 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCamDirector: Towards Long-Term Coherent Video Trajectory Editing
Feb 27, 2026Video (camera) trajectory editing aims to synthesize new videos that follow user-defined camera paths while preserving scene content and plausibly inpainting previously unseen regions, upgrading amateur footage into professionally styled videos. Existing VTE methods struggle with precise camera control and long-range consistency because they either inject target poses through a limited-capacity embedding or rely on single-frame warping with only implicit cross-frame aggregation in video diffusion models. To address these issues, we introduce a new VTE framework that 1) explicitly aggregates information across the entire source video via a hybrid warping scheme. Specifically, static regions are progressively fused into a world cache then rendered to target camera poses, while dynamic regions are directly warped; their fusion yields globally consistent coarse frames that guide refinement. 2) processes video segments jointly with their history via a history-guided autoregressive diffusion model, while the world cache is incrementally updated to reinforce already inpainted content, enabling long-term temporal coherence. Finally, we present iPhone-PTZ, a new VTE benchmark with diverse camera motions and large trajectory variations, and achieve state-of-the-art performance with fewer parameters.
IMFine: 3D Inpainting via Geometry-guided Multi-view Refinement
Mar 06, 2025Current 3D inpainting and object removal methods are largely limited to front-facing scenes, facing substantial challenges when applied to diverse, "unconstrained" scenes where the camera orientation and trajectory are unrestricted. To bridge this gap, we introduce a novel approach that produces inpainted 3D scenes with consistent visual quality and coherent underlying geometry across both front-facing and unconstrained scenes. Specifically, we propose a robust 3D inpainting pipeline that incorporates geometric priors and a multi-view refinement network trained via test-time adaptation, building on a pre-trained image inpainting model. Additionally, we develop a novel inpainting mask detection technique to derive targeted inpainting masks from object masks, boosting the performance in handling unconstrained scenes. To validate the efficacy of our approach, we create a challenging and diverse benchmark that spans a wide range of scenes. Comprehensive experiments demonstrate that our proposed method substantially outperforms existing state-of-the-art approaches.
Accurate and Scalable Graph Neural Networks via Message Invariance
Feb 27, 2025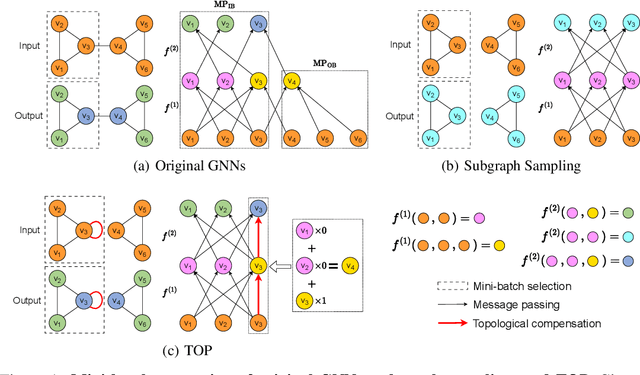

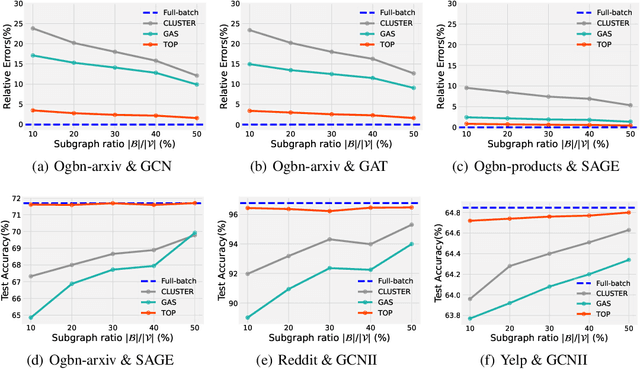

Message passing-based graph neural networks (GNNs) have achieved great success in many real-world applications. For a sampled mini-batch of target nodes, the message passing process is divided into two parts: message passing between nodes within the batch (MP-IB) and message passing from nodes outside the batch to those within it (MP-OB). However, MP-OB recursively relies on higher-order out-of-batch neighbors, leading to an exponentially growing computational cost with respect to the number of layers. Due to the neighbor explosion, the whole message passing stores most nodes and edges on the GPU such that many GNNs are infeasible to large-scale graphs. To address this challenge, we propose an accurate and fast mini-batch approach for large graph transductive learning, namely topological compensation (TOP), which obtains the outputs of the whole message passing solely through MP-IB, without the costly MP-OB. The major pillar of TOP is a novel concept of message invariance, which defines message-invariant transformations to convert costly MP-OB into fast MP-IB. This ensures that the modified MP-IB has the same output as the whole message passing. Experiments demonstrate that TOP is significantly faster than existing mini-batch methods by order of magnitude on vast graphs (millions of nodes and billions of edges) with limited accuracy degradation.
TexGen: Text-Guided 3D Texture Generation with Multi-view Sampling and Resampling
Aug 02, 2024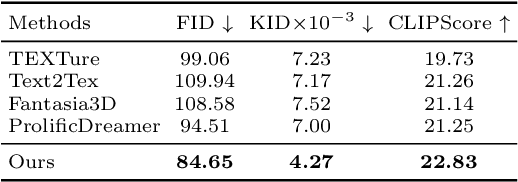
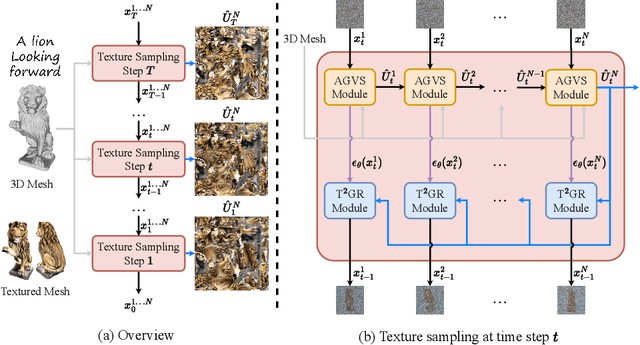
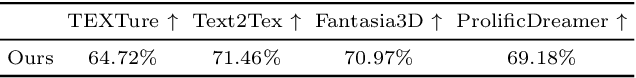

