 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws of Motion Forecasting and Planning -- A Technical Report
Jun 09, 2025We study the empirical scaling laws of a family of encoder-decoder autoregressive transformer models on the task of joint motion forecasting and planning in the autonomous driving domain. Using a 500 thousand hours driving dataset, we demonstrate that, similar to language modeling, model performance improves as a power-law function of the total compute budget, and we observe a strong correlation between model training loss and model evaluation metrics. Most interestingly, closed-loop metrics also improve with scaling, which has important implications for the suitability of open-loop metrics for model development and hill climbing. We also study the optimal scaling of the number of transformer parameters and the training data size for a training compute-optimal model. We find that as the training compute budget grows, optimal scaling requires increasing the model size 1.5x as fast as the dataset size. We also study inference-time compute scaling, where we observe that sampling and clustering the output of smaller models makes them competitive with larger models, up to a crossover point beyond which a larger models becomes more inference-compute efficient. Overall, our experimental results demonstrate that optimizing the training and inference-time scaling properties of motion forecasting and planning models is a key lever for improving their performance to address a wide variety of driving scenarios. Finally, we briefly study the utility of training on general logged driving data of other agents to improve the performance of the ego-agent, an important research area to address the scarcity of robotics data for large capacity models training.
Improving Agent Behaviors with RL Fine-tuning for Autonomous Driving
Sep 26, 2024



A major challenge in autonomous vehicle research is modeling agent behaviors, which has critical applications including constructing realistic and reliable simulations for off-board evaluation and forecasting traffic agents motion for onboard planning. While supervised learning has shown success in modeling agents across various domains, these models can suffer from distribution shift when deployed at test-time. In this work, we improve the reliability of agent behaviors by closed-loop fine-tuning of behavior models with reinforcement learning. Our method demonstrates improved overall performance, as well as improved targeted metrics such as collision rate, on the Waymo Open Sim Agents challenge. Additionally, we present a novel policy evaluation benchmark to directly assess the ability of simulated agents to measure the quality of autonomous vehicle planners and demonstrate the effectiveness of our approach on this new benchmark.
MotionLM: Multi-Agent Motion Forecasting as Language Modeling
Sep 28, 2023Reliable forecasting of the future behavior of road agents is a critical component to safe planning in autonomous vehicles. Here, we represent continuous trajectories as sequences of discrete motion tokens and cast multi-agent motion prediction as a language modeling task over this domain. Our model, MotionLM, provides several advantages: First, it does not require anchors or explicit latent variable optimization to learn multimodal distributions. Instead, we leverage a single standard language modeling objective, maximizing the average log probability over sequence tokens. Second, our approach bypasses post-hoc interaction heuristics where individual agent trajectory generation is conducted prior to interactive scoring. Instead, MotionLM produces joint distributions over interactive agent futures in a single autoregressive decoding process. In addition, the model's sequential factorization enables temporally causal conditional rollouts. The proposed approach establishes new state-of-the-art performance for multi-agent motion prediction on the Waymo Open Motion Dataset, ranking 1st on the interactive challenge leaderboard.
Vitruvion: A Generative Model of Parametric CAD Sketches
Sep 29, 2021
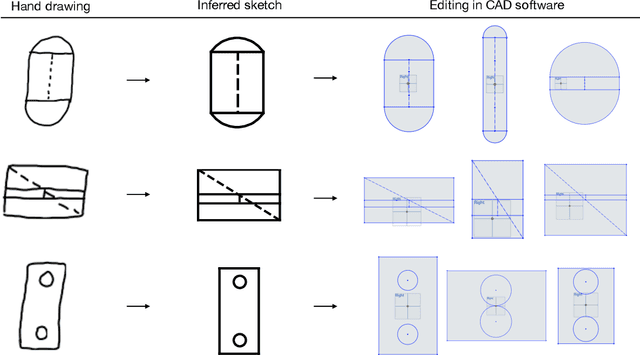
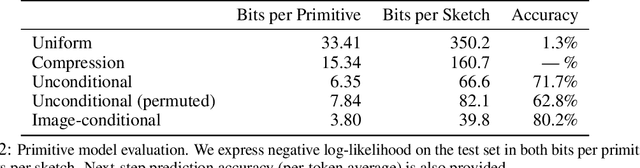
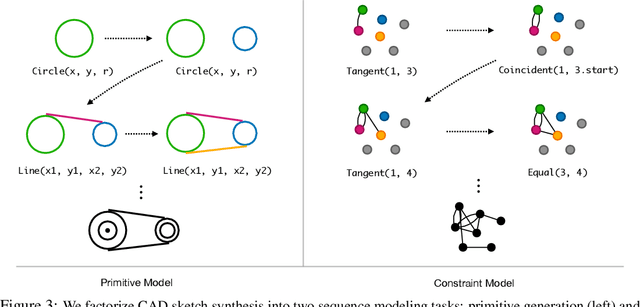
Parametric computer-aided design (CAD) tools are the predominant way that engineers specify physical structures, from bicycle pedals to airplanes to printed circuit boards. The key characteristic of parametric CAD is that design intent is encoded not only via geometric primitives, but also by parameterized constraints between the elements. This relational specification can be viewed as the construction of a constraint program, allowing edits to coherently propagate to other parts of the design. Machine learning offers the intriguing possibility of accelerating the design process via generative modeling of these structures, enabling new tools such as autocompletion, constraint inference, and conditional synthesis. In this work, we present such an approach to generative modeling of parametric CAD sketches, which constitute the basic computational building blocks of modern mechanical design. Our model, trained on real-world designs from the SketchGraphs dataset, autoregressively synthesizes sketches as sequences of primitives, with initial coordinates, and constraints that reference back to the sampled primitives. As samples from the model match the constraint graph representation used in standard CAD software, they may be directly imported, solved, and edited according to downstream design tasks. In addition, we condition the model on various contexts, including partial sketches (primers) and images of hand-drawn sketches. Evaluation of the proposed approach demonstrates its ability to synthesize realistic CAD sketches and its potential to aid the mechanical design workflow.
