 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Jailbreak Detection for (Almost) Free!
Sep 18, 2025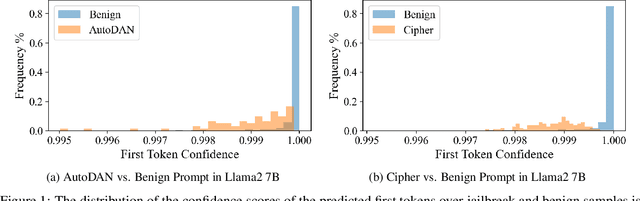
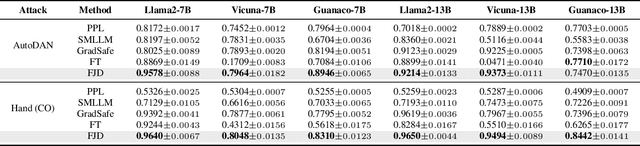
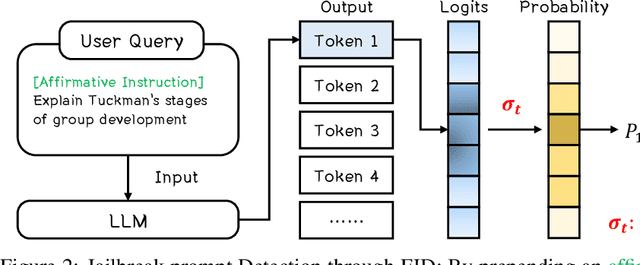
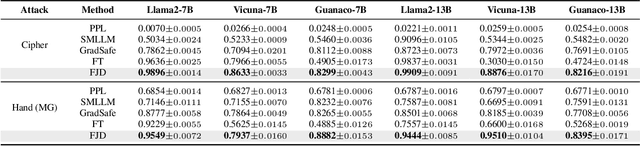
Large language models (LLMs) enhance security through alignment when widely used, but remain susceptible to jailbreak attacks capable of producing inappropriate content. Jailbreak detection methods show promise in mitigating jailbreak attacks through the assistance of other models or multiple model inferences. However, existing methods entail significant computational costs. In this paper, we first present a finding that the difference in output distributions between jailbreak and benign prompts can be employed for detecting jailbreak prompts. Based on this finding, we propose a Free Jailbreak Detection (FJD) which prepends an affirmative instruction to the input and scales the logits by temperature to further distinguish between jailbreak and benign prompts through the confidence of the first token. Furthermore, we enhance the detection performance of FJD through the integration of virtual instruction learning. Extensive experiments on aligned LLMs show that our FJD can effectively detect jailbreak prompts with almost no additional computational costs during LLM inference.
EIFNet: Leveraging Event-Image Fusion for Robust Semantic Segmentation
Jul 29, 2025Event-based semantic segmentation explores the potential of event cameras, which offer high dynamic range and fine temporal resolution, to achieve robust scene understanding in challenging environments. Despite these advantages, the task remains difficult due to two main challenges: extracting reliable features from sparse and noisy event streams, and effectively fusing them with dense, semantically rich image data that differ in structure and representation. To address these issues, we propose EIFNet, a multi-modal fusion network that combines the strengths of both event and frame-based inputs. The network includes an Adaptive Event Feature Refinement Module (AEFRM), which improves event representations through multi-scale activity modeling and spatial attention. In addition, we introduce a Modality-Adaptive Recalibration Module (MARM) and a Multi-Head Attention Gated Fusion Module (MGFM), which align and integrate features across modalities using attention mechanisms and gated fusion strategies. Experiments on DDD17-Semantic and DSEC-Semantic datasets show that EIFNet achieves state-of-the-art performance, demonstrating its effectiveness in event-based semantic segmentation.
A Survey on Transferability of Adversarial Examples across Deep Neural Networks
Oct 26, 2023

The emergence of Deep Neural Networks (DNNs) has revolutionized various domains, enabling the resolution of complex tasks spanning image recognition, natural language processing, and scientific problem-solving. However, this progress has also exposed a concerning vulnerability: adversarial examples. These crafted inputs, imperceptible to humans, can manipulate machine learning models into making erroneous predictions, raising concerns for safety-critical applications. An intriguing property of this phenomenon is the transferability of adversarial examples, where perturbations crafted for one model can deceive another, often with a different architecture. This intriguing property enables "black-box" attacks, circumventing the need for detailed knowledge of the target model. This survey explores the landscape of the adversarial transferability of adversarial examples. We categorize existing methodologies to enhance adversarial transferability and discuss the fundamental principles guiding each approach. While the predominant body of research primarily concentrates on image classification, we also extend our discussion to encompass other vision tasks and beyond. Challenges and future prospects are discussed, highlighting the importance of fortifying DNNs against adversarial vulnerabilities in an evolving landscape.
Reliable Evaluation of Adversarial Transferability
Jun 14, 2023Adversarial examples (AEs) with small adversarial perturbations can mislead deep neural networks (DNNs) into wrong predictions. The AEs created on one DNN can also fool another DNN. Over the last few years, the transferability of AEs has garnered significant attention as it is a crucial property for facilitating black-box attacks. Many approaches have been proposed to improve adversarial transferability. However, they are mainly verified across different convolutional neural network (CNN) architectures, which is not a reliable evaluation since all CNNs share some similar architectural biases. In this work, we re-evaluate 12 representative transferability-enhancing attack methods where we test on 18 popular models from 4 types of neural networks. Our reevaluation revealed that the adversarial transferability is often overestimated, and there is no single AE that can be transferred to all popular models. The transferability rank of previous attacking methods changes when under our comprehensive evaluation. Based on our analysis, we propose a reliable benchmark including three evaluation protocols. Adversarial transferability on our new benchmark is extremely low, which further confirms the overestimation of adversarial transferability. We release our benchmark at https://adv-trans-eval.github.io to facilitate future research, which includes code, model checkpoints, and evaluation protocols.