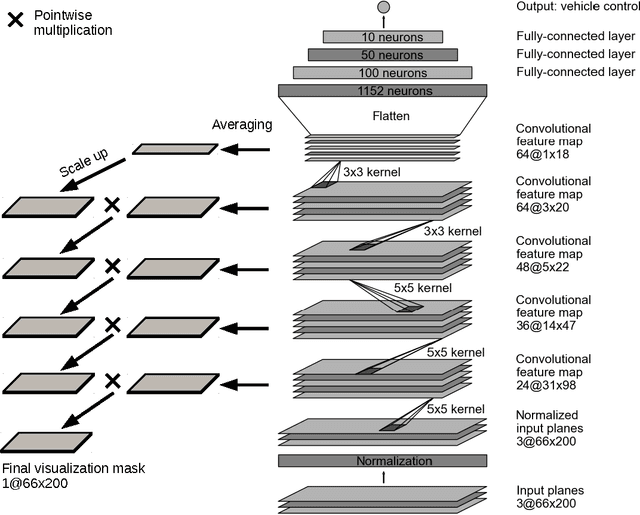

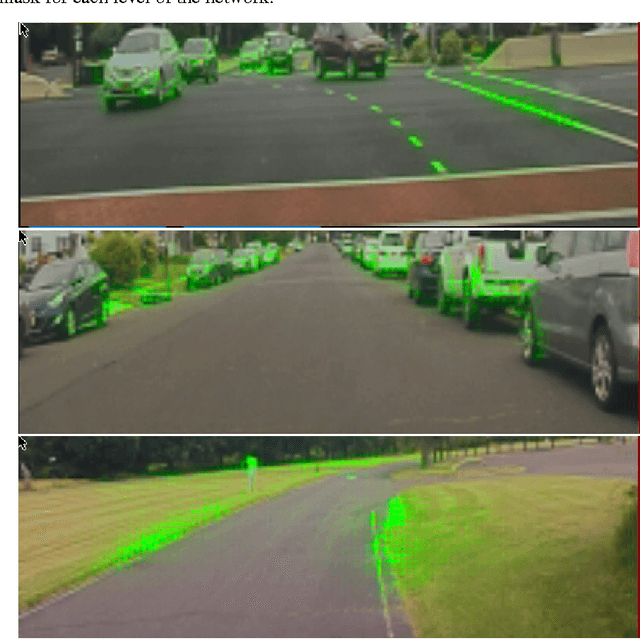
As part of a complete software stack for autonomous driving, NVIDIA has created a neural-network-based system, known as PilotNet, which outputs steering angles given images of the road ahead. PilotNet is trained using road images paired with the steering angles generated by a human driving a data-collection car. It derives the necessary domain knowledge by observing human drivers. This eliminates the need for human engineers to anticipate what is important in an image and foresee all the necessary rules for safe driving. Road tests demonstrated that PilotNet can successfully perform lane keeping in a wide variety of driving conditions, regardless of whether lane markings are present or not. The goal of the work described here is to explain what PilotNet learns and how it makes its decisions. To this end we developed a method for determining which elements in the road image most influence PilotNet's steering decision. Results show that PilotNet indeed learns to recognize relevant objects on the road. In addition to learning the obvious features such as lane markings, edges of roads, and other cars, PilotNet learns more subtle features that would be hard to anticipate and program by engineers, for example, bushes lining the edge of the road and atypical vehicle classes.