SketchGraphs: A Large-Scale Dataset for Modeling Relational Geometry in Computer-Aided Design
Jul 16, 2020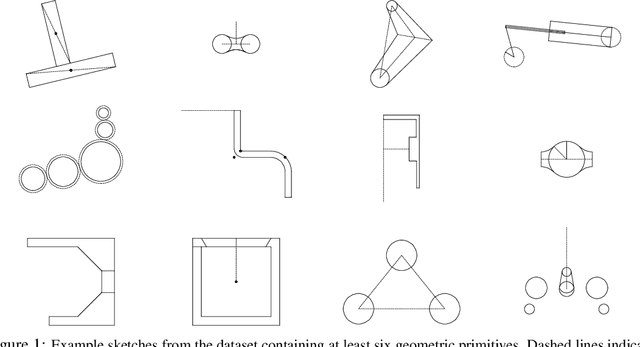
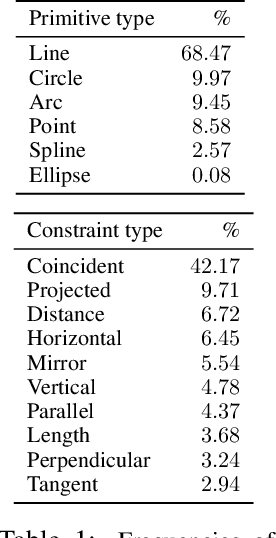
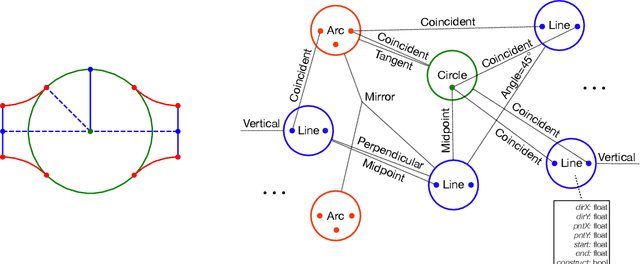
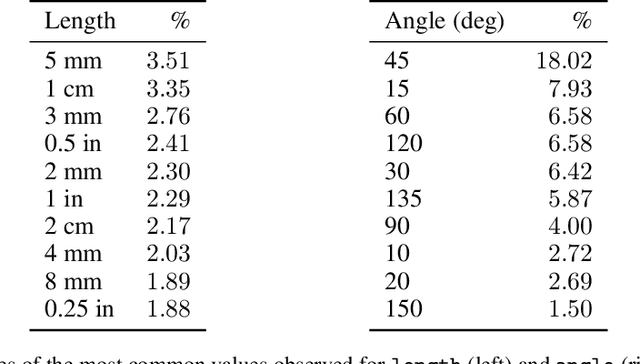
Parametric computer-aided design (CAD) is the dominant paradigm in mechanical engineering for physical design. Distinguished by relational geometry, parametric CAD models begin as two-dimensional sketches consisting of geometric primitives (e.g., line segments, arcs) and explicit constraints between them (e.g., coincidence, perpendicularity) that form the basis for three-dimensional construction operations. Training machine learning models to reason about and synthesize parametric CAD designs has the potential to reduce design time and enable new design workflows. Additionally, parametric CAD designs can be viewed as instances of constraint programming and they offer a well-scoped test bed for exploring ideas in program synthesis and induction. To facilitate this research, we introduce SketchGraphs, a collection of 15 million sketches extracted from real-world CAD models coupled with an open-source data processing pipeline. Each sketch is represented as a geometric constraint graph where edges denote designer-imposed geometric relationships between primitives, the nodes of the graph. We demonstrate and establish benchmarks for two use cases of the dataset: generative modeling of sketches and conditional generation of likely constraints given unconstrained geometry.
