 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Fall Detection and Response using Wi-Fi Sensing and Mobile Companion Robot
Jul 17, 2024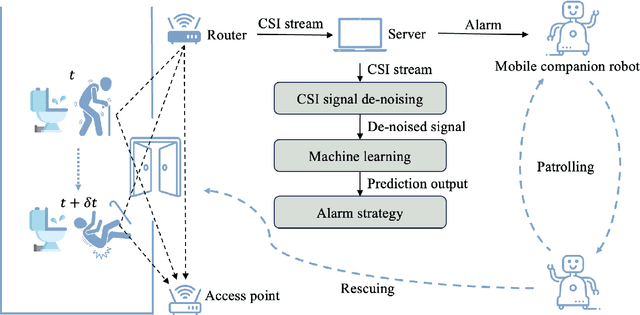
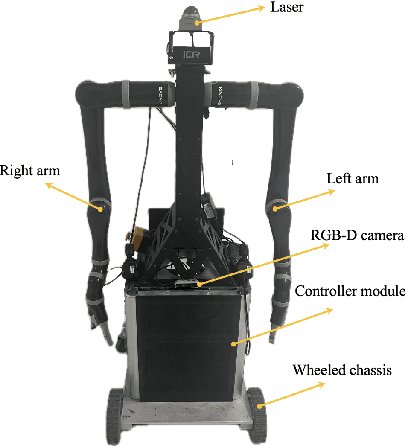
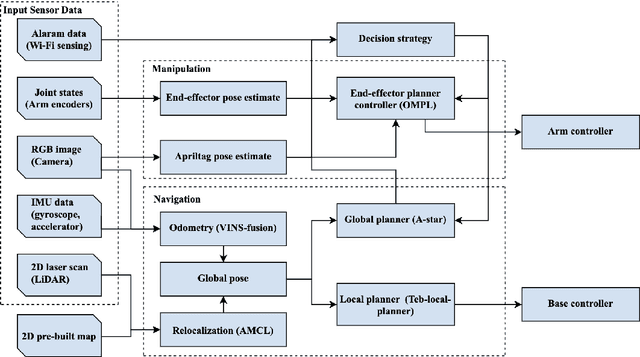
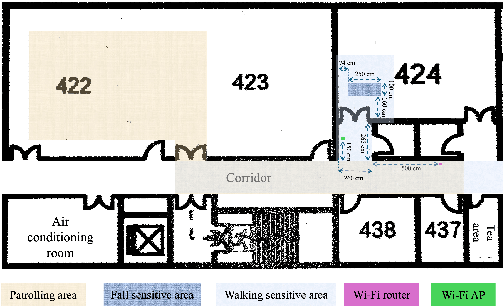
This paper presents a collaborative fall detection and response system integrating Wi-Fi sensing with robotic assistance. The proposed system leverages channel state information (CSI) disruptions caused by movements to detect falls in non-line-of-sight (NLOS) scenarios, offering non-intrusive monitoring. Besides, a companion robot is utilized to provide assistance capabilities to navigate and respond to incidents autonomously, improving efficiency in providing assistance in various environments. The experimental results demonstrate the effectiveness of the proposed system in detecting falls and responding effectively.
Autonomous Multiple-Trolley Collection System with Nonholonomic Robots: Design, Control, and Implementation
Jan 16, 2024



The intricate and multi-stage task in dynamic public spaces like luggage trolley collection in airports presents both a promising opportunity and an ongoing challenge for automated service robots. Previous research has primarily focused on handling a single trolley or individual functional components, creating a gap in providing cost-effective and efficient solutions for practical scenarios. In this paper, we propose a mobile manipulation robot incorporated with an autonomy framework for the collection and transportation of multiple trolleys that can significantly enhance operational efficiency. We address the key challenges in the trolley collection problem through the novel design of the mechanical system and the vision-based control strategy. We design a lightweight manipulator and docking mechanism, optimized for the sequential stacking and transportation of multiple trolleys. Additionally, based on the Control Lyapunov Function and Control Barrier Function, we propose a novel vision-based control with the online Quadratic Programming which significantly improves the accuracy and efficiency of the collection process. The practical application of our system is demonstrated in real world scenarios, where it successfully executes multiple-trolley collection tasks.
Virtual Reality Based Robot Teleoperation via Human-Scene Interaction
Aug 02, 2023



Robot teleoperation gains great success in various situations, including chemical pollution rescue, disaster relief, and long-distance manipulation. In this article, we propose a virtual reality (VR) based robot teleoperation system to achieve more efficient and natural interaction with humans in different scenes. A user-friendly VR interface is designed to help users interact with a desktop scene using their hands efficiently and intuitively. To improve user experience and reduce workload, we simulate the process in the physics engine to help build a preview of the scene after manipulation in the virtual scene before execution. We conduct experiments with different users and compare our system with a direct control method across several teleoperation tasks. The user study demonstrates that the proposed system enables users to perform operations more instinctively with a lighter mental workload. Users can perform pick-and-place and object-stacking tasks in a considerably short time, even for beginners. Our code is available at https://github.com/lingxiaomeng/VR_Teleoperation_Gen3.
