 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePress Start to Charge: Videogaming the Online Centralized Charging Scheduling Problem
Jan 18, 2026We study the online centralized charging scheduling problem (OCCSP). In this problem, a central authority must decide, in real time, when to charge dynamically arriving electric vehicles (EVs), subject to capacity limits, with the objective of balancing load across a finite planning horizon. To solve the problem, we first gamify it; that is, we model it as a game where charging blocks are placed within temporal and capacity constraints on a grid. We design heuristic policies, train learning agents with expert demonstrations, and improve them using Dataset Aggregation (DAgger). From a theoretical standpoint, we show that gamification reduces model complexity and yields tighter generalization bounds than vector-based formulations. Experiments across multiple EV arrival patterns confirm that gamified learning enhances load balancing. In particular, the image-to-movement model trained with DAgger consistently outperforms heuristic baselines, vector-based approaches, and supervised learning agents, while also demonstrating robustness in sensitivity analyses. These operational gains translate into tangible economic value. In a real-world case study for the Greater Montréal Area (Québec, Canada) using utility cost data, the proposed methods lower system costs by tens of millions of dollars per year over the prevailing practice and show clear potential to delay costly grid upgrades.
Calibrated Value-Aware Model Learning with Stochastic Environment Models
May 28, 2025The idea of value-aware model learning, that models should produce accurate value estimates, has gained prominence in model-based reinforcement learning. The MuZero loss, which penalizes a model's value function prediction compared to the ground-truth value function, has been utilized in several prominent empirical works in the literature. However, theoretical investigation into its strengths and weaknesses is limited. In this paper, we analyze the family of value-aware model learning losses, which includes the popular MuZero loss. We show that these losses, as normally used, are uncalibrated surrogate losses, which means that they do not always recover the correct model and value function. Building on this insight, we propose corrections to solve this issue. Furthermore, we investigate the interplay between the loss calibration, latent model architectures, and auxiliary losses that are commonly employed when training MuZero-style agents. We show that while deterministic models can be sufficient to predict accurate values, learning calibrated stochastic models is still advantageous.
A Truncated Newton Method for Optimal Transport
Apr 02, 2025Developing a contemporary optimal transport (OT) solver requires navigating trade-offs among several critical requirements: GPU parallelization, scalability to high-dimensional problems, theoretical convergence guarantees, empirical performance in terms of precision versus runtime, and numerical stability in practice. With these challenges in mind, we introduce a specialized truncated Newton algorithm for entropic-regularized OT. In addition to proving that locally quadratic convergence is possible without assuming a Lipschitz Hessian, we provide strategies to maximally exploit the high rate of local convergence in practice. Our GPU-parallel algorithm exhibits exceptionally favorable runtime performance, achieving high precision orders of magnitude faster than many existing alternatives. This is evidenced by wall-clock time experiments on 24 problem sets (12 datasets $\times$ 2 cost functions). The scalability of the algorithm is showcased on an extremely large OT problem with $n \approx 10^6$, solved approximately under weak entopric regularization.
PANDAS: Improving Many-shot Jailbreaking via Positive Affirmation, Negative Demonstration, and Adaptive Sampling
Feb 04, 2025



Many-shot jailbreaking circumvents the safety alignment of large language models by exploiting their ability to process long input sequences. To achieve this, the malicious target prompt is prefixed with hundreds of fabricated conversational turns between the user and the model. These fabricated exchanges are randomly sampled from a pool of malicious questions and responses, making it appear as though the model has already complied with harmful instructions. In this paper, we present PANDAS: a hybrid technique that improves many-shot jailbreaking by modifying these fabricated dialogues with positive affirmations, negative demonstrations, and an optimized adaptive sampling method tailored to the target prompt's topic. Extensive experiments on AdvBench and HarmBench, using state-of-the-art LLMs, demonstrate that PANDAS significantly outperforms baseline methods in long-context scenarios. Through an attention analysis, we provide insights on how long-context vulnerabilities are exploited and show how PANDAS further improves upon many-shot jailbreaking.
MAD-TD: Model-Augmented Data stabilizes High Update Ratio RL
Oct 11, 2024


Building deep reinforcement learning (RL) agents that find a good policy with few samples has proven notoriously challenging. To achieve sample efficiency, recent work has explored updating neural networks with large numbers of gradient steps for every new sample. While such high update-to-data (UTD) ratios have shown strong empirical performance, they also introduce instability to the training process. Previous approaches need to rely on periodic neural network parameter resets to address this instability, but restarting the training process is infeasible in many real-world applications and requires tuning the resetting interval. In this paper, we focus on one of the core difficulties of stable training with limited samples: the inability of learned value functions to generalize to unobserved on-policy actions. We mitigate this issue directly by augmenting the off-policy RL training process with a small amount of data generated from a learned world model. Our method, Model-Augmented Data for Temporal Difference learning (MAD-TD) uses small amounts of generated data to stabilize high UTD training and achieve competitive performance on the most challenging tasks in the DeepMind control suite. Our experiments further highlight the importance of employing a good model to generate data, MAD-TD's ability to combat value overestimation, and its practical stability gains for continued learning.
Deflated Dynamics Value Iteration
Jul 15, 2024



