 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Autonomous Mathematics Research
Feb 12, 2026Recent advances in foundational models have yielded reasoning systems capable of achieving a gold-medal standard at the International Mathematical Olympiad. The transition from competition-level problem-solving to professional research, however, requires navigating vast literature and constructing long-horizon proofs. In this work, we introduce Aletheia, a math research agent that iteratively generates, verifies, and revises solutions end-to-end in natural language. Specifically, Aletheia is powered by an advanced version of Gemini Deep Think for challenging reasoning problems, a novel inference-time scaling law that extends beyond Olympiad-level problems, and intensive tool use to navigate the complexities of mathematical research. We demonstrate the capability of Aletheia from Olympiad problems to PhD-level exercises and most notably, through several distinct milestones in AI-assisted mathematics research: (a) a research paper (Feng26) generated by AI without any human intervention in calculating certain structure constants in arithmetic geometry called eigenweights; (b) a research paper (LeeSeo26) demonstrating human-AI collaboration in proving bounds on systems of interacting particles called independent sets; and (c) an extensive semi-autonomous evaluation (Feng et al., 2026a) of 700 open problems on Bloom's Erdos Conjectures database, including autonomous solutions to four open questions. In order to help the public better understand the developments pertaining to AI and mathematics, we suggest quantifying standard levels of autonomy and novelty of AI-assisted results, as well as propose a novel concept of human-AI interaction cards for transparency. We conclude with reflections on human-AI collaboration in mathematics and share all prompts as well as model outputs at https://github.com/google-deepmind/superhuman/tree/main/aletheia.
MotionLM: Multi-Agent Motion Forecasting as Language Modeling
Sep 28, 2023Reliable forecasting of the future behavior of road agents is a critical component to safe planning in autonomous vehicles. Here, we represent continuous trajectories as sequences of discrete motion tokens and cast multi-agent motion prediction as a language modeling task over this domain. Our model, MotionLM, provides several advantages: First, it does not require anchors or explicit latent variable optimization to learn multimodal distributions. Instead, we leverage a single standard language modeling objective, maximizing the average log probability over sequence tokens. Second, our approach bypasses post-hoc interaction heuristics where individual agent trajectory generation is conducted prior to interactive scoring. Instead, MotionLM produces joint distributions over interactive agent futures in a single autoregressive decoding process. In addition, the model's sequential factorization enables temporally causal conditional rollouts. The proposed approach establishes new state-of-the-art performance for multi-agent motion prediction on the Waymo Open Motion Dataset, ranking 1st on the interactive challenge leaderboard.
Wayformer: Motion Forecasting via Simple & Efficient Attention Networks
