 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArticulate3D: Zero-Shot Text-Driven 3D Object Posing
Aug 26, 2025We propose a training-free method, Articulate3D, to pose a 3D asset through language control. Despite advances in vision and language models, this task remains surprisingly challenging. To achieve this goal, we decompose the problem into two steps. We modify a powerful image-generator to create target images conditioned on the input image and a text instruction. We then align the mesh to the target images through a multi-view pose optimisation step. In detail, we introduce a self-attention rewiring mechanism (RSActrl) that decouples the source structure from pose within an image generative model, allowing it to maintain a consistent structure across varying poses. We observed that differentiable rendering is an unreliable signal for articulation optimisation; instead, we use keypoints to establish correspondences between input and target images. The effectiveness of Articulate3D is demonstrated across a diverse range of 3D objects and free-form text prompts, successfully manipulating poses while maintaining the original identity of the mesh. Quantitative evaluations and a comparative user study, in which our method was preferred over 85\% of the time, confirm its superiority over existing approaches. Project page:https://odeb1.github.io/articulate3d_page_deb/
As Firm As Their Foundations: Can open-sourced foundation models be used to create adversarial examples for downstream tasks?
Mar 19, 2024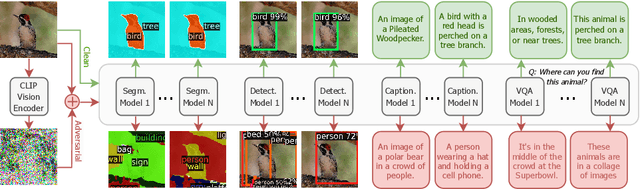
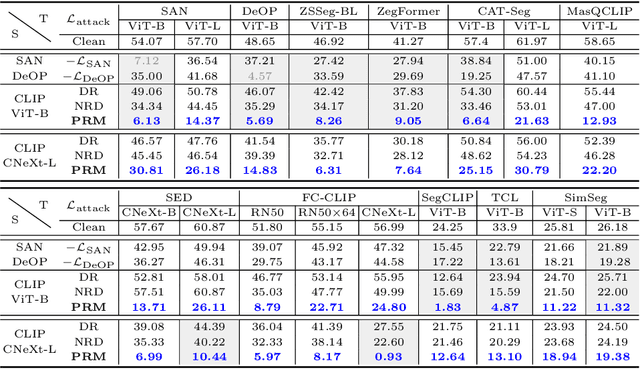
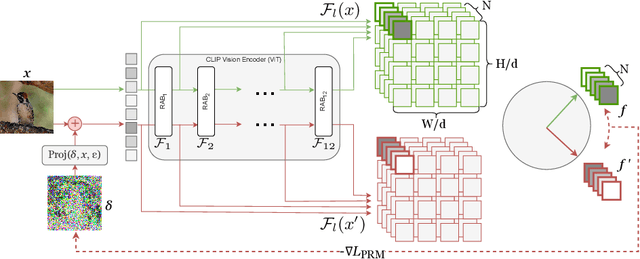
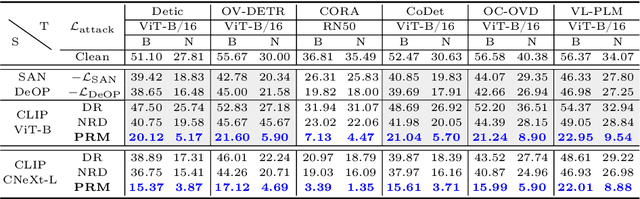
Foundation models pre-trained on web-scale vision-language data, such as CLIP, are widely used as cornerstones of powerful machine learning systems. While pre-training offers clear advantages for downstream learning, it also endows downstream models with shared adversarial vulnerabilities that can be easily identified through the open-sourced foundation model. In this work, we expose such vulnerabilities in CLIP's downstream models and show that foundation models can serve as a basis for attacking their downstream systems. In particular, we propose a simple yet effective adversarial attack strategy termed Patch Representation Misalignment (PRM). Solely based on open-sourced CLIP vision encoders, this method produces adversaries that simultaneously fool more than 20 downstream models spanning 4 common vision-language tasks (semantic segmentation, object detection, image captioning and visual question-answering). Our findings highlight the concerning safety risks introduced by the extensive usage of public foundational models in the development of downstream systems, calling for extra caution in these scenarios.
Autonomous Multiple-Trolley Collection System with Nonholonomic Robots: Design, Control, and Implementation
Jan 16, 2024



The intricate and multi-stage task in dynamic public spaces like luggage trolley collection in airports presents both a promising opportunity and an ongoing challenge for automated service robots. Previous research has primarily focused on handling a single trolley or individual functional components, creating a gap in providing cost-effective and efficient solutions for practical scenarios. In this paper, we propose a mobile manipulation robot incorporated with an autonomy framework for the collection and transportation of multiple trolleys that can significantly enhance operational efficiency. We address the key challenges in the trolley collection problem through the novel design of the mechanical system and the vision-based control strategy. We design a lightweight manipulator and docking mechanism, optimized for the sequential stacking and transportation of multiple trolleys. Additionally, based on the Control Lyapunov Function and Control Barrier Function, we propose a novel vision-based control with the online Quadratic Programming which significantly improves the accuracy and efficiency of the collection process. The practical application of our system is demonstrated in real world scenarios, where it successfully executes multiple-trolley collection tasks.
A Survey on Transferability of Adversarial Examples across Deep Neural Networks
Oct 26, 2023