Discrete Object Generation with Reversible Inductive Construction
Jul 18, 2019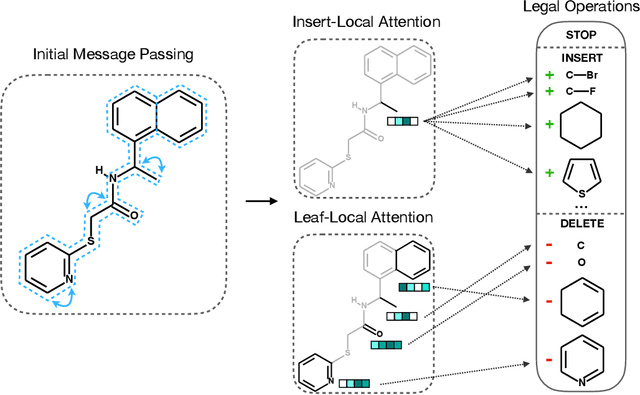
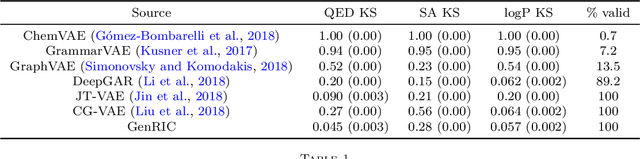

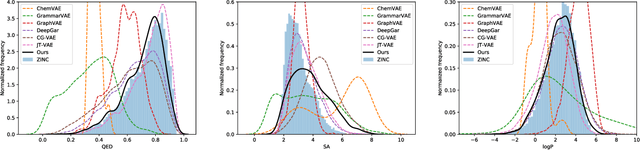
The success of generative modeling in continuous domains has led to a surge of interest in generating discrete data such as molecules, source code, and graphs. However, construction histories for these discrete objects are typically not unique and so generative models must reason about intractably large spaces in order to learn. Additionally, structured discrete domains are often characterized by strict constraints on what constitutes a valid object and generative models must respect these requirements in order to produce useful novel samples. Here, we present a generative model for discrete objects employing a Markov chain where transitions are restricted to a set of local operations that preserve validity. Building off of generative interpretations of denoising autoencoders, the Markov chain alternates between producing 1) a sequence of corrupted objects that are valid but not from the data distribution, and 2) a learned reconstruction distribution that attempts to fix the corruptions while also preserving validity. This approach constrains the generative model to only produce valid objects, requires the learner to only discover local modifications to the objects, and avoids marginalization over an unknown and potentially large space of construction histories. We evaluate the proposed approach on two highly structured discrete domains, molecules and Laman graphs, and find that it compares favorably to alternative methods at capturing distributional statistics for a host of semantically relevant metrics.
Continual Learning in Generative Adversarial Nets
May 23, 2017



Developments in deep generative models have allowed for tractable learning of high-dimensional data distributions. While the employed learning procedures typically assume that training data is drawn i.i.d. from the distribution of interest, it may be desirable to model distinct distributions which are observed sequentially, such as when different classes are encountered over time. Although conditional variations of deep generative models permit multiple distributions to be modeled by a single network in a disentangled fashion, they are susceptible to catastrophic forgetting when the distributions are encountered sequentially. In this paper, we adapt recent work in reducing catastrophic forgetting to the task of training generative adversarial networks on a sequence of distinct distributions, enabling continual generative modeling.
Learning from Maps: Visual Common Sense for Autonomous Driving
Dec 07, 2016



Today's autonomous vehicles rely extensively on high-definition 3D maps to navigate the environment. While this approach works well when these maps are completely up-to-date, safe autonomous vehicles must be able to corroborate the map's information via a real time sensor-based system. Our goal in this work is to develop a model for road layout inference given imagery from on-board cameras, without any reliance on high-definition maps. However, no sufficient dataset for training such a model exists. Here, we leverage the availability of standard navigation maps and corresponding street view images to construct an automatically labeled, large-scale dataset for this complex scene understanding problem. By matching road vectors and metadata from navigation maps with Google Street View images, we can assign ground truth road layout attributes (e.g., distance to an intersection, one-way vs. two-way street) to the images. We then train deep convolutional networks to predict these road layout attributes given a single monocular RGB image. Experimental evaluation demonstrates that our model learns to correctly infer the road attributes using only panoramas captured by car-mounted cameras as input. Additionally, our results indicate that this method may be suitable to the novel application of recommending safety improvements to infrastructure (e.g., suggesting an alternative speed limit for a street).
