 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCamDirector: Towards Long-Term Coherent Video Trajectory Editing
Feb 27, 2026Video (camera) trajectory editing aims to synthesize new videos that follow user-defined camera paths while preserving scene content and plausibly inpainting previously unseen regions, upgrading amateur footage into professionally styled videos. Existing VTE methods struggle with precise camera control and long-range consistency because they either inject target poses through a limited-capacity embedding or rely on single-frame warping with only implicit cross-frame aggregation in video diffusion models. To address these issues, we introduce a new VTE framework that 1) explicitly aggregates information across the entire source video via a hybrid warping scheme. Specifically, static regions are progressively fused into a world cache then rendered to target camera poses, while dynamic regions are directly warped; their fusion yields globally consistent coarse frames that guide refinement. 2) processes video segments jointly with their history via a history-guided autoregressive diffusion model, while the world cache is incrementally updated to reinforce already inpainted content, enabling long-term temporal coherence. Finally, we present iPhone-PTZ, a new VTE benchmark with diverse camera motions and large trajectory variations, and achieve state-of-the-art performance with fewer parameters.
MotionDreamer: One-to-Many Motion Synthesis with Localized Generative Masked Transformer
Apr 11, 2025Generative masked transformers have demonstrated remarkable success across various content generation tasks, primarily due to their ability to effectively model large-scale dataset distributions with high consistency. However, in the animation domain, large datasets are not always available. Applying generative masked modeling to generate diverse instances from a single MoCap reference may lead to overfitting, a challenge that remains unexplored. In this work, we present MotionDreamer, a localized masked modeling paradigm designed to learn internal motion patterns from a given motion with arbitrary topology and duration. By embedding the given motion into quantized tokens with a novel distribution regularization method, MotionDreamer constructs a robust and informative codebook for local motion patterns. Moreover, a sliding window local attention is introduced in our masked transformer, enabling the generation of natural yet diverse animations that closely resemble the reference motion patterns. As demonstrated through comprehensive experiments, MotionDreamer outperforms the state-of-the-art methods that are typically GAN or Diffusion-based in both faithfulness and diversity. Thanks to the consistency and robustness of the quantization-based approach, MotionDreamer can also effectively perform downstream tasks such as temporal motion editing, \textcolor{update}{crowd animation}, and beat-aligned dance generation, all using a single reference motion. Visit our project page: https://motiondreamer.github.io/
IMFine: 3D Inpainting via Geometry-guided Multi-view Refinement
Mar 06, 2025Current 3D inpainting and object removal methods are largely limited to front-facing scenes, facing substantial challenges when applied to diverse, "unconstrained" scenes where the camera orientation and trajectory are unrestricted. To bridge this gap, we introduce a novel approach that produces inpainted 3D scenes with consistent visual quality and coherent underlying geometry across both front-facing and unconstrained scenes. Specifically, we propose a robust 3D inpainting pipeline that incorporates geometric priors and a multi-view refinement network trained via test-time adaptation, building on a pre-trained image inpainting model. Additionally, we develop a novel inpainting mask detection technique to derive targeted inpainting masks from object masks, boosting the performance in handling unconstrained scenes. To validate the efficacy of our approach, we create a challenging and diverse benchmark that spans a wide range of scenes. Comprehensive experiments demonstrate that our proposed method substantially outperforms existing state-of-the-art approaches.
