 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the properties of Gaussian Copula Mixture Models
May 02, 2023
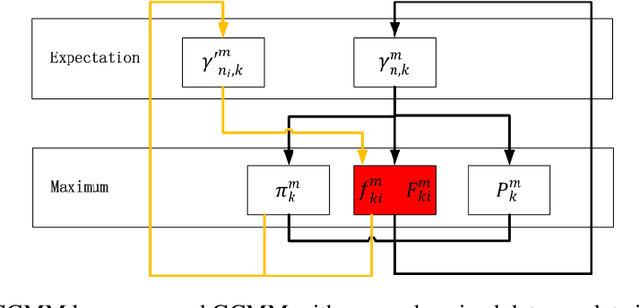
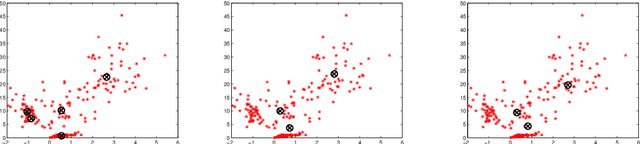

Gaussian copula mixture models (GCMM) are the generalization of Gaussian Mixture models using the concept of copula. Its mathematical definition is given and the properties of likelihood function are studied in this paper. Based on these properties, extended Expectation Maximum algorithms are developed for estimating parameters for the mixture of copulas while marginal distributions corresponding to each component is estimated using separate nonparametric statistical methods. In the experiment, GCMM can achieve better goodness-of-fitting given the same number of clusters as GMM; furthermore, GCMM can utilize unsynchronized data on each dimension to achieve deeper mining of data.
Beyond Grand Theft Auto V for Training, Testing and Enhancing Deep Learning in Self Driving Cars
Dec 04, 2017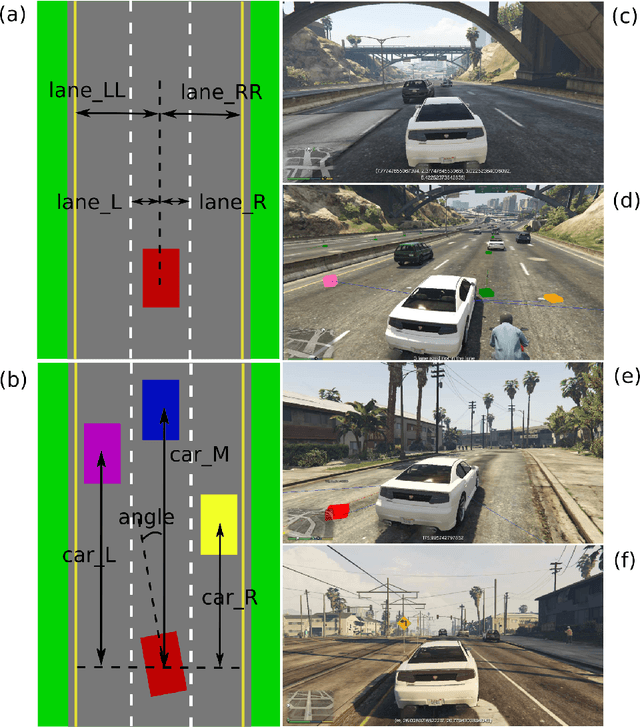


