 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePANDAS: Improving Many-shot Jailbreaking via Positive Affirmation, Negative Demonstration, and Adaptive Sampling
Feb 04, 2025



Many-shot jailbreaking circumvents the safety alignment of large language models by exploiting their ability to process long input sequences. To achieve this, the malicious target prompt is prefixed with hundreds of fabricated conversational turns between the user and the model. These fabricated exchanges are randomly sampled from a pool of malicious questions and responses, making it appear as though the model has already complied with harmful instructions. In this paper, we present PANDAS: a hybrid technique that improves many-shot jailbreaking by modifying these fabricated dialogues with positive affirmations, negative demonstrations, and an optimized adaptive sampling method tailored to the target prompt's topic. Extensive experiments on AdvBench and HarmBench, using state-of-the-art LLMs, demonstrate that PANDAS significantly outperforms baseline methods in long-context scenarios. Through an attention analysis, we provide insights on how long-context vulnerabilities are exploited and show how PANDAS further improves upon many-shot jailbreaking.
Improving Adversarial Transferability via Model Alignment
Nov 30, 2023

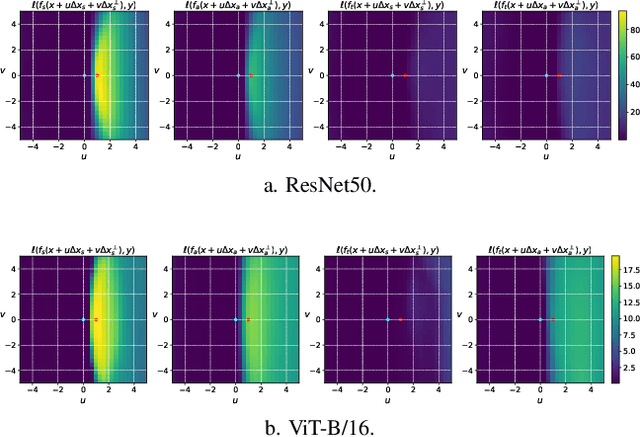

Neural networks are susceptible to adversarial perturbations that are transferable across different models. In this paper, we introduce a novel model alignment technique aimed at improving a given source model's ability in generating transferable adversarial perturbations. During the alignment process, the parameters of the source model are fine-tuned to minimize an alignment loss. This loss measures the divergence in the predictions between the source model and another, independently trained model, referred to as the witness model. To understand the effect of model alignment, we conduct a geometric anlaysis of the resulting changes in the loss landscape. Extensive experiments on the ImageNet dataset, using a variety of model architectures, demonstrate that perturbations generated from aligned source models exhibit significantly higher transferability than those from the original source model.
A Survey on Transferability of Adversarial Examples across Deep Neural Networks
Oct 26, 2023

The emergence of Deep Neural Networks (DNNs) has revolutionized various domains, enabling the resolution of complex tasks spanning image recognition, natural language processing, and scientific problem-solving. However, this progress has also exposed a concerning vulnerability: adversarial examples. These crafted inputs, imperceptible to humans, can manipulate machine learning models into making erroneous predictions, raising concerns for safety-critical applications. An intriguing property of this phenomenon is the transferability of adversarial examples, where perturbations crafted for one model can deceive another, often with a different architecture. This intriguing property enables "black-box" attacks, circumventing the need for detailed knowledge of the target model. This survey explores the landscape of the adversarial transferability of adversarial examples. We categorize existing methodologies to enhance adversarial transferability and discuss the fundamental principles guiding each approach. While the predominant body of research primarily concentrates on image classification, we also extend our discussion to encompass other vision tasks and beyond. Challenges and future prospects are discussed, highlighting the importance of fortifying DNNs against adversarial vulnerabilities in an evolving landscape.
Understanding the robustness difference between stochastic gradient descent and adaptive gradient methods
Aug 13, 2023Stochastic gradient descent (SGD) and adaptive gradient methods, such as Adam and RMSProp, have been widely used in training deep neural networks. We empirically show that while the difference between the standard generalization performance of models trained using these methods is small, those trained using SGD exhibit far greater robustness under input perturbations. Notably, our investigation demonstrates the presence of irrelevant frequencies in natural datasets, where alterations do not affect models' generalization performance. However, models trained with adaptive methods show sensitivity to these changes, suggesting that their use of irrelevant frequencies can lead to solutions sensitive to perturbations. To better understand this difference, we study the learning dynamics of gradient descent (GD) and sign gradient descent (signGD) on a synthetic dataset that mirrors natural signals. With a three-dimensional input space, the models optimized with GD and signGD have standard risks close to zero but vary in their adversarial risks. Our result shows that linear models' robustness to $\ell_2$-norm bounded changes is inversely proportional to the model parameters' weight norm: a smaller weight norm implies better robustness. In the context of deep learning, our experiments show that SGD-trained neural networks show smaller Lipschitz constants, explaining the better robustness to input perturbations than those trained with adaptive gradient methods.
SAGE: Saliency-Guided Mixup with Optimal Rearrangements
Oct 31, 2022