TexGen: Text-Guided 3D Texture Generation with Multi-view Sampling and Resampling
Aug 02, 2024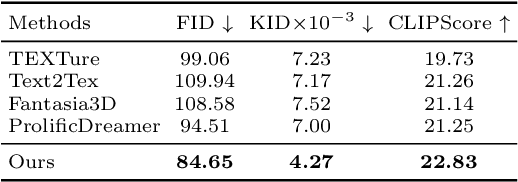
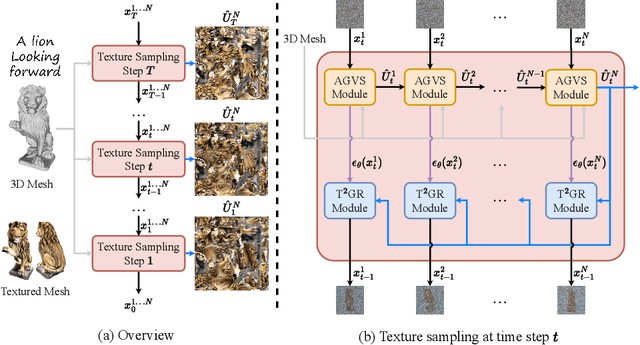
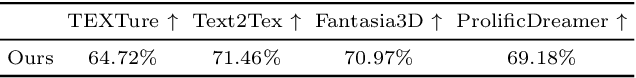

Given a 3D mesh, we aim to synthesize 3D textures that correspond to arbitrary textual descriptions. Current methods for generating and assembling textures from sampled views often result in prominent seams or excessive smoothing. To tackle these issues, we present TexGen, a novel multi-view sampling and resampling framework for texture generation leveraging a pre-trained text-to-image diffusion model. For view consistent sampling, first of all we maintain a texture map in RGB space that is parameterized by the denoising step and updated after each sampling step of the diffusion model to progressively reduce the view discrepancy. An attention-guided multi-view sampling strategy is exploited to broadcast the appearance information across views. To preserve texture details, we develop a noise resampling technique that aids in the estimation of noise, generating inputs for subsequent denoising steps, as directed by the text prompt and current texture map. Through an extensive amount of qualitative and quantitative evaluations, we demonstrate that our proposed method produces significantly better texture quality for diverse 3D objects with a high degree of view consistency and rich appearance details, outperforming current state-of-the-art methods. Furthermore, our proposed texture generation technique can also be applied to texture editing while preserving the original identity. More experimental results are available at https://dong-huo.github.io/TexGen/
GSD: View-Guided Gaussian Splatting Diffusion for 3D Reconstruction
Jul 05, 2024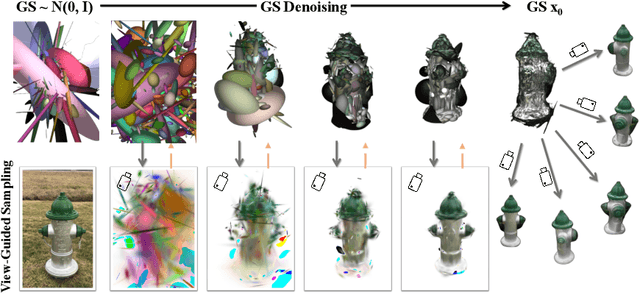



We present GSD, a diffusion model approach based on Gaussian Splatting (GS) representation for 3D object reconstruction from a single view. Prior works suffer from inconsistent 3D geometry or mediocre rendering quality due to improper representations. We take a step towards resolving these shortcomings by utilizing the recent state-of-the-art 3D explicit representation, Gaussian Splatting, and an unconditional diffusion model. This model learns to generate 3D objects represented by sets of GS ellipsoids. With these strong generative 3D priors, though learning unconditionally, the diffusion model is ready for view-guided reconstruction without further model fine-tuning. This is achieved by propagating fine-grained 2D features through the efficient yet flexible splatting function and the guided denoising sampling process. In addition, a 2D diffusion model is further employed to enhance rendering fidelity, and improve reconstructed GS quality by polishing and re-using the rendered images. The final reconstructed objects explicitly come with high-quality 3D structure and texture, and can be efficiently rendered in arbitrary views. Experiments on the challenging real-world CO3D dataset demonstrate the superiority of our approach.
Generative Human Motion Stylization in Latent Space
Jan 24, 2024



Human motion stylization aims to revise the style of an input motion while keeping its content unaltered. Unlike existing works that operate directly in pose space, we leverage the latent space of pretrained autoencoders as a more expressive and robust representation for motion extraction and infusion. Building upon this, we present a novel generative model that produces diverse stylization results of a single motion (latent) code. During training, a motion code is decomposed into two coding components: a deterministic content code, and a probabilistic style code adhering to a prior distribution; then a generator massages the random combination of content and style codes to reconstruct the corresponding motion codes. Our approach is versatile, allowing the learning of probabilistic style space from either style labeled or unlabeled motions, providing notable flexibility in stylization as well. In inference, users can opt to stylize a motion using style cues from a reference motion or a label. Even in the absence of explicit style input, our model facilitates novel re-stylization by sampling from the unconditional style prior distribution. Experimental results show that our proposed stylization models, despite their lightweight design, outperform the state-of-the-arts in style reeanactment, content preservation, and generalization across various applications and settings. Project Page: https://yxmu.foo/GenMoStyle
Hyper-Skin: A Hyperspectral Dataset for Reconstructing Facial Skin-Spectra from RGB Images
Oct 27, 2023



We introduce Hyper-Skin, a hyperspectral dataset covering wide range of wavelengths from visible (VIS) spectrum (400nm - 700nm) to near-infrared (NIR) spectrum (700nm - 1000nm), uniquely designed to facilitate research on facial skin-spectra reconstruction. By reconstructing skin spectra from RGB images, our dataset enables the study of hyperspectral skin analysis, such as melanin and hemoglobin concentrations, directly on the consumer device. Overcoming limitations of existing datasets, Hyper-Skin consists of diverse facial skin data collected with a pushbroom hyperspectral camera. With 330 hyperspectral cubes from 51 subjects, the dataset covers the facial skin from different angles and facial poses. Each hyperspectral cube has dimensions of 1024$\times$1024$\times$448, resulting in millions of spectra vectors per image. The dataset, carefully curated in adherence to ethical guidelines, includes paired hyperspectral images and synthetic RGB images generated using real camera responses. We demonstrate the efficacy of our dataset by showcasing skin spectra reconstruction using state-of-the-art models on 31 bands of hyperspectral data resampled in the VIS and NIR spectrum. This Hyper-Skin dataset would be a valuable resource to NeurIPS community, encouraging the development of novel algorithms for skin spectral reconstruction while fostering interdisciplinary collaboration in hyperspectral skin analysis related to cosmetology and skin's well-being. Instructions to request the data and the related benchmarking codes are publicly available at: \url{https://github.com/hyperspectral-skin/Hyper-Skin-2023}.
