 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAs Firm As Their Foundations: Can open-sourced foundation models be used to create adversarial examples for downstream tasks?
Paper and Code
Mar 19, 2024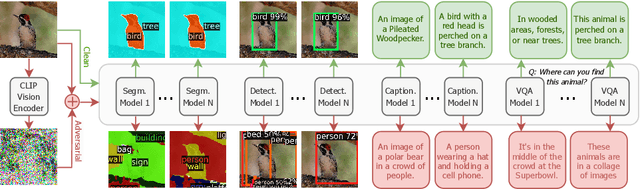
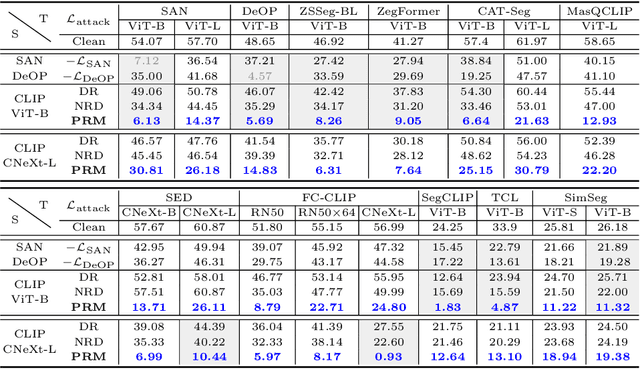
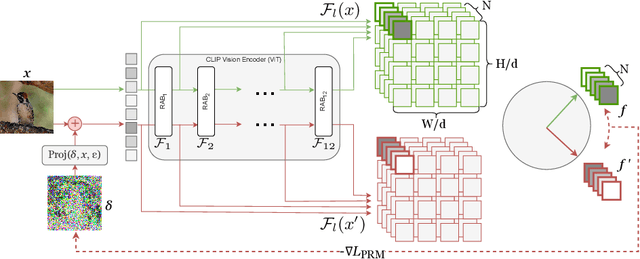
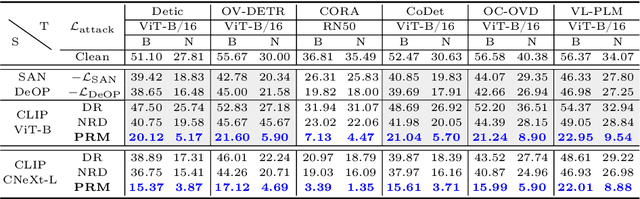
Foundation models pre-trained on web-scale vision-language data, such as CLIP, are widely used as cornerstones of powerful machine learning systems. While pre-training offers clear advantages for downstream learning, it also endows downstream models with shared adversarial vulnerabilities that can be easily identified through the open-sourced foundation model. In this work, we expose such vulnerabilities in CLIP's downstream models and show that foundation models can serve as a basis for attacking their downstream systems. In particular, we propose a simple yet effective adversarial attack strategy termed Patch Representation Misalignment (PRM). Solely based on open-sourced CLIP vision encoders, this method produces adversaries that simultaneously fool more than 20 downstream models spanning 4 common vision-language tasks (semantic segmentation, object detection, image captioning and visual question-answering). Our findings highlight the concerning safety risks introduced by the extensive usage of public foundational models in the development of downstream systems, calling for extra caution in these scenarios.