The emergence of Deep Neural Networks (DNNs) has revolutionized various domains, enabling the resolution of complex tasks spanning image recognition, natural language processing, and scientific problem-solving. However, this progress has also exposed a concerning vulnerability: adversarial examples. These crafted inputs, imperceptible to humans, can manipulate machine learning models into making erroneous predictions, raising concerns for safety-critical applications. An intriguing property of this phenomenon is the transferability of adversarial examples, where perturbations crafted for one model can deceive another, often with a different architecture. This intriguing property enables "black-box" attacks, circumventing the need for detailed knowledge of the target model. This survey explores the landscape of the adversarial transferability of adversarial examples. We categorize existing methodologies to enhance adversarial transferability and discuss the fundamental principles guiding each approach. While the predominant body of research primarily concentrates on image classification, we also extend our discussion to encompass other vision tasks and beyond. Challenges and future prospects are discussed, highlighting the importance of fortifying DNNs against adversarial vulnerabilities in an evolving landscape.
Clinically Plausible Pathology-Anatomy Disentanglement in Patient Brain MRI with Structured Variational Priors
Nov 16, 2022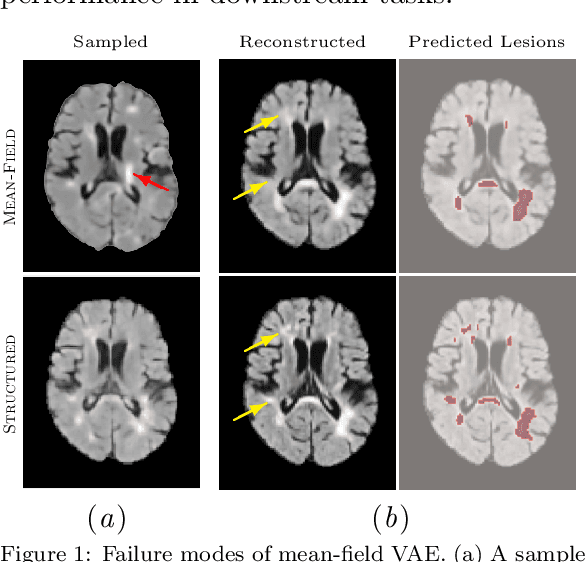

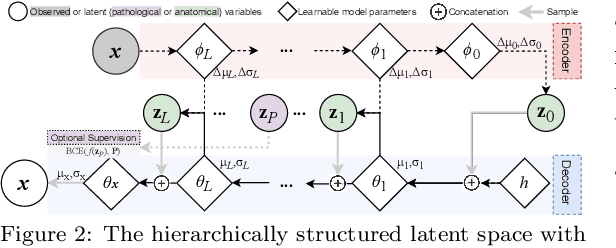
We propose a hierarchically structured variational inference model for accurately disentangling observable evidence of disease (e.g. brain lesions or atrophy) from subject-specific anatomy in brain MRIs. With flexible, partially autoregressive priors, our model (1) addresses the subtle and fine-grained dependencies that typically exist between anatomical and pathological generating factors of an MRI to ensure the clinical validity of generated samples; (2) preserves and disentangles finer pathological details pertaining to a patient's disease state. Additionally, we experiment with an alternative training configuration where we provide supervision to a subset of latent units. It is shown that (1) a partially supervised latent space achieves a higher degree of disentanglement between evidence of disease and subject-specific anatomy; (2) when the prior is formulated with an autoregressive structure, knowledge from the supervision can propagate to the unsupervised latent units, resulting in more informative latent representations capable of modelling anatomy-pathology interdependencies.
Counterfactual Image Synthesis for Discovery of Personalized Predictive Image Markers
Aug 03, 2022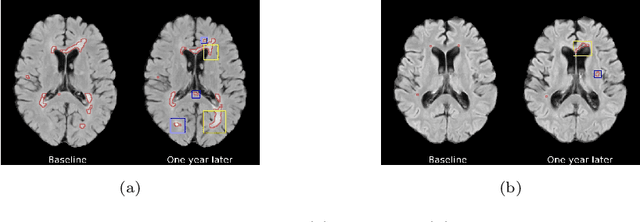

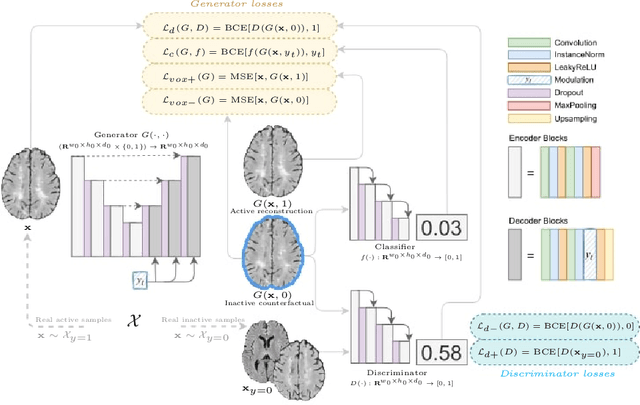

The discovery of patient-specific imaging markers that are predictive of future disease outcomes can help us better understand individual-level heterogeneity of disease evolution. In fact, deep learning models that can provide data-driven personalized markers are much more likely to be adopted in medical practice. In this work, we demonstrate that data-driven biomarker discovery can be achieved through a counterfactual synthesis process. We show how a deep conditional generative model can be used to perturb local imaging features in baseline images that are pertinent to subject-specific future disease evolution and result in a counterfactual image that is expected to have a different future outcome. Candidate biomarkers, therefore, result from examining the set of features that are perturbed in this process. Through several experiments on a large-scale, multi-scanner, multi-center multiple sclerosis (MS) clinical trial magnetic resonance imaging (MRI) dataset of relapsing-remitting (RRMS) patients, we demonstrate that our model produces counterfactuals with changes in imaging features that reflect established clinical markers predictive of future MRI lesional activity at the population level. Additional qualitative results illustrate that our model has the potential to discover novel and subject-specific predictive markers of future activity.