 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStabilizing Rubric Integration Training via Decoupled Advantage Normalization
Mar 27, 2026We propose Process-Aware Policy Optimization (PAPO), a method that integrates process-level evaluation into Group Relative Policy Optimization (GRPO) through decoupled advantage normalization, to address two limitations of existing reward designs. Outcome reward models (ORM) evaluate only final-answer correctness, treating all correct responses identically regardless of reasoning quality, and gradually lose the advantage signal as groups become uniformly correct. Process reward models (PRM) offer richer supervision, but directly using PRM scores causes reward hacking, where models exploit verbosity to inflate scores while accuracy collapses. PAPO resolves both by composing the advantage from an outcome component Aout, derived from ORM and normalized over all responses, and a process component Aproc, derived from a rubric-based PRM and normalized exclusively among correct responses. This decoupled design ensures that Aout anchors training on correctness while Aproc differentiates reasoning quality without distorting the outcome signal. Experiments across multiple model scales and six benchmarks demonstrate that PAPO consistently outperforms ORM, reaching 51.3% vs.\ 46.3% on OlympiadBench while continuing to improve as ORM plateaus and declines.
CoCo-MILP: Inter-Variable Contrastive and Intra-Constraint Competitive MILP Solution Prediction
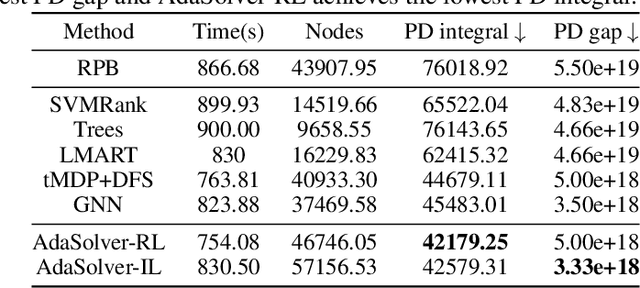
Nov 12, 2025Mixed-Integer Linear Programming (MILP) is a cornerstone of combinatorial optimization, yet solving large-scale instances remains a significant computational challenge. Recently, Graph Neural Networks (GNNs) have shown promise in accelerating MILP solvers by predicting high-quality solutions. However, we identify that existing methods misalign with the intrinsic structure of MILP problems at two levels. At the leaning objective level, the Binary Cross-Entropy (BCE) loss treats variables independently, neglecting their relative priority and yielding plausible logits. At the model architecture level, standard GNN message passing inherently smooths the representations across variables, missing the natural competitive relationships within constraints. To address these challenges, we propose CoCo-MILP, which explicitly models inter-variable Contrast and intra-constraint Competition for advanced MILP solution prediction. At the objective level, CoCo-MILP introduces the Inter-Variable Contrastive Loss (VCL), which explicitly maximizes the embedding margin between variables assigned one versus zero. At the architectural level, we design an Intra-Constraint Competitive GNN layer that, instead of homogenizing features, learns to differentiate representations of competing variables within a constraint, capturing their exclusionary nature. Experimental results on standard benchmarks demonstrate that CoCo-MILP significantly outperforms existing learning-based approaches, reducing the solution gap by up to 68.12% compared to traditional solvers. Our code is available at https://github.com/happypu326/CoCo-MILP.
Apollo-MILP: An Alternating Prediction-Correction Neural Solving Framework for Mixed-Integer Linear Programming
Mar 03, 2025Leveraging machine learning (ML) to predict an initial solution for mixed-integer linear programming (MILP) has gained considerable popularity in recent years. These methods predict a solution and fix a subset of variables to reduce the problem dimension. Then, they solve the reduced problem to obtain the final solutions. However, directly fixing variable values can lead to low-quality solutions or even infeasible reduced problems if the predicted solution is not accurate enough. To address this challenge, we propose an Alternating prediction-correction neural solving framework (Apollo-MILP) that can identify and select accurate and reliable predicted values to fix. In each iteration, Apollo-MILP conducts a prediction step for the unfixed variables, followed by a correction step to obtain an improved solution (called reference solution) through a trust-region search. By incorporating the predicted and reference solutions, we introduce a novel Uncertainty-based Error upper BOund (UEBO) to evaluate the uncertainty of the predicted values and fix those with high confidence. A notable feature of Apollo-MILP is the superior ability for problem reduction while preserving optimality, leading to high-quality final solutions. Experiments on commonly used benchmarks demonstrate that our proposed Apollo-MILP significantly outperforms other ML-based approaches in terms of solution quality, achieving over a 50% reduction in the solution gap.
MILP-StuDio: MILP Instance Generation via Block Structure Decomposition
Oct 31, 2024



