 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe NVIDIA PilotNet Experiments
Oct 17, 2020
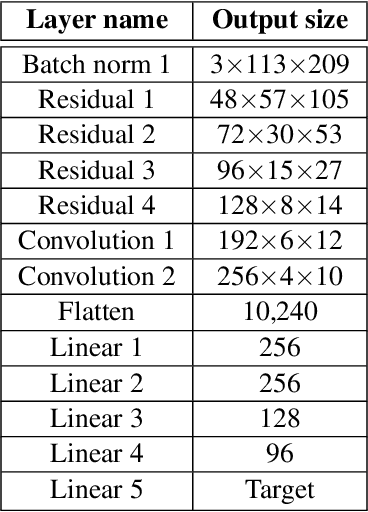


Four years ago, an experimental system known as PilotNet became the first NVIDIA system to steer an autonomous car along a roadway. This system represents a departure from the classical approach for self-driving in which the process is manually decomposed into a series of modules, each performing a different task. In PilotNet, on the other hand, a single deep neural network (DNN) takes pixels as input and produces a desired vehicle trajectory as output; there are no distinct internal modules connected by human-designed interfaces. We believe that handcrafted interfaces ultimately limit performance by restricting information flow through the system and that a learned approach, in combination with other artificial intelligence systems that add redundancy, will lead to better overall performing systems. We continue to conduct research toward that goal. This document describes the PilotNet lane-keeping effort, carried out over the past five years by our NVIDIA PilotNet group in Holmdel, New Jersey. Here we present a snapshot of system status in mid-2020 and highlight some of the work done by the PilotNet group.
DeepDriving: Learning Affordance for Direct Perception in Autonomous Driving
Sep 26, 2015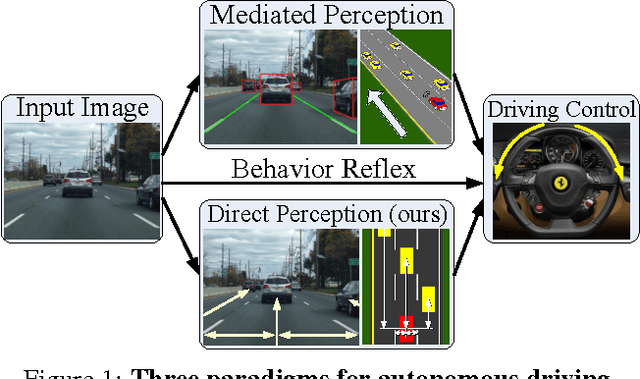
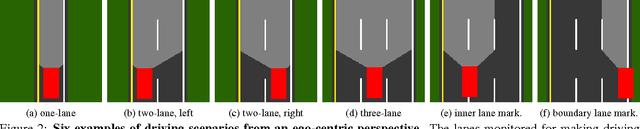

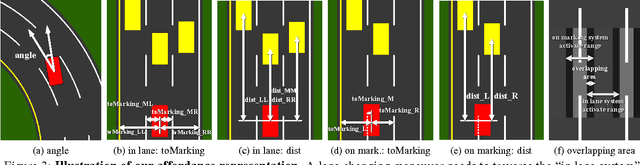
Today, there are two major paradigms for vision-based autonomous driving systems: mediated perception approaches that parse an entire scene to make a driving decision, and behavior reflex approaches that directly map an input image to a driving action by a regressor. In this paper, we propose a third paradigm: a direct perception approach to estimate the affordance for driving. We propose to map an input image to a small number of key perception indicators that directly relate to the affordance of a road/traffic state for driving. Our representation provides a set of compact yet complete descriptions of the scene to enable a simple controller to drive autonomously. Falling in between the two extremes of mediated perception and behavior reflex, we argue that our direct perception representation provides the right level of abstraction. To demonstrate this, we train a deep Convolutional Neural Network using recording from 12 hours of human driving in a video game and show that our model can work well to drive a car in a very diverse set of virtual environments. We also train a model for car distance estimation on the KITTI dataset. Results show that our direct perception approach can generalize well to real driving images. Source code and data are available on our project website.