FabricFolding: Learning Efficient Fabric Folding without Expert Demonstrations
Mar 12, 2023Autonomous fabric manipulation is a challenging task due to complex dynamics and self-occlusion during fabric handling. An intuitive method of fabric folding manipulation involves obtaining a smooth and unfolded fabric configuration before the folding process begins. To achieve this goal, we propose an efficient dual-arm manipulation system that combines quasi-static (including pick & place and pick & drag) and dynamic fling actions to flexibly manipulate fabrics into unfolded and smooth structures. Once this is done, keypoints of the fabric are detected, enabling autonomous folding. We evaluate the effectiveness of our proposed system in real-world settings, where it consistently and reliably unfolds and folds various types of fabrics, including challenging situations such as long-sleeved T-shirts with most parts of sleeves tucked inside the garment. Our method exhibits high efficiency in fabric manipulation, even for complex fabric configurations. Our method achieves a coverage rate of 0.822 and a success rate of 0.88 for long-sleeved T-shirts folding.
Task-Oriented Grasp Prediction with Visual-Language Inputs
Feb 28, 2023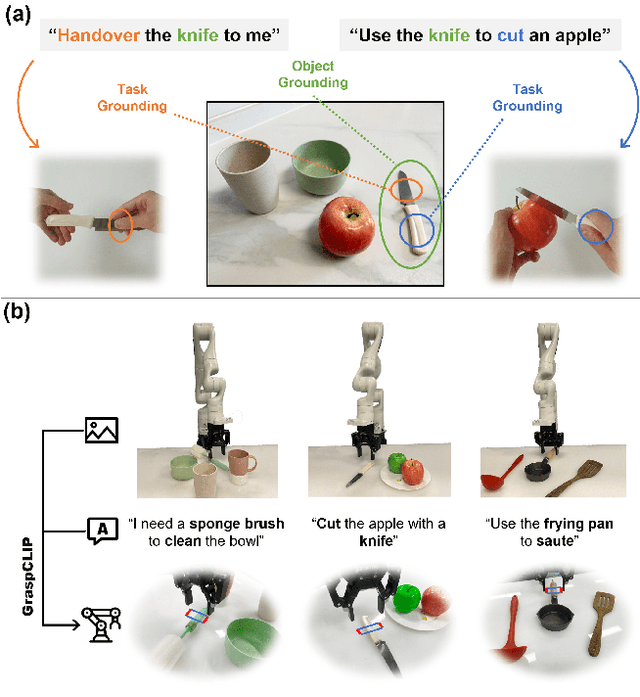
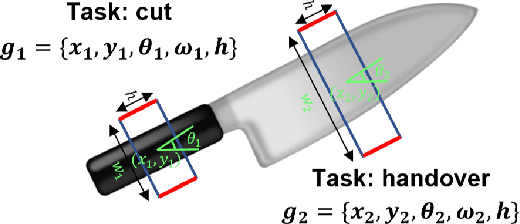
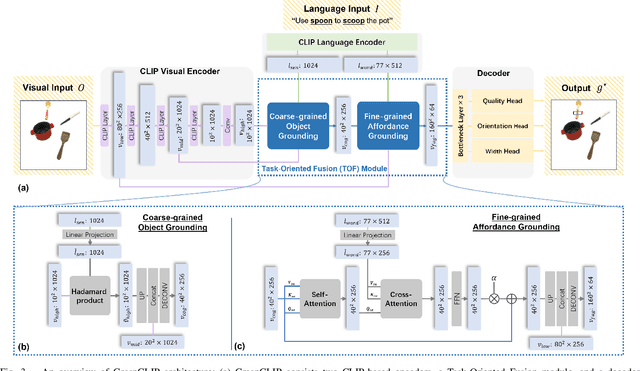
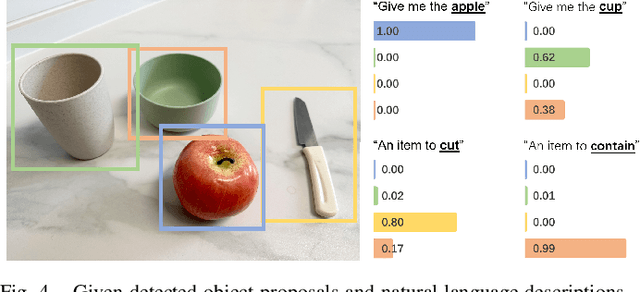
To perform household tasks, assistive robots receive commands in the form of user language instructions for tool manipulation. The initial stage involves selecting the intended tool (i.e., object grounding) and grasping it in a task-oriented manner (i.e., task grounding). Nevertheless, prior researches on visual-language grasping (VLG) focus on object grounding, while disregarding the fine-grained impact of tasks on object grasping. Task-incompatible grasping of a tool will inevitably limit the success of subsequent manipulation steps. Motivated by this problem, this paper proposes GraspCLIP, which addresses the challenge of task grounding in addition to object grounding to enable task-oriented grasp prediction with visual-language inputs. Evaluation on a custom dataset demonstrates that GraspCLIP achieves superior performance over established baselines with object grounding only. The effectiveness of the proposed method is further validated on an assistive robotic arm platform for grasping previously unseen kitchen tools given the task specification. Our presentation video is available at: https://www.youtube.com/watch?v=e1wfYQPeAXU.