 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePriorVLA: Prior-Preserving Adaptation for Vision-Language-Action Models
May 11, 2026Large-scale pretraining has made Vision-Language-Action (VLA) models promising foundations for generalist robot manipulation, yet adapting them to downstream tasks remains necessary. However, the common practice of full fine-tuning treats pretraining as initialization and can shift broad priors toward narrow training-distribution patterns. We propose PriorVLA, a novel framework that preserves pretrained priors and learns to leverage them for effective adaptation. PriorVLA keeps a frozen Prior Expert as a read-only prior source and trains an Adaptation Expert for downstream specialization. Expert Queries capture scene priors from the pretrained VLM and motor priors from the Prior Expert, integrating both into the Adaptation Expert to guide adaptation. Together, PriorVLA updates only 25% of the parameters updated by full fine-tuning. Across RoboTwin 2.0, LIBERO, and real-world tasks, PriorVLA achieves stronger overall performance than full fine-tuning and state-of-the-art VLA baselines, with the largest gains under out-of-distribution (OOD) and few-shot settings. PriorVLA improves over pi0.5 by 11 points on RoboTwin 2.0-Hard and achieves 99.1% average success on LIBERO. Across eight real-world tasks and two embodiments, PriorVLA reaches 81% in-distribution (ID) and 57% OOD success with standard data. With only 10 demonstrations per task, PriorVLA reaches 48% ID and 32% OOD success, surpassing pi0.5 by 24 and 22 points, respectively.
Mani-GPT: A Generative Model for Interactive Robotic Manipulation
Aug 08, 2023



In real-world scenarios, human dialogues are multi-round and diverse. Furthermore, human instructions can be unclear and human responses are unrestricted. Interactive robots face difficulties in understanding human intents and generating suitable strategies for assisting individuals through manipulation. In this article, we propose Mani-GPT, a Generative Pre-trained Transformer (GPT) for interactive robotic manipulation. The proposed model has the ability to understand the environment through object information, understand human intent through dialogues, generate natural language responses to human input, and generate appropriate manipulation plans to assist the human. This makes the human-robot interaction more natural and humanized. In our experiment, Mani-GPT outperforms existing algorithms with an accuracy of 84.6% in intent recognition and decision-making for actions. Furthermore, it demonstrates satisfying performance in real-world dialogue tests with users, achieving an average response accuracy of 70%.
Virtual Reality Based Robot Teleoperation via Human-Scene Interaction
Aug 02, 2023



Robot teleoperation gains great success in various situations, including chemical pollution rescue, disaster relief, and long-distance manipulation. In this article, we propose a virtual reality (VR) based robot teleoperation system to achieve more efficient and natural interaction with humans in different scenes. A user-friendly VR interface is designed to help users interact with a desktop scene using their hands efficiently and intuitively. To improve user experience and reduce workload, we simulate the process in the physics engine to help build a preview of the scene after manipulation in the virtual scene before execution. We conduct experiments with different users and compare our system with a direct control method across several teleoperation tasks. The user study demonstrates that the proposed system enables users to perform operations more instinctively with a lighter mental workload. Users can perform pick-and-place and object-stacking tasks in a considerably short time, even for beginners. Our code is available at https://github.com/lingxiaomeng/VR_Teleoperation_Gen3.
CausalAgents: A Robustness Benchmark for Motion Forecasting using Causal Relationships
Jul 07, 2022


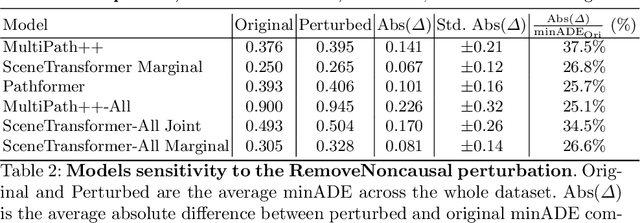
As machine learning models become increasingly prevalent in motion forecasting systems for autonomous vehicles (AVs), it is critical that we ensure that model predictions are safe and reliable. However, exhaustively collecting and labeling the data necessary to fully test the long tail of rare and challenging scenarios is difficult and expensive. In this work, we construct a new benchmark for evaluating and improving model robustness by applying perturbations to existing data. Specifically, we conduct an extensive labeling effort to identify causal agents, or agents whose presence influences human driver behavior in any way, in the Waymo Open Motion Dataset (WOMD), and we use these labels to perturb the data by deleting non-causal agents from the scene. We then evaluate a diverse set of state-of-the-art deep-learning model architectures on our proposed benchmark and find that all models exhibit large shifts under perturbation. Under non-causal perturbations, we observe a $25$-$38\%$ relative change in minADE as compared to the original. We then investigate techniques to improve model robustness, including increasing the training dataset size and using targeted data augmentations that drop agents throughout training. We plan to provide the causal agent labels as an additional attribute to WOMD and release the robustness benchmarks to aid the community in building more reliable and safe deep-learning models for motion forecasting.
Collaborative Learning for Deep Neural Networks
May 30, 2018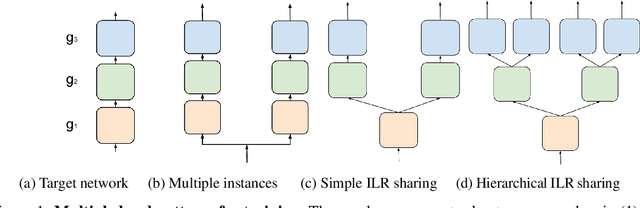