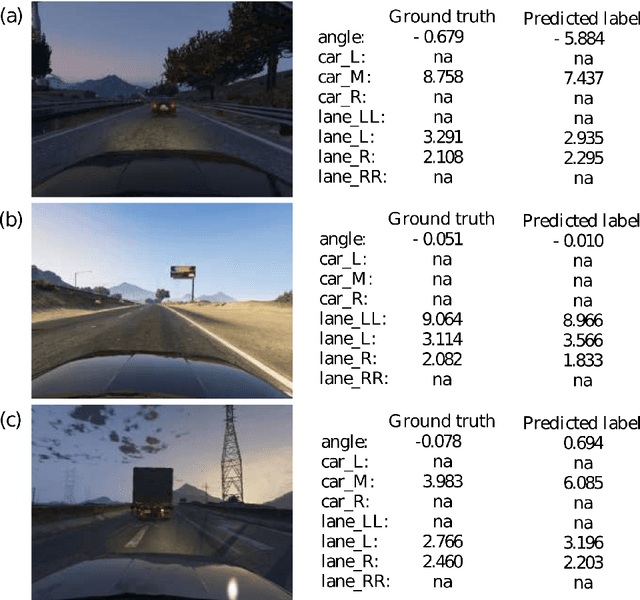
As an initial assessment, over 480,000 labeled virtual images of normal highway driving were readily generated in Grand Theft Auto V's virtual environment. Using these images, a CNN was trained to detect following distance to cars/objects ahead, lane markings, and driving angle (angular heading relative to lane centerline): all variables necessary for basic autonomous driving. Encouraging results were obtained when tested on over 50,000 labeled virtual images from substantially different GTA-V driving environments. This initial assessment begins to define both the range and scope of the labeled images needed for training as well as the range and scope of labeled images needed for testing the definition of boundaries and limitations of trained networks. It is the efficacy and flexibility of a "GTA-V"-like virtual environment that is expected to provide an efficient well-defined foundation for the training and testing of Convolutional Neural Networks for safe driving. Additionally, described is the Princeton Virtual Environment (PVE) for the training, testing and enhancement of safe driving AI, which is being developed using the video-game engine Unity. PVE is being developed to recreate rare but critical corner cases that can be used in re-training and enhancing machine learning models and understanding the limitations of current self driving models. The Florida Tesla crash is being used as an initial reference.
DeepDriving: Learning Affordance for Direct Perception in Autonomous Driving
Sep 26, 2015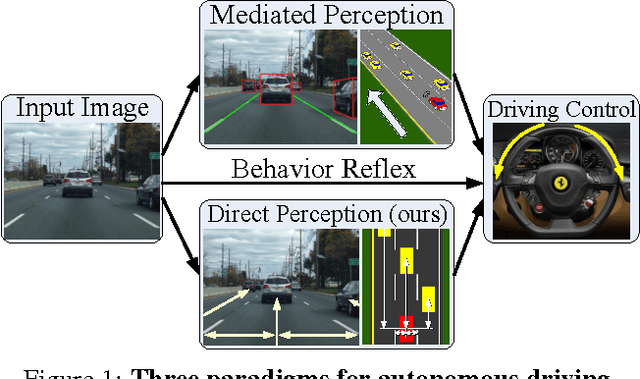
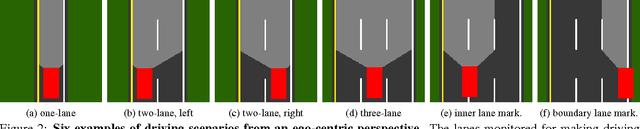

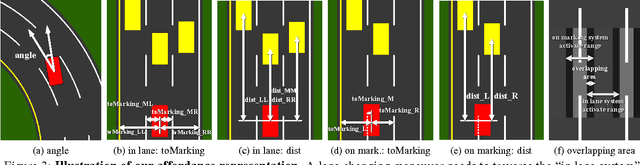
Today, there are two major paradigms for vision-based autonomous driving systems: mediated perception approaches that parse an entire scene to make a driving decision, and behavior reflex approaches that directly map an input image to a driving action by a regressor. In this paper, we propose a third paradigm: a direct perception approach to estimate the affordance for driving. We propose to map an input image to a small number of key perception indicators that directly relate to the affordance of a road/traffic state for driving. Our representation provides a set of compact yet complete descriptions of the scene to enable a simple controller to drive autonomously. Falling in between the two extremes of mediated perception and behavior reflex, we argue that our direct perception representation provides the right level of abstraction. To demonstrate this, we train a deep Convolutional Neural Network using recording from 12 hours of human driving in a video game and show that our model can work well to drive a car in a very diverse set of virtual environments. We also train a model for car distance estimation on the KITTI dataset. Results show that our direct perception approach can generalize well to real driving images. Source code and data are available on our project website.