 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWOD-E2E: Waymo Open Dataset for End-to-End Driving in Challenging Long-tail Scenarios
Oct 30, 2025Vision-based end-to-end (E2E) driving has garnered significant interest in the research community due to its scalability and synergy with multimodal large language models (MLLMs). However, current E2E driving benchmarks primarily feature nominal scenarios, failing to adequately test the true potential of these systems. Furthermore, existing open-loop evaluation metrics often fall short in capturing the multi-modal nature of driving or effectively evaluating performance in long-tail scenarios. To address these gaps, we introduce the Waymo Open Dataset for End-to-End Driving (WOD-E2E). WOD-E2E contains 4,021 driving segments (approximately 12 hours), specifically curated for challenging long-tail scenarios that that are rare in daily life with an occurring frequency of less than 0.03%. Concretely, each segment in WOD-E2E includes the high-level routing information, ego states, and 360-degree camera views from 8 surrounding cameras. To evaluate the E2E driving performance on these long-tail situations, we propose a novel open-loop evaluation metric: Rater Feedback Score (RFS). Unlike conventional metrics that measure the distance between predicted way points and the logs, RFS measures how closely the predicted trajectory matches rater-annotated trajectory preference labels. We have released rater preference labels for all WOD-E2E validation set segments, while the held out test set labels have been used for the 2025 WOD-E2E Challenge. Through our work, we aim to foster state of the art research into generalizable, robust, and safe end-to-end autonomous driving agents capable of handling complex real-world situations.
MotionDiffuser: Controllable Multi-Agent Motion Prediction using Diffusion
Jun 05, 2023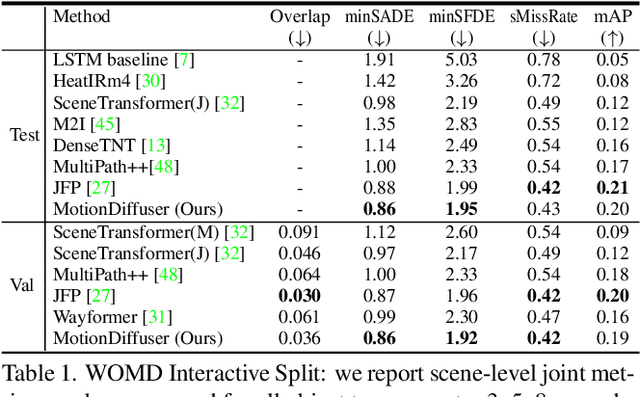
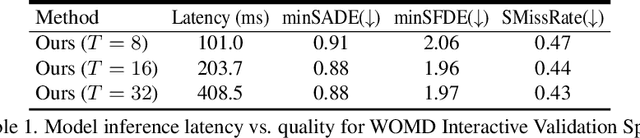
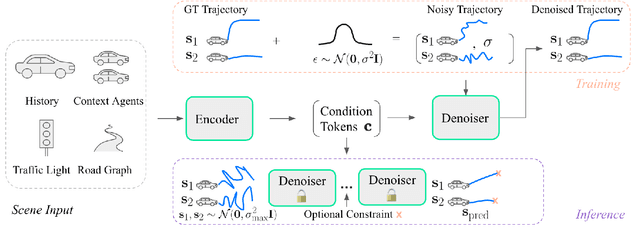
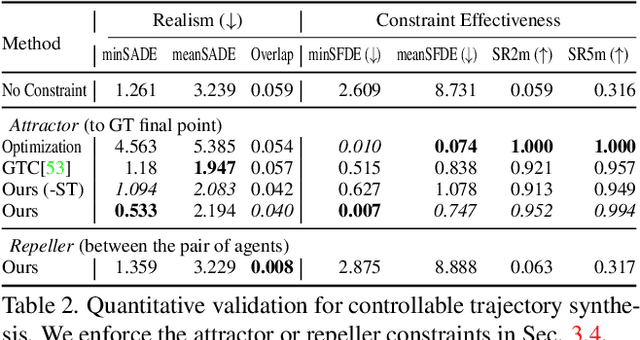
We present MotionDiffuser, a diffusion based representation for the joint distribution of future trajectories over multiple agents. Such representation has several key advantages: first, our model learns a highly multimodal distribution that captures diverse future outcomes. Second, the simple predictor design requires only a single L2 loss training objective, and does not depend on trajectory anchors. Third, our model is capable of learning the joint distribution for the motion of multiple agents in a permutation-invariant manner. Furthermore, we utilize a compressed trajectory representation via PCA, which improves model performance and allows for efficient computation of the exact sample log probability. Subsequently, we propose a general constrained sampling framework that enables controlled trajectory sampling based on differentiable cost functions. This strategy enables a host of applications such as enforcing rules and physical priors, or creating tailored simulation scenarios. MotionDiffuser can be combined with existing backbone architectures to achieve top motion forecasting results. We obtain state-of-the-art results for multi-agent motion prediction on the Waymo Open Motion Dataset.