Error-Aware Spatial Ensembles for Video Frame Interpolation
Jul 25, 2022
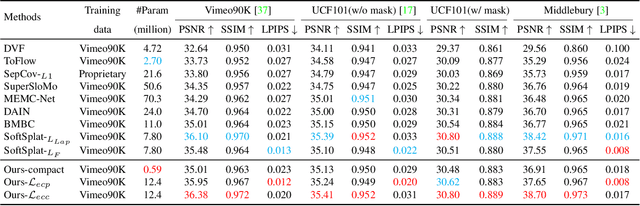
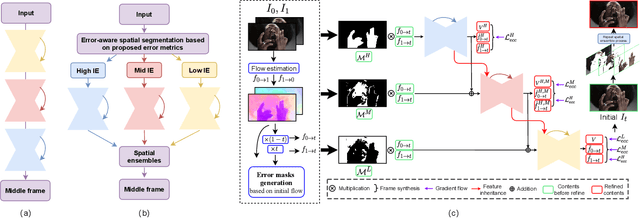
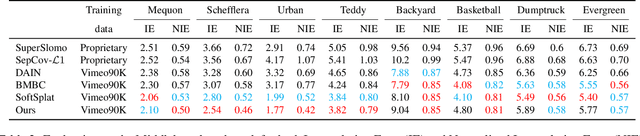
Video frame interpolation~(VFI) algorithms have improved considerably in recent years due to unprecedented progress in both data-driven algorithms and their implementations. Recent research has introduced advanced motion estimation or novel warping methods as the means to address challenging VFI scenarios. However, none of the published VFI works considers the spatially non-uniform characteristics of the interpolation error (IE). This work introduces such a solution. By closely examining the correlation between optical flow and IE, the paper proposes novel error prediction metrics that partition the middle frame into distinct regions corresponding to different IE levels. Building upon this IE-driven segmentation, and through the use of novel error-controlled loss functions, it introduces an ensemble of spatially adaptive interpolation units that progressively processes and integrates the segmented regions. This spatial ensemble results in an effective and computationally attractive VFI solution. Extensive experimentation on popular video interpolation benchmarks indicates that the proposed solution outperforms the current state-of-the-art (SOTA) in applications of current interest.