Mixed-integer linear programming (MILP) is one of the most popular mathematical formulations with numerous applications. In practice, improving the performance of MILP solvers often requires a large amount of high-quality data, which can be challenging to collect. Researchers thus turn to generation techniques to generate additional MILP instances. However, existing approaches do not take into account specific block structures -- which are closely related to the problem formulations -- in the constraint coefficient matrices (CCMs) of MILPs. Consequently, they are prone to generate computationally trivial or infeasible instances due to the disruptions of block structures and thus problem formulations. To address this challenge, we propose a novel MILP generation framework, called Block Structure Decomposition (MILP-StuDio), to generate high-quality instances by preserving the block structures. Specifically, MILP-StuDio begins by identifying the blocks in CCMs and decomposing the instances into block units, which serve as the building blocks of MILP instances. We then design three operators to construct new instances by removing, substituting, and appending block units in the original instances, enabling us to generate instances with flexible sizes. An appealing feature of MILP-StuDio is its strong ability to preserve the feasibility and computational hardness of the generated instances. Experiments on the commonly-used benchmarks demonstrate that using instances generated by MILP-StuDio is able to significantly reduce over 10% of the solving time for learning-based solvers.
Machine Learning Insides OptVerse AI Solver: Design Principles and Applications
Jan 17, 2024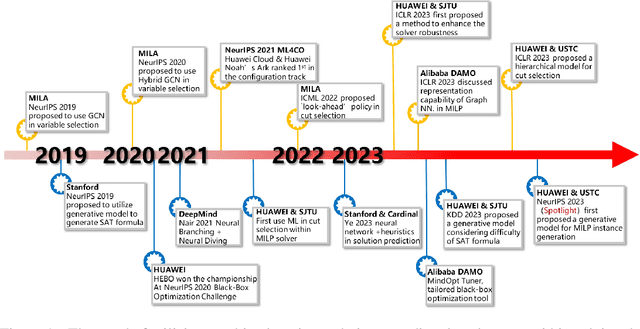

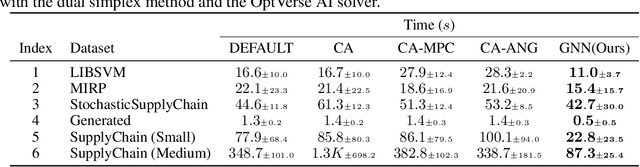
In an era of digital ubiquity, efficient resource management and decision-making are paramount across numerous industries. To this end, we present a comprehensive study on the integration of machine learning (ML) techniques into Huawei Cloud's OptVerse AI Solver, which aims to mitigate the scarcity of real-world mathematical programming instances, and to surpass the capabilities of traditional optimization techniques. We showcase our methods for generating complex SAT and MILP instances utilizing generative models that mirror multifaceted structures of real-world problem. Furthermore, we introduce a training framework leveraging augmentation policies to maintain solvers' utility in dynamic environments. Besides the data generation and augmentation, our proposed approaches also include novel ML-driven policies for personalized solver strategies, with an emphasis on applications like graph convolutional networks for initial basis selection and reinforcement learning for advanced presolving and cut selection. Additionally, we detail the incorporation of state-of-the-art parameter tuning algorithms which markedly elevate solver performance. Compared with traditional solvers such as Cplex and SCIP, our ML-augmented OptVerse AI Solver demonstrates superior speed and precision across both established benchmarks and real-world scenarios, reinforcing the practical imperative and effectiveness of machine learning techniques in mathematical programming solvers.
Accelerating Data Generation for Neural Operators via Krylov Subspace Recycling
Jan 17, 2024