The Value Iteration (VI) algorithm is an iterative procedure to compute the value function of a Markov decision process, and is the basis of many reinforcement learning (RL) algorithms as well. As the error convergence rate of VI as a function of iteration $k$ is $O(\gamma^k)$, it is slow when the discount factor $\gamma$ is close to $1$. To accelerate the computation of the value function, we propose Deflated Dynamics Value Iteration (DDVI). DDVI uses matrix splitting and matrix deflation techniques to effectively remove (deflate) the top $s$ dominant eigen-structure of the transition matrix $\mathcal{P}^{\pi}$. We prove that this leads to a $\tilde{O}(\gamma^k |\lambda_{s+1}|^k)$ convergence rate, where $\lambda_{s+1}$is $(s+1)$-th largest eigenvalue of the dynamics matrix. We then extend DDVI to the RL setting and present Deflated Dynamics Temporal Difference (DDTD) algorithm. We empirically show the effectiveness of the proposed algorithms.
PID Accelerated Temporal Difference Algorithms
Jul 11, 2024



Long-horizon tasks, which have a large discount factor, pose a challenge for most conventional reinforcement learning (RL) algorithms. Algorithms such as Value Iteration and Temporal Difference (TD) learning have a slow convergence rate and become inefficient in these tasks. When the transition distributions are given, PID VI was recently introduced to accelerate the convergence of Value Iteration using ideas from control theory. Inspired by this, we introduce PID TD Learning and PID Q-Learning algorithms for the RL setting in which only samples from the environment are available. We give theoretical analysis of their convergence and acceleration compared to their traditional counterparts. We also introduce a method for adapting PID gains in the presence of noise and empirically verify its effectiveness.
When does Self-Prediction help? Understanding Auxiliary Tasks in Reinforcement Learning
Jun 25, 2024We investigate the impact of auxiliary learning tasks such as observation reconstruction and latent self-prediction on the representation learning problem in reinforcement learning. We also study how they interact with distractions and observation functions in the MDP. We provide a theoretical analysis of the learning dynamics of observation reconstruction, latent self-prediction, and TD learning in the presence of distractions and observation functions under linear model assumptions. With this formalization, we are able to explain why latent-self prediction is a helpful \emph{auxiliary task}, while observation reconstruction can provide more useful features when used in isolation. Our empirical analysis shows that the insights obtained from our learning dynamics framework predicts the behavior of these loss functions beyond the linear model assumption in non-linear neural networks. This reinforces the usefulness of the linear model framework not only for theoretical analysis, but also practical benefit for applied problems.
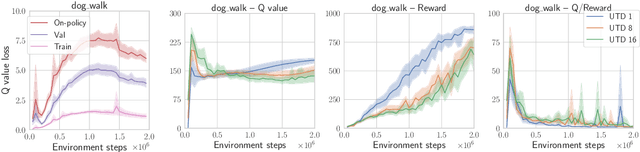
Dissecting Deep RL with High Update Ratios: Combatting Value Overestimation and Divergence
Mar 09, 2024We show that deep reinforcement learning can maintain its ability to learn without resetting network parameters in settings where the number of gradient updates greatly exceeds the number of environment samples. Under such large update-to-data ratios, a recent study by Nikishin et al. (2022) suggested the emergence of a primacy bias, in which agents overfit early interactions and downplay later experience, impairing their ability to learn. In this work, we dissect the phenomena underlying the primacy bias. We inspect the early stages of training that ought to cause the failure to learn and find that a fundamental challenge is a long-standing acquaintance: value overestimation. Overinflated Q-values are found not only on out-of-distribution but also in-distribution data and can be traced to unseen action prediction propelled by optimizer momentum. We employ a simple unit-ball normalization that enables learning under large update ratios, show its efficacy on the widely used dm_control suite, and obtain strong performance on the challenging dog tasks, competitive with model-based approaches. Our results question, in parts, the prior explanation for sub-optimal learning due to overfitting on early data.
Improving Adversarial Transferability via Model Alignment
Nov 30, 2023

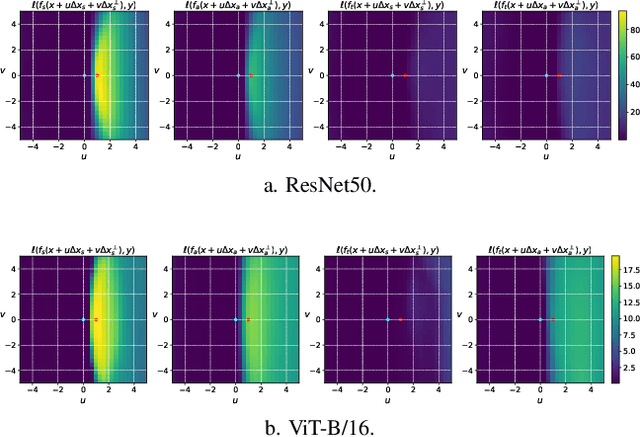

Neural networks are susceptible to adversarial perturbations that are transferable across different models. In this paper, we introduce a novel model alignment technique aimed at improving a given source model's ability in generating transferable adversarial perturbations. During the alignment process, the parameters of the source model are fine-tuned to minimize an alignment loss. This loss measures the divergence in the predictions between the source model and another, independently trained model, referred to as the witness model. To understand the effect of model alignment, we conduct a geometric anlaysis of the resulting changes in the loss landscape. Extensive experiments on the ImageNet dataset, using a variety of model architectures, demonstrate that perturbations generated from aligned source models exhibit significantly higher transferability than those from the original source model.