CausalAgents: A Robustness Benchmark for Motion Forecasting using Causal Relationships
Jul 07, 2022


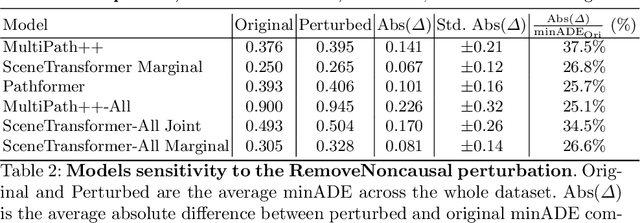
As machine learning models become increasingly prevalent in motion forecasting systems for autonomous vehicles (AVs), it is critical that we ensure that model predictions are safe and reliable. However, exhaustively collecting and labeling the data necessary to fully test the long tail of rare and challenging scenarios is difficult and expensive. In this work, we construct a new benchmark for evaluating and improving model robustness by applying perturbations to existing data. Specifically, we conduct an extensive labeling effort to identify causal agents, or agents whose presence influences human driver behavior in any way, in the Waymo Open Motion Dataset (WOMD), and we use these labels to perturb the data by deleting non-causal agents from the scene. We then evaluate a diverse set of state-of-the-art deep-learning model architectures on our proposed benchmark and find that all models exhibit large shifts under perturbation. Under non-causal perturbations, we observe a $25$-$38\%$ relative change in minADE as compared to the original. We then investigate techniques to improve model robustness, including increasing the training dataset size and using targeted data augmentations that drop agents throughout training. We plan to provide the causal agent labels as an additional attribute to WOMD and release the robustness benchmarks to aid the community in building more reliable and safe deep-learning models for motion forecasting.