Given a 3D mesh, we aim to synthesize 3D textures that correspond to arbitrary textual descriptions. Current methods for generating and assembling textures from sampled views often result in prominent seams or excessive smoothing. To tackle these issues, we present TexGen, a novel multi-view sampling and resampling framework for texture generation leveraging a pre-trained text-to-image diffusion model. For view consistent sampling, first of all we maintain a texture map in RGB space that is parameterized by the denoising step and updated after each sampling step of the diffusion model to progressively reduce the view discrepancy. An attention-guided multi-view sampling strategy is exploited to broadcast the appearance information across views. To preserve texture details, we develop a noise resampling technique that aids in the estimation of noise, generating inputs for subsequent denoising steps, as directed by the text prompt and current texture map. Through an extensive amount of qualitative and quantitative evaluations, we demonstrate that our proposed method produces significantly better texture quality for diverse 3D objects with a high degree of view consistency and rich appearance details, outperforming current state-of-the-art methods. Furthermore, our proposed texture generation technique can also be applied to texture editing while preserving the original identity. More experimental results are available at https://dong-huo.github.io/TexGen/
Learning to Cut via Hierarchical Sequence/Set Model for Efficient Mixed-Integer Programming
Apr 19, 2024



Cutting planes (cuts) play an important role in solving mixed-integer linear programs (MILPs), which formulate many important real-world applications. Cut selection heavily depends on (P1) which cuts to prefer and (P2) how many cuts to select. Although modern MILP solvers tackle (P1)-(P2) by human-designed heuristics, machine learning carries the potential to learn more effective heuristics. However, many existing learning-based methods learn which cuts to prefer, neglecting the importance of learning how many cuts to select. Moreover, we observe that (P3) what order of selected cuts to prefer significantly impacts the efficiency of MILP solvers as well. To address these challenges, we propose a novel hierarchical sequence/set model (HEM) to learn cut selection policies. Specifically, HEM is a bi-level model: (1) a higher-level module that learns how many cuts to select, (2) and a lower-level module -- that formulates the cut selection as a sequence/set to sequence learning problem -- to learn policies selecting an ordered subset with the cardinality determined by the higher-level module. To the best of our knowledge, HEM is the first data-driven methodology that well tackles (P1)-(P3) simultaneously. Experiments demonstrate that HEM significantly improves the efficiency of solving MILPs on eleven challenging MILP benchmarks, including two Huawei's real problems.
Robust Preference Optimization with Provable Noise Tolerance for LLMs
Apr 05, 2024