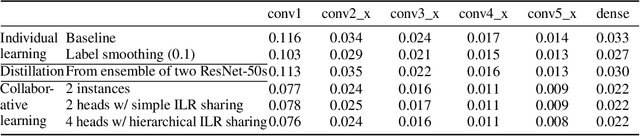
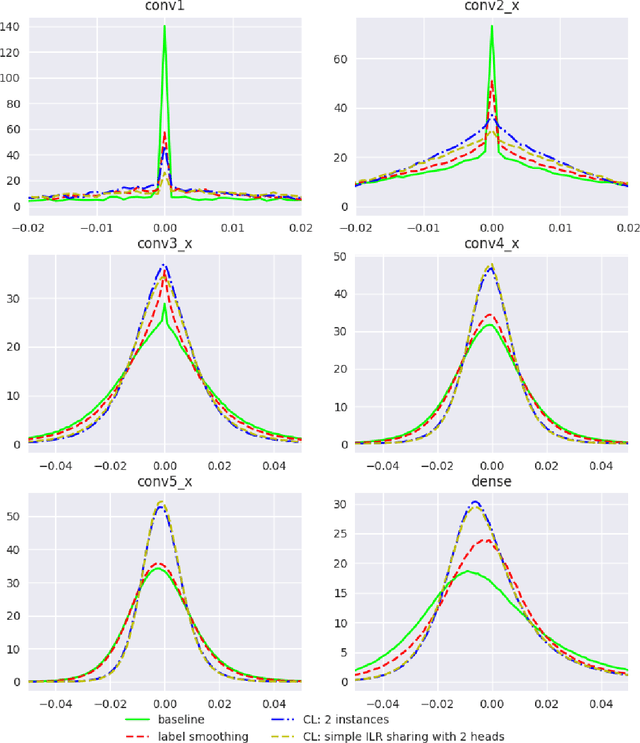
We introduce collaborative learning in which multiple classifier heads of the same network are simultaneously trained on the same training data to improve generalization and robustness to label noise with no extra inference cost. It acquires the strengths from auxiliary training, multi-task learning and knowledge distillation. There are two important mechanisms involved in collaborative learning. First, the consensus of multiple views from different classifier heads on the same example provides supplementary information as well as regularization to each classifier, thereby improving generalization. Second, intermediate-level representation (ILR) sharing with backpropagation rescaling aggregates the gradient flows from all heads, which not only reduces training computational complexity, but also facilitates supervision to the shared layers. The empirical results on CIFAR and ImageNet datasets demonstrate that deep neural networks learned as a group in a collaborative way significantly reduce the generalization error and increase the robustness to label noise.
Wide & Deep Learning for Recommender Systems
Jun 24, 2016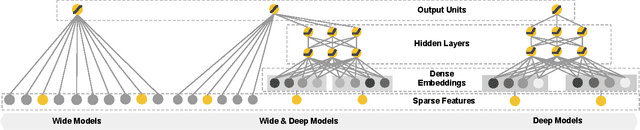
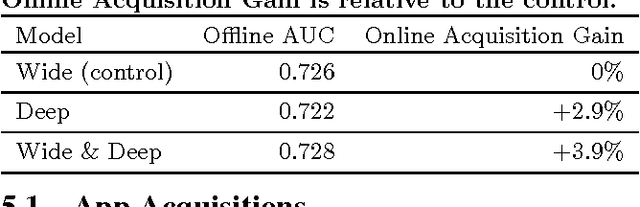
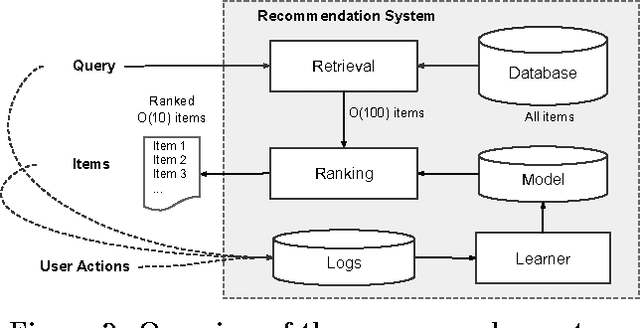

Generalized linear models with nonlinear feature transformations are widely used for large-scale regression and classification problems with sparse inputs. Memorization of feature interactions through a wide set of cross-product feature transformations are effective and interpretable, while generalization requires more feature engineering effort. With less feature engineering, deep neural networks can generalize better to unseen feature combinations through low-dimensional dense embeddings learned for the sparse features. However, deep neural networks with embeddings can over-generalize and recommend less relevant items when the user-item interactions are sparse and high-rank. In this paper, we present Wide & Deep learning---jointly trained wide linear models and deep neural networks---to combine the benefits of memorization and generalization for recommender systems. We productionized and evaluated the system on Google Play, a commercial mobile app store with over one billion active users and over one million apps. Online experiment results show that Wide & Deep significantly increased app acquisitions compared with wide-only and deep-only models. We have also open-sourced our implementation in TensorFlow.