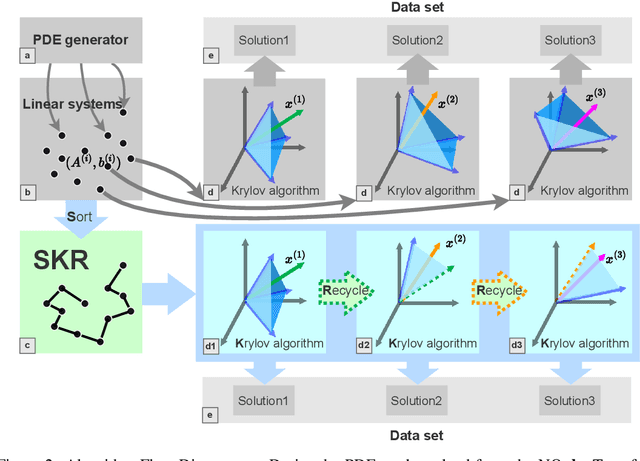

Learning neural operators for solving partial differential equations (PDEs) has attracted great attention due to its high inference efficiency. However, training such operators requires generating a substantial amount of labeled data, i.e., PDE problems together with their solutions. The data generation process is exceptionally time-consuming, as it involves solving numerous systems of linear equations to obtain numerical solutions to the PDEs. Many existing methods solve these systems independently without considering their inherent similarities, resulting in extremely redundant computations. To tackle this problem, we propose a novel method, namely Sorting Krylov Recycling (SKR), to boost the efficiency of solving these systems, thus significantly accelerating data generation for neural operators training. To the best of our knowledge, SKR is the first attempt to address the time-consuming nature of data generation for learning neural operators. The working horse of SKR is Krylov subspace recycling, a powerful technique for solving a series of interrelated systems by leveraging their inherent similarities. Specifically, SKR employs a sorting algorithm to arrange these systems in a sequence, where adjacent systems exhibit high similarities. Then it equips a solver with Krylov subspace recycling to solve the systems sequentially instead of independently, thus effectively enhancing the solving efficiency. Both theoretical analysis and extensive experiments demonstrate that SKR can significantly accelerate neural operator data generation, achieving a remarkable speedup of up to 13.9 times.
A Deep Instance Generative Framework for MILP Solvers Under Limited Data Availability
Oct 04, 2023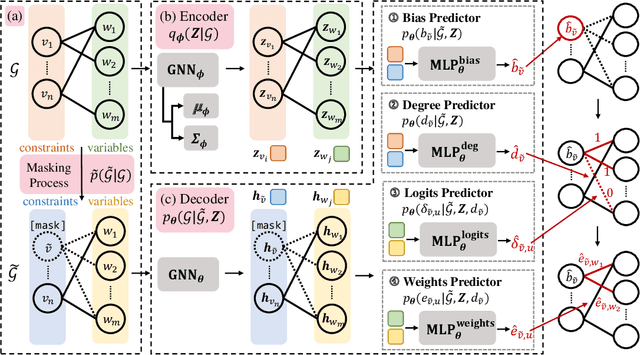
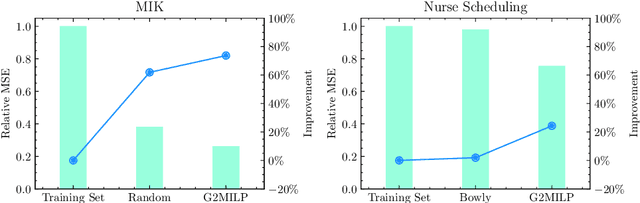

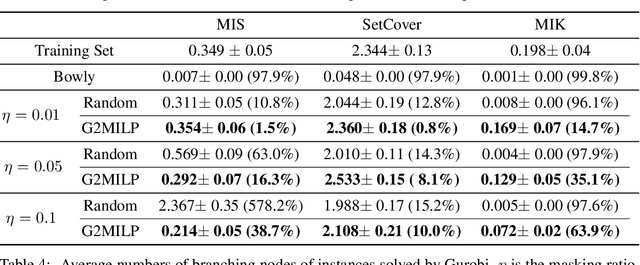
In the past few years, there has been an explosive surge in the use of machine learning (ML) techniques to address combinatorial optimization (CO) problems, especially mixed-integer linear programs (MILPs). Despite the achievements, the limited availability of real-world instances often leads to sub-optimal decisions and biased solver assessments, which motivates a suite of synthetic MILP instance generation techniques. However, existing methods either rely heavily on expert-designed formulations or struggle to capture the rich features of real-world instances. To tackle this problem, we propose G2MILP, which to the best of our knowledge is the first deep generative framework for MILP instances. Specifically, G2MILP represents MILP instances as bipartite graphs, and applies a masked variational autoencoder to iteratively corrupt and replace parts of the original graphs to generate new ones. The appealing feature of G2MILP is that it can learn to generate novel and realistic MILP instances without prior expert-designed formulations, while preserving the structures and computational hardness of real-world datasets, simultaneously. Thus the generated instances can facilitate downstream tasks for enhancing MILP solvers under limited data availability. We design a suite of benchmarks to evaluate the quality of the generated MILP instances. Experiments demonstrate that our method can produce instances that closely resemble real-world datasets in terms of both structures and computational hardness.
Generalization in Visual Reinforcement Learning with the Reward Sequence Distribution
Feb 19, 2023