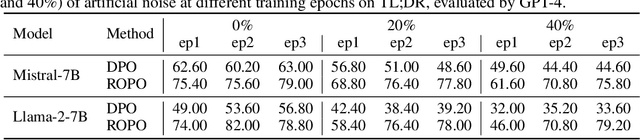
The preference alignment aims to enable large language models (LLMs) to generate responses that conform to human values, which is essential for developing general AI systems. Ranking-based methods -- a promising class of alignment approaches -- learn human preferences from datasets containing response pairs by optimizing the log-likelihood margins between preferred and dis-preferred responses. However, due to the inherent differences in annotators' preferences, ranking labels of comparisons for response pairs are unavoidably noisy. This seriously hurts the reliability of existing ranking-based methods. To address this problem, we propose a provably noise-tolerant preference alignment method, namely RObust Preference Optimization (ROPO). To the best of our knowledge, ROPO is the first preference alignment method with noise-tolerance guarantees. The key idea of ROPO is to dynamically assign conservative gradient weights to response pairs with high label uncertainty, based on the log-likelihood margins between the responses. By effectively suppressing the gradients of noisy samples, our weighting strategy ensures that the expected risk has the same gradient direction independent of the presence and proportion of noise. Experiments on three open-ended text generation tasks with four base models ranging in size from 2.8B to 13B demonstrate that ROPO significantly outperforms existing ranking-based methods.
Label Deconvolution for Node Representation Learning on Large-scale Attributed Graphs against Learning Bias
Sep 26, 2023Node representation learning on attributed graphs -- whose nodes are associated with rich attributes (e.g., texts and protein sequences) -- plays a crucial role in many important downstream tasks. To encode the attributes and graph structures simultaneously, recent studies integrate pre-trained models with graph neural networks (GNNs), where pre-trained models serve as node encoders (NEs) to encode the attributes. As jointly training large NEs and GNNs on large-scale graphs suffers from severe scalability issues, many methods propose to train NEs and GNNs separately. Consequently, they do not take feature convolutions in GNNs into consideration in the training phase of NEs, leading to a significant learning bias from that by the joint training. To address this challenge, we propose an efficient label regularization technique, namely Label Deconvolution (LD), to alleviate the learning bias by a novel and highly scalable approximation to the inverse mapping of GNNs. The inverse mapping leads to an objective function that is equivalent to that by the joint training, while it can effectively incorporate GNNs in the training phase of NEs against the learning bias. More importantly, we show that LD converges to the optimal objective function values by thejoint training under mild assumptions. Experiments demonstrate LD significantly outperforms state-of-the-art methods on Open Graph Benchmark datasets.
Learning Complete Topology-Aware Correlations Between Relations for Inductive Link Prediction
Sep 20, 2023Inductive link prediction -- where entities during training and inference stages can be different -- has shown great potential for completing evolving knowledge graphs in an entity-independent manner. Many popular methods mainly focus on modeling graph-level features, while the edge-level interactions -- especially the semantic correlations between relations -- have been less explored. However, we notice a desirable property of semantic correlations between relations is that they are inherently edge-level and entity-independent. This implies the great potential of the semantic correlations for the entity-independent inductive link prediction task. Inspired by this observation, we propose a novel subgraph-based method, namely TACO, to model Topology-Aware COrrelations between relations that are highly correlated to their topological structures within subgraphs. Specifically, we prove that semantic correlations between any two relations can be categorized into seven topological patterns, and then proposes Relational Correlation Network (RCN) to learn the importance of each pattern. To further exploit the potential of RCN, we propose Complete Common Neighbor induced subgraph that can effectively preserve complete topological patterns within the subgraph. Extensive experiments demonstrate that TACO effectively unifies the graph-level information and edge-level interactions to jointly perform reasoning, leading to a superior performance over existing state-of-the-art methods for the inductive link prediction task.
Provably Convergent Subgraph-wise Sampling for Fast GNN Training
Mar 17, 2023



Subgraph-wise sampling -- a promising class of mini-batch training techniques for graph neural networks (GNNs -- is critical for real-world applications. During the message passing (MP) in GNNs, subgraph-wise sampling methods discard messages outside the mini-batches in backward passes to avoid the well-known neighbor explosion problem, i.e., the exponentially increasing dependencies of nodes with the number of MP iterations. However, discarding messages may sacrifice the gradient estimation accuracy, posing significant challenges to their convergence analysis and convergence speeds. To address this challenge, we propose a novel subgraph-wise sampling method with a convergence guarantee, namely Local Message Compensation (LMC). To the best of our knowledge, LMC is the first subgraph-wise sampling method with provable convergence. The key idea is to retrieve the discarded messages in backward passes based on a message passing formulation of backward passes. By efficient and effective compensations for the discarded messages in both forward and backward passes, LMC computes accurate mini-batch gradients and thus accelerates convergence. Moreover, LMC is applicable to various MP-based GNN architectures, including convolutional GNNs (finite message passing iterations with different layers) and recurrent GNNs (infinite message passing iterations with a shared layer). Experiments on large-scale benchmarks demonstrate that LMC is significantly faster than state-of-the-art subgraph-wise sampling methods.
Generalization in Visual Reinforcement Learning with the Reward Sequence Distribution
Feb 19, 2023



Generalization in partially observed markov decision processes (POMDPs) is critical for successful applications of visual reinforcement learning (VRL) in real scenarios. A widely used idea is to learn task-relevant representations that encode task-relevant information of common features in POMDPs, i.e., rewards and transition dynamics. As transition dynamics in the latent state space -- which are task-relevant and invariant to visual distractions -- are unknown to the agents, existing methods alternatively use transition dynamics in the observation space to extract task-relevant information in transition dynamics. However, such transition dynamics in the observation space involve task-irrelevant visual distractions, degrading the generalization performance of VRL methods. To tackle this problem, we propose the reward sequence distribution conditioned on the starting observation and the predefined subsequent action sequence (RSD-OA). The appealing features of RSD-OA include that: (1) RSD-OA is invariant to visual distractions, as it is conditioned on the predefined subsequent action sequence without task-irrelevant information from transition dynamics, and (2) the reward sequence captures long-term task-relevant information in both rewards and transition dynamics. Experiments demonstrate that our representation learning approach based on RSD-OA significantly improves the generalization performance on unseen environments, outperforming several state-of-the-arts on DeepMind Control tasks with visual distractions.