Jul 12, 2022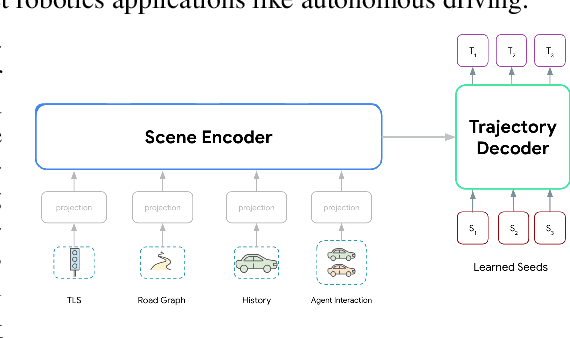
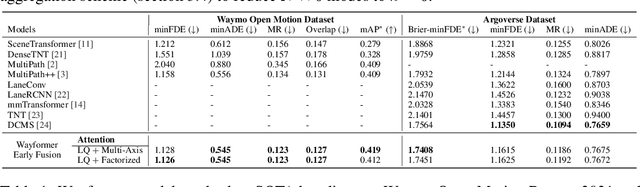
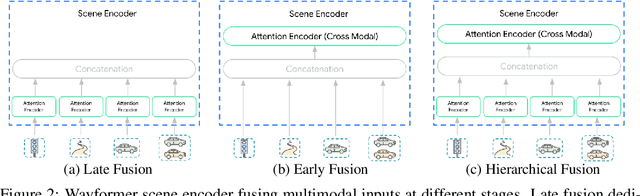
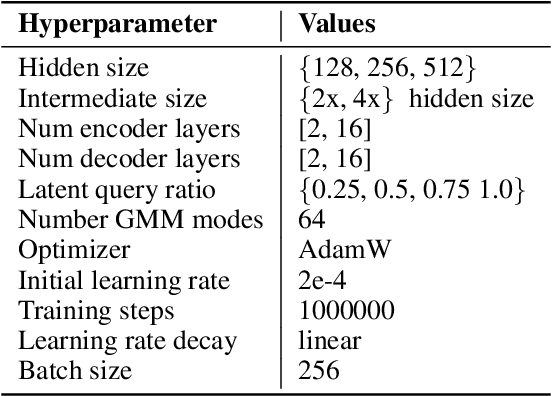
Motion forecasting for autonomous driving is a challenging task because complex driving scenarios result in a heterogeneous mix of static and dynamic inputs. It is an open problem how best to represent and fuse information about road geometry, lane connectivity, time-varying traffic light state, and history of a dynamic set of agents and their interactions into an effective encoding. To model this diverse set of input features, many approaches proposed to design an equally complex system with a diverse set of modality specific modules. This results in systems that are difficult to scale, extend, or tune in rigorous ways to trade off quality and efficiency. In this paper, we present Wayformer, a family of attention based architectures for motion forecasting that are simple and homogeneous. Wayformer offers a compact model description consisting of an attention based scene encoder and a decoder. In the scene encoder we study the choice of early, late and hierarchical fusion of the input modalities. For each fusion type we explore strategies to tradeoff efficiency and quality via factorized attention or latent query attention. We show that early fusion, despite its simplicity of construction, is not only modality agnostic but also achieves state-of-the-art results on both Waymo Open MotionDataset (WOMD) and Argoverse leaderboards, demonstrating the effectiveness of our design philosophy
VN-Transformer: Rotation-Equivariant Attention for Vector Neurons
Jun 08, 2022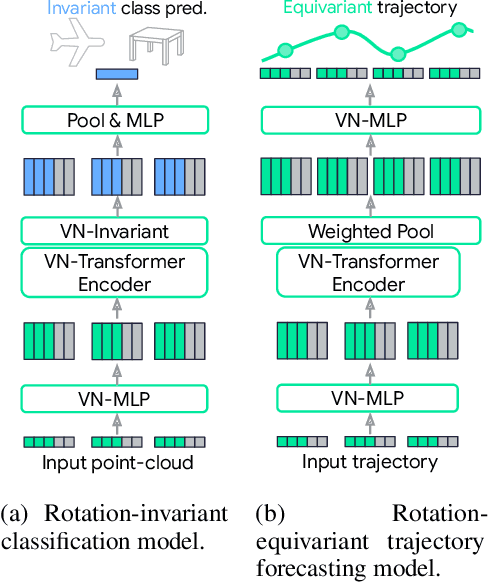
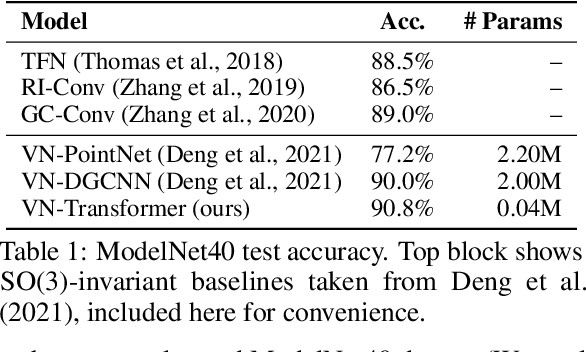

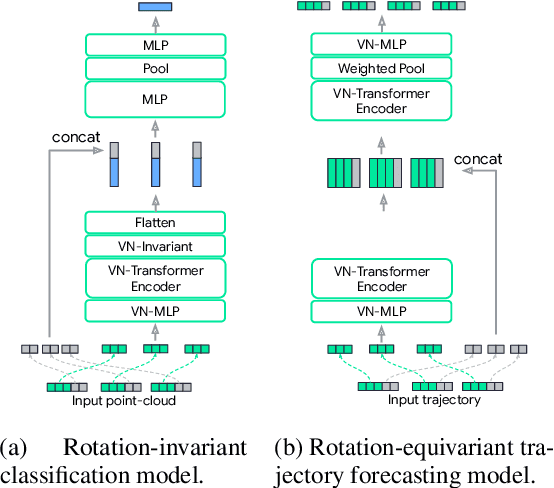
Rotation equivariance is a desirable property in many practical applications such as motion forecasting and 3D perception, where it can offer benefits like sample efficiency, better generalization, and robustness to input perturbations. Vector Neurons (VN) is a recently developed framework offering a simple yet effective approach for deriving rotation-equivariant analogs of standard machine learning operations by extending one-dimensional scalar neurons to three-dimensional "vector neurons." We introduce a novel "VN-Transformer" architecture to address several shortcomings of the current VN models. Our contributions are: $(i)$ we derive a rotation-equivariant attention mechanism which eliminates the need for the heavy feature preprocessing required by the original Vector Neurons models; $(ii)$ we extend the VN framework to support non-spatial attributes, expanding the applicability of these models to real-world datasets; $(iii)$ we derive a rotation-equivariant mechanism for multi-scale reduction of point-cloud resolution, greatly speeding up inference and training; $(iv)$ we show that small tradeoffs in equivariance ($\epsilon$-approximate equivariance) can be used to obtain large improvements in numerical stability and training robustness on accelerated hardware, and we bound the propagation of equivariance violations in our models. Finally, we apply our VN-Transformer to 3D shape classification and motion forecasting with compelling results.