VN-Transformer: Rotation-Equivariant Attention for Vector Neurons
Jun 08, 2022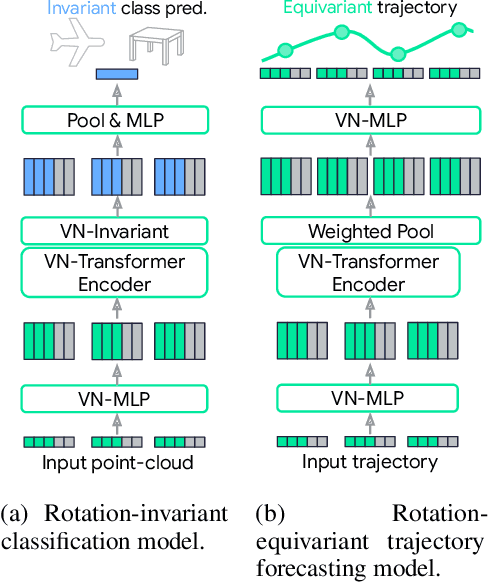
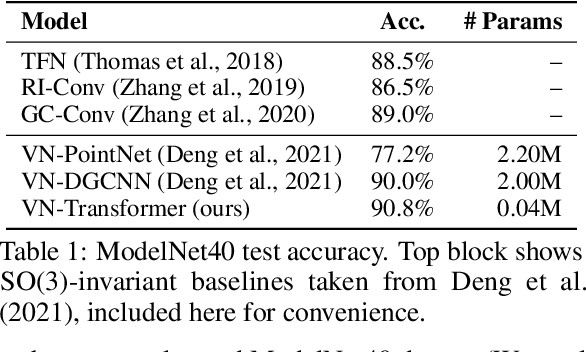

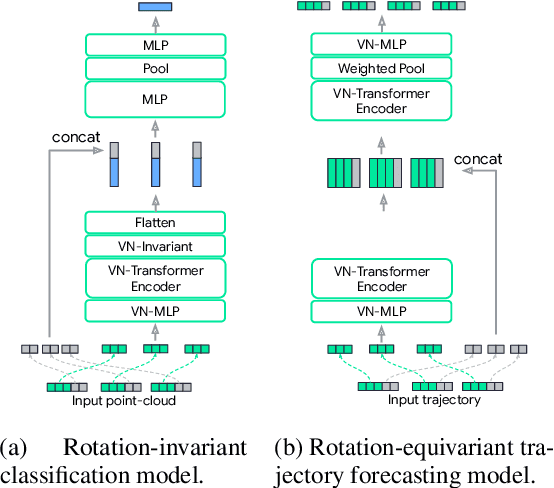
Rotation equivariance is a desirable property in many practical applications such as motion forecasting and 3D perception, where it can offer benefits like sample efficiency, better generalization, and robustness to input perturbations. Vector Neurons (VN) is a recently developed framework offering a simple yet effective approach for deriving rotation-equivariant analogs of standard machine learning operations by extending one-dimensional scalar neurons to three-dimensional "vector neurons." We introduce a novel "VN-Transformer" architecture to address several shortcomings of the current VN models. Our contributions are: $(i)$ we derive a rotation-equivariant attention mechanism which eliminates the need for the heavy feature preprocessing required by the original Vector Neurons models; $(ii)$ we extend the VN framework to support non-spatial attributes, expanding the applicability of these models to real-world datasets; $(iii)$ we derive a rotation-equivariant mechanism for multi-scale reduction of point-cloud resolution, greatly speeding up inference and training; $(iv)$ we show that small tradeoffs in equivariance ($\epsilon$-approximate equivariance) can be used to obtain large improvements in numerical stability and training robustness on accelerated hardware, and we bound the propagation of equivariance violations in our models. Finally, we apply our VN-Transformer to 3D shape classification and motion forecasting with compelling results.