Generalization in partially observed markov decision processes (POMDPs) is critical for successful applications of visual reinforcement learning (VRL) in real scenarios. A widely used idea is to learn task-relevant representations that encode task-relevant information of common features in POMDPs, i.e., rewards and transition dynamics. As transition dynamics in the latent state space -- which are task-relevant and invariant to visual distractions -- are unknown to the agents, existing methods alternatively use transition dynamics in the observation space to extract task-relevant information in transition dynamics. However, such transition dynamics in the observation space involve task-irrelevant visual distractions, degrading the generalization performance of VRL methods. To tackle this problem, we propose the reward sequence distribution conditioned on the starting observation and the predefined subsequent action sequence (RSD-OA). The appealing features of RSD-OA include that: (1) RSD-OA is invariant to visual distractions, as it is conditioned on the predefined subsequent action sequence without task-irrelevant information from transition dynamics, and (2) the reward sequence captures long-term task-relevant information in both rewards and transition dynamics. Experiments demonstrate that our representation learning approach based on RSD-OA significantly improves the generalization performance on unseen environments, outperforming several state-of-the-arts on DeepMind Control tasks with visual distractions.
De Novo Molecular Generation via Connection-aware Motif Mining
Feb 02, 2023



De novo molecular generation is an essential task for science discovery. Recently, fragment-based deep generative models have attracted much research attention due to their flexibility in generating novel molecules based on existing molecule fragments. However, the motif vocabulary, i.e., the collection of frequent fragments, is usually built upon heuristic rules, which brings difficulties to capturing common substructures from large amounts of molecules. In this work, we propose a new method, MiCaM, to generate molecules based on mined connection-aware motifs. Specifically, it leverages a data-driven algorithm to automatically discover motifs from a molecule library by iteratively merging subgraphs based on their frequency. The obtained motif vocabulary consists of not only molecular motifs (i.e., the frequent fragments), but also their connection information, indicating how the motifs are connected with each other. Based on the mined connection-aware motifs, MiCaM builds a connection-aware generator, which simultaneously picks up motifs and determines how they are connected. We test our method on distribution-learning benchmarks (i.e., generating novel molecules to resemble the distribution of a given training set) and goal-directed benchmarks (i.e., generating molecules with target properties), and achieve significant improvements over previous fragment-based baselines. Furthermore, we demonstrate that our method can effectively mine domain-specific motifs for different tasks.
Learning Task-relevant Representations for Generalization via Characteristic Functions of Reward Sequence Distributions
May 20, 2022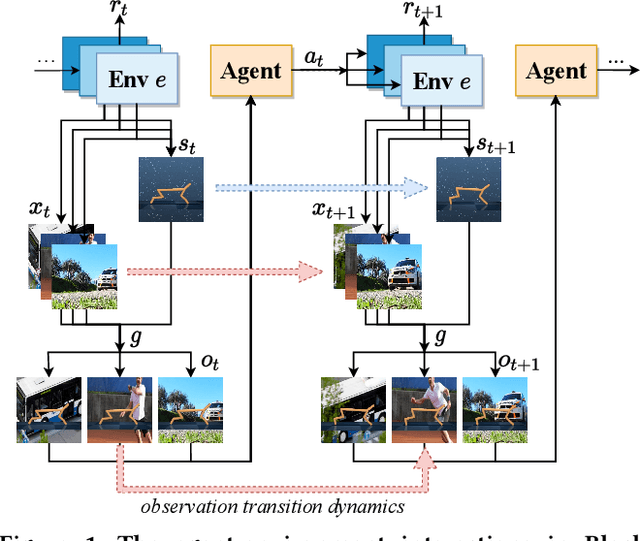
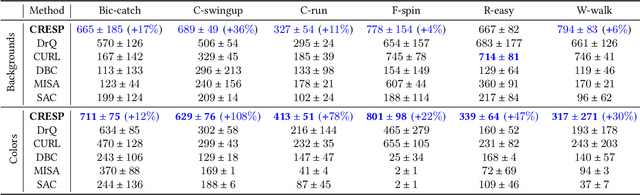
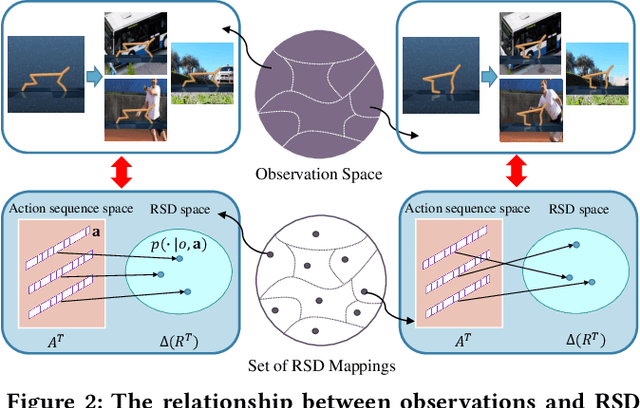
Generalization across different environments with the same tasks is critical for successful applications of visual reinforcement learning (RL) in real scenarios. However, visual distractions -- which are common in real scenes -- from high-dimensional observations can be hurtful to the learned representations in visual RL, thus degrading the performance of generalization. To tackle this problem, we propose a novel