Self-supervised Spatiotemporal Representation Learning by Exploiting Video Continuity
Jan 10, 2022
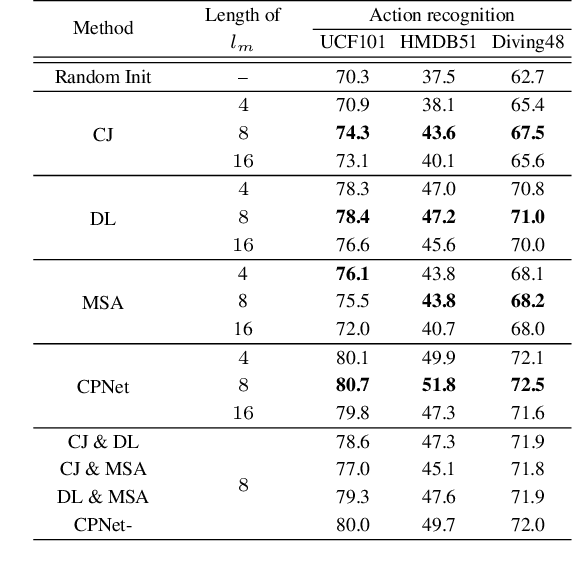
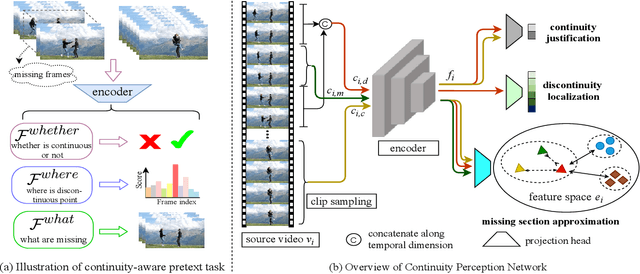
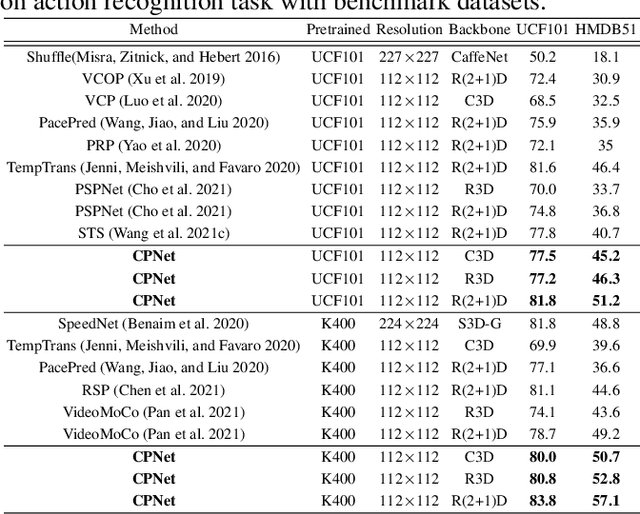
Recent self-supervised video representation learning methods have found significant success by exploring essential properties of videos, e.g. speed, temporal order, etc. This work exploits an essential yet under-explored property of videos, the video continuity, to obtain supervision signals for self-supervised representation learning. Specifically, we formulate three novel continuity-related pretext tasks, i.e. continuity justification, discontinuity localization, and missing section approximation, that jointly supervise a shared backbone for video representation learning. This self-supervision approach, termed as Continuity Perception Network (CPNet), solves the three tasks altogether and encourages the backbone network to learn local and long-ranged motion and context representations. It outperforms prior arts on multiple downstream tasks, such as action recognition, video retrieval, and action localization. Additionally, the video continuity can be complementary to other coarse-grained video properties for representation learning, and integrating the proposed pretext task to prior arts can yield much performance gains.
Decompose the Sounds and Pixels, Recompose the Events
Dec 21, 2021

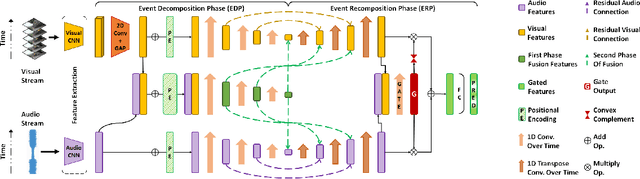
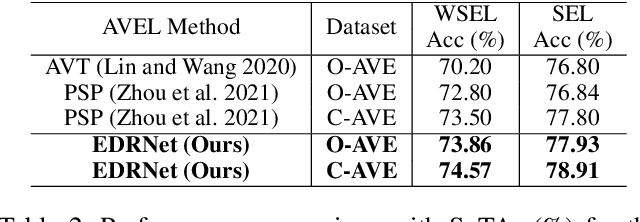
In this paper, we propose a framework centering around a novel architecture called the Event Decomposition Recomposition Network (EDRNet) to tackle the Audio-Visual Event (AVE) localization problem in the supervised and weakly supervised settings. AVEs in the real world exhibit common unravelling patterns (termed as Event Progress Checkpoints (EPC)), which humans can perceive through the cooperation of their auditory and visual senses. Unlike earlier methods which attempt to recognize entire event sequences, the EDRNet models EPCs and inter-EPC relationships using stacked temporal convolutions. Based on the postulation that EPC representations are theoretically consistent for an event category, we introduce the State Machine Based Video Fusion, a novel augmentation technique that blends source videos using different EPC template sequences. Additionally, we design a new loss function called the Land-Shore-Sea loss to compactify continuous foreground and background representations. Lastly, to alleviate the issue of confusing events during weak supervision, we propose a prediction stabilization method called Bag to Instance Label Correction. Experiments on the AVE dataset show that our collective framework outperforms the state-of-the-art by a sizable margin.