StopNet: Scalable Trajectory and Occupancy Prediction for Urban Autonomous Driving
Jun 02, 2022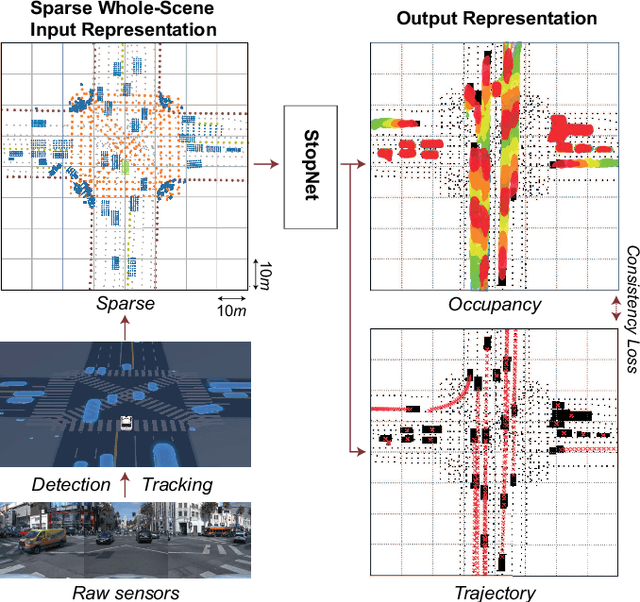
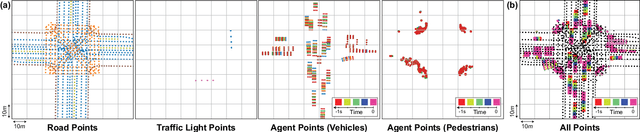
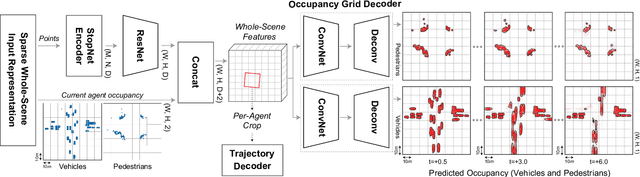
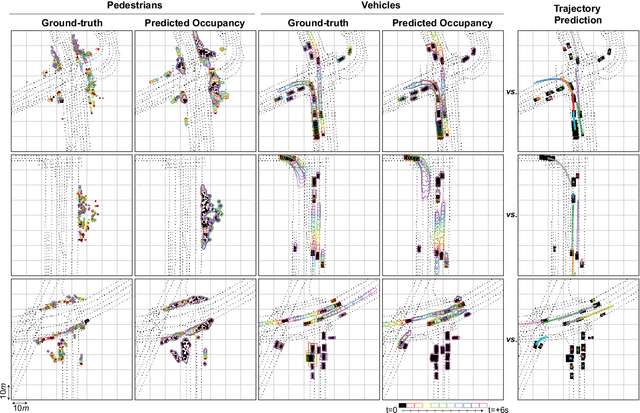
We introduce a motion forecasting (behavior prediction) method that meets the latency requirements for autonomous driving in dense urban environments without sacrificing accuracy. A whole-scene sparse input representation allows StopNet to scale to predicting trajectories for hundreds of road agents with reliable latency. In addition to predicting trajectories, our scene encoder lends itself to predicting whole-scene probabilistic occupancy grids, a complementary output representation suitable for busy urban environments. Occupancy grids allow the AV to reason collectively about the behavior of groups of agents without processing their individual trajectories. We demonstrate the effectiveness of our sparse input representation and our model in terms of computation and accuracy over three datasets. We further show that co-training consistent trajectory and occupancy predictions improves upon state-of-the-art performance under standard metrics.
Occupancy Flow Fields for Motion Forecasting in Autonomous Driving
Mar 08, 2022

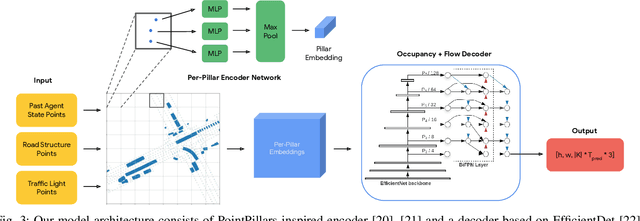

We propose Occupancy Flow Fields, a new representation for motion forecasting of multiple agents, an important task in autonomous driving. Our representation is a spatio-temporal grid with each grid cell containing both the probability of the cell being occupied by any agent, and a two-dimensional flow vector representing the direction and magnitude of the motion in that cell. Our method successfully mitigates shortcomings of the two most commonly-used representations for motion forecasting: trajectory sets and occupancy grids. Although occupancy grids efficiently represent the probabilistic location of many agents jointly, they do not capture agent motion and lose the agent identities. To this end, we propose a deep learning architecture that generates Occupancy Flow Fields with the help of a new flow trace loss that establishes consistency between the occupancy and flow predictions. We demonstrate the effectiveness of our approach using three metrics on occupancy prediction, motion estimation, and agent ID recovery. In addition, we introduce the problem of predicting speculative agents, which are currently-occluded agents that may appear in the future through dis-occlusion or by entering the field of view. We report experimental results on a large in-house autonomous driving dataset and the public INTERACTION dataset, and show that our model outperforms state-of-the-art models.