MultiPath++: Efficient Information Fusion and Trajectory Aggregation for Behavior Prediction
Dec 22, 2021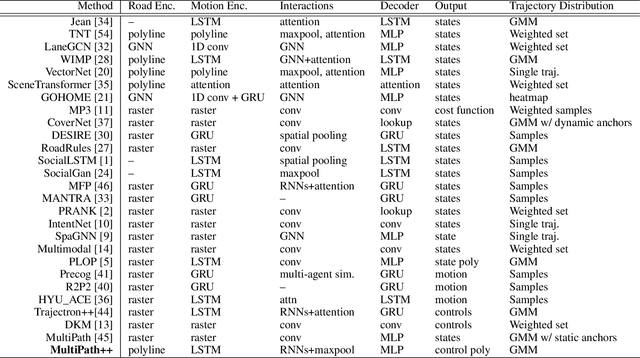
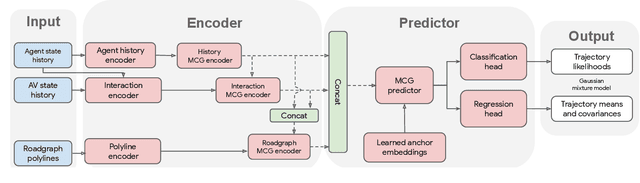
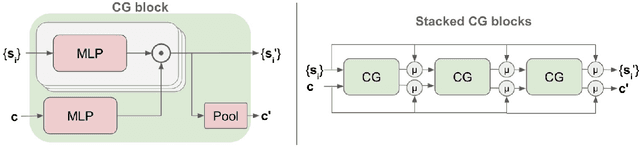
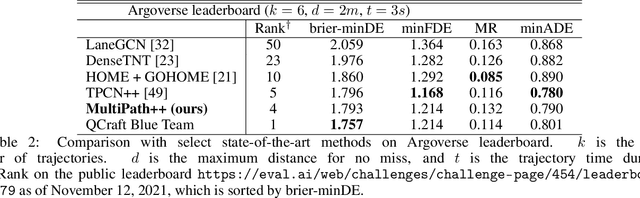
Predicting the future behavior of road users is one of the most challenging and important problems in autonomous driving. Applying deep learning to this problem requires fusing heterogeneous world state in the form of rich perception signals and map information, and inferring highly multi-modal distributions over possible futures. In this paper, we present MultiPath++, a future prediction model that achieves state-of-the-art performance on popular benchmarks. MultiPath++ improves the MultiPath architecture by revisiting many design choices. The first key design difference is a departure from dense image-based encoding of the input world state in favor of a sparse encoding of heterogeneous scene elements: MultiPath++ consumes compact and efficient polylines to describe road features, and raw agent state information directly (e.g., position, velocity, acceleration). We propose a context-aware fusion of these elements and develop a reusable multi-context gating fusion component. Second, we reconsider the choice of pre-defined, static anchors, and develop a way to learn latent anchor embeddings end-to-end in the model. Lastly, we explore ensembling and output aggregation techniques -- common in other ML domains -- and find effective variants for our probabilistic multimodal output representation. We perform an extensive ablation on these design choices, and show that our proposed model achieves state-of-the-art performance on the Argoverse Motion Forecasting Competition and the Waymo Open Dataset Motion Prediction Challenge.