Data augmentation is a key element for training accurate models by reducing overfitting and improving generalization. For image classification, the most popular data augmentation techniques range from simple photometric and geometrical transformations, to more complex methods that use visual saliency to craft new training examples. As augmentation methods get more complex, their ability to increase the test accuracy improves, yet, such methods become cumbersome, inefficient and lead to poor out-of-domain generalization, as we show in this paper. This motivates a new augmentation technique that allows for high accuracy gains while being simple, efficient (i.e., minimal computation overhead) and generalizable. To this end, we introduce Saliency-Guided Mixup with Optimal Rearrangements (SAGE), which creates new training examples by rearranging and mixing image pairs using visual saliency as guidance. By explicitly leveraging saliency, SAGE promotes discriminative foreground objects and produces informative new images useful for training. We demonstrate on CIFAR-10 and CIFAR-100 that SAGE achieves better or comparable performance to the state of the art while being more efficient. Additionally, evaluations in the out-of-distribution setting, and few-shot learning on mini-ImageNet, show that SAGE achieves improved generalization performance without trading off robustness.
Improving Hierarchical Adversarial Robustness of Deep Neural Networks
Feb 17, 2021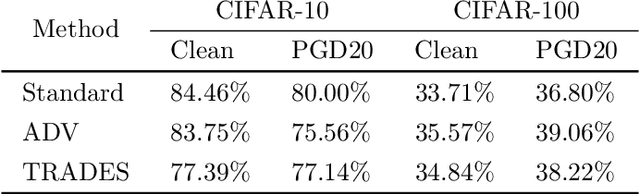
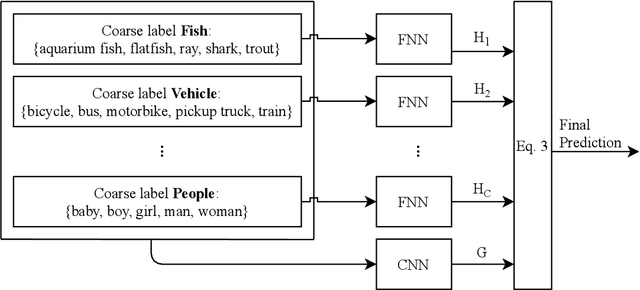
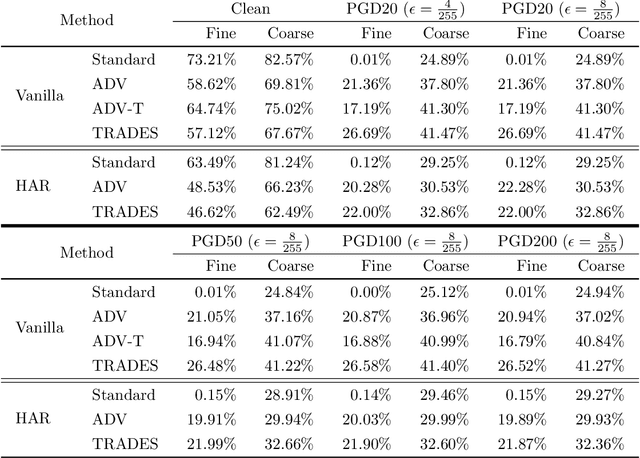
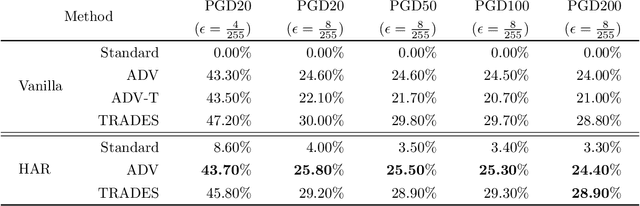
Do all adversarial examples have the same consequences? An autonomous driving system misclassifying a pedestrian as a car may induce a far more dangerous -- and even potentially lethal -- behavior than, for instance, a car as a bus. In order to better tackle this important problematic, we introduce the concept of hierarchical adversarial robustness. Given a dataset whose classes can be grouped into coarse-level labels, we define hierarchical adversarial examples as the ones leading to a misclassification at the coarse level. To improve the resistance of neural networks to hierarchical attacks, we introduce a hierarchical adversarially robust (HAR) network design that decomposes a single classification task into one coarse and multiple fine classification tasks, before being specifically trained by adversarial defense techniques. As an alternative to an end-to-end learning approach, we show that HAR significantly improves the robustness of the network against $\ell_2$ and $\ell_{\infty}$ bounded hierarchical attacks on the CIFAR-10 and CIFAR-100 dataset.
Adversarial Robustness through Regularization: A Second-Order Approach
Apr 04, 2020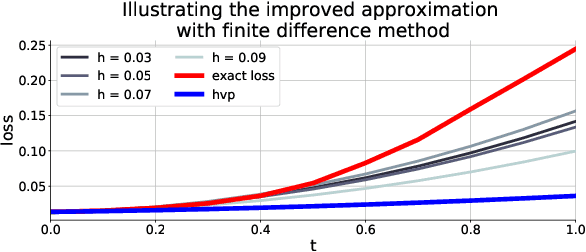

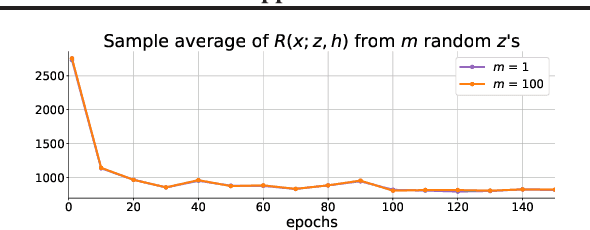

Adversarial training is a common approach to improving the robustness of deep neural networks against adversarial examples. In this work, we propose a novel regularization approach as an alternative. To derive the regularizer, we formulate the adversarial robustness problem under the robust optimization framework and approximate the loss function using a second-order Taylor series expansion. Our proposed second-order adversarial regularizer (SOAR) is an upper bound based on the Taylor approximation of the inner-max in the robust optimization objective. We empirically show that the proposed method improves the robustness of networks on the CIFAR-10 dataset.