Scene Transformer: A unified multi-task model for behavior prediction and planning
Jun 15, 2021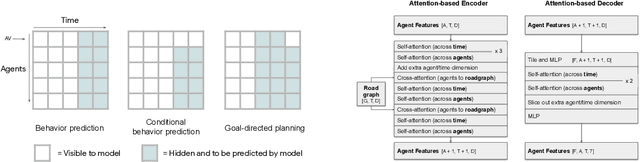
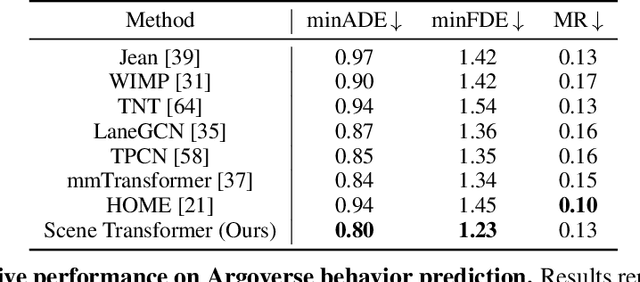
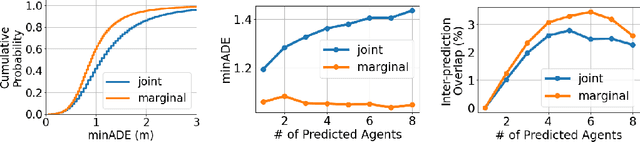
Predicting the future motion of multiple agents is necessary for planning in dynamic environments. This task is challenging for autonomous driving since agents (e.g., vehicles and pedestrians) and their associated behaviors may be diverse and influence each other. Most prior work has focused on first predicting independent futures for each agent based on all past motion, and then planning against these independent predictions. However, planning against fixed predictions can suffer from the inability to represent the future interaction possibilities between different agents, leading to sub-optimal planning. In this work, we formulate a model for predicting the behavior of all agents jointly in real-world driving environments in a unified manner. Inspired by recent language modeling approaches, we use a masking strategy as the query to our model, enabling one to invoke a single model to predict agent behavior in many ways, such as potentially conditioned on the goal or full future trajectory of the autonomous vehicle or the behavior of other agents in the environment. Our model architecture fuses heterogeneous world state in a unified Transformer architecture by employing attention across road elements, agent interactions and time steps. We evaluate our approach on autonomous driving datasets for behavior prediction, and achieve state-of-the-art performance. Our work demonstrates that formulating the problem of behavior prediction in a unified architecture with a masking strategy may allow us to have a single model that can perform multiple motion prediction and planning related tasks effectively.