LSUN: Construction of a Large-scale Image Dataset using Deep Learning with Humans in the Loop
Jun 04, 2016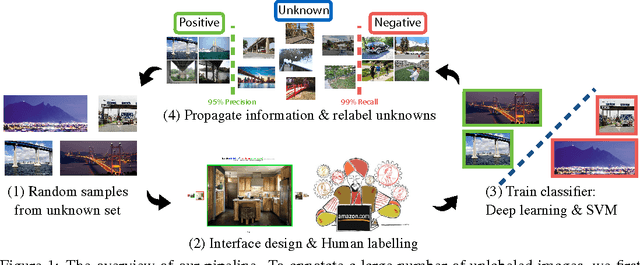

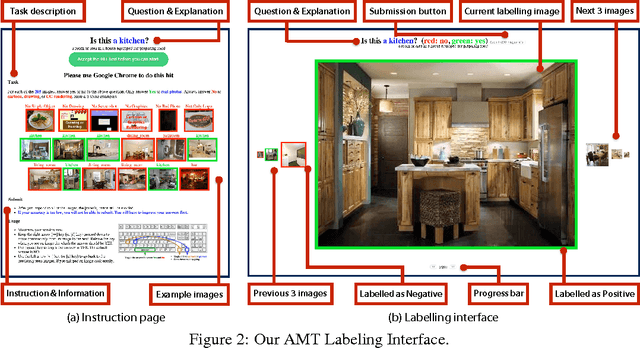
While there has been remarkable progress in the performance of visual recognition algorithms, the state-of-the-art models tend to be exceptionally data-hungry. Large labeled training datasets, expensive and tedious to produce, are required to optimize millions of parameters in deep network models. Lagging behind the growth in model capacity, the available datasets are quickly becoming outdated in terms of size and density. To circumvent this bottleneck, we propose to amplify human effort through a partially automated labeling scheme, leveraging deep learning with humans in the loop. Starting from a large set of candidate images for each category, we iteratively sample a subset, ask people to label them, classify the others with a trained model, split the set into positives, negatives, and unlabeled based on the classification confidence, and then iterate with the unlabeled set. To assess the effectiveness of this cascading procedure and enable further progress in visual recognition research, we construct a new image dataset, LSUN. It contains around one million labeled images for each of 10 scene categories and 20 object categories. We experiment with training popular convolutional networks and find that they achieve substantial performance gains when trained on this dataset.
DeepDriving: Learning Affordance for Direct Perception in Autonomous Driving
Sep 26, 2015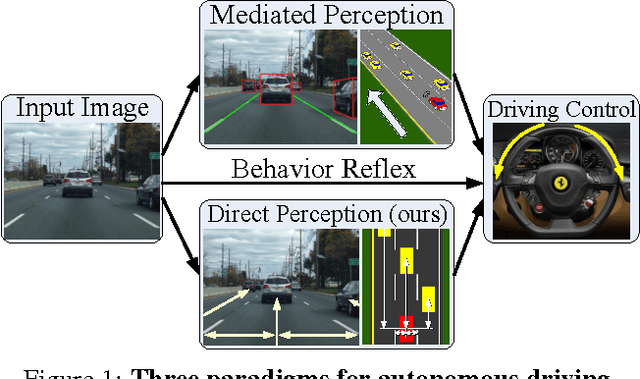
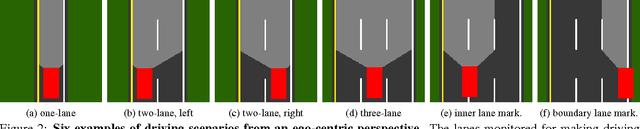

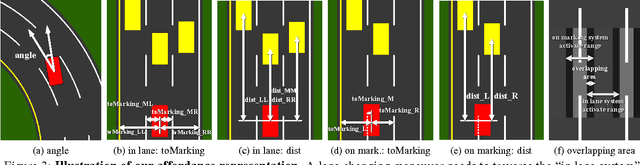
Today, there are two major paradigms for vision-based autonomous driving systems: mediated perception approaches that parse an entire scene to make a driving decision, and behavior reflex approaches that directly map an input image to a driving action by a regressor. In this paper, we propose a third paradigm: a direct perception approach to estimate the affordance for driving. We propose to map an input image to a small number of key perception indicators that directly relate to the affordance of a road/traffic state for driving. Our representation provides a set of compact yet complete descriptions of the scene to enable a simple controller to drive autonomously. Falling in between the two extremes of mediated perception and behavior reflex, we argue that our direct perception representation provides the right level of abstraction. To demonstrate this, we train a deep Convolutional Neural Network using recording from 12 hours of human driving in a video game and show that our model can work well to drive a car in a very diverse set of virtual environments. We also train a model for car distance estimation on the KITTI dataset. Results show that our direct perception approach can generalize well to real driving images. Source code and data are available on our project website.