Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Attention: A Context-Aware Alignment Function for Machine Reading
Paper and Code
Jun 26, 2017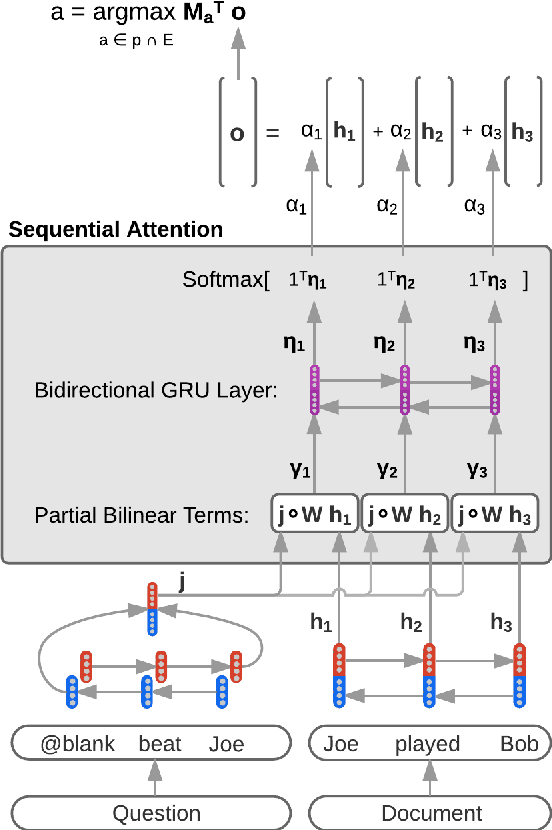


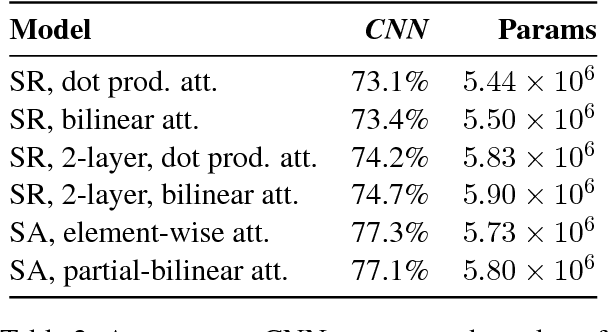
In this paper we propose a neural network model with a novel Sequential Attention layer that extends soft attention by assigning weights to words in an input sequence in a way that takes into account not just how well that word matches a query, but how well surrounding words match. We evaluate this approach on the task of reading comprehension (on the Who did What and CNN datasets) and show that it dramatically improves a strong baseline--the Stanford Reader--and is competitive with the state of the art.
* To appear in ACL 2017 2nd Workshop on Representation Learning for
NLP. Contains additional experiments in section 4 and a revised Figure 1
View paper on