Large Scale Interactive Motion Forecasting for Autonomous Driving : The Waymo Open Motion Dataset
Apr 20, 2021
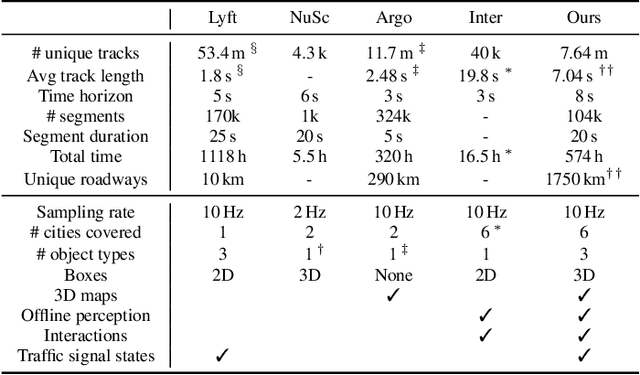
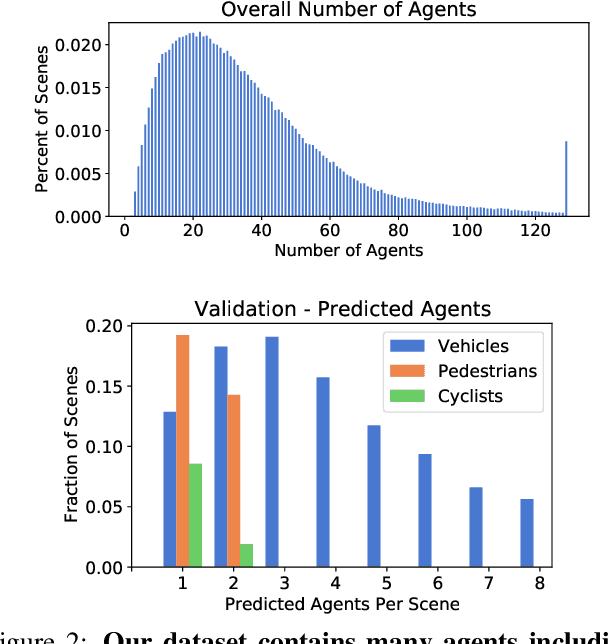
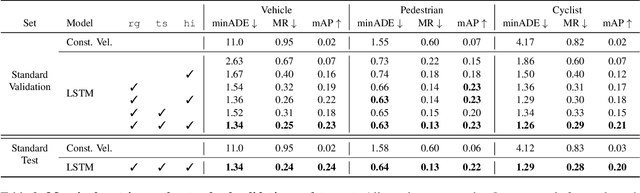
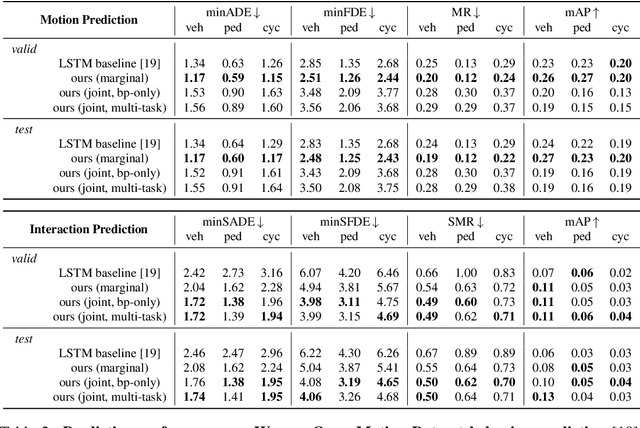
As autonomous driving systems mature, motion forecasting has received increasing attention as a critical requirement for planning. Of particular importance are interactive situations such as merges, unprotected turns, etc., where predicting individual object motion is not sufficient. Joint predictions of multiple objects are required for effective route planning. There has been a critical need for high-quality motion data that is rich in both interactions and annotation to develop motion planning models. In this work, we introduce the most diverse interactive motion dataset to our knowledge, and provide specific labels for interacting objects suitable for developing joint prediction models. With over 100,000 scenes, each 20 seconds long at 10 Hz, our new dataset contains more than 570 hours of unique data over 1750 km of roadways. It was collected by mining for interesting interactions between vehicles, pedestrians, and cyclists across six cities within the United States. We use a high-accuracy 3D auto-labeling system to generate high quality 3D bounding boxes for each road agent, and provide corresponding high definition 3D maps for each scene. Furthermore, we introduce a new set of metrics that provides a comprehensive evaluation of both single agent and joint agent interaction motion forecasting models. Finally, we provide strong baseline models for individual-agent prediction and joint-prediction. We hope that this new large-scale interactive motion dataset will provide new opportunities for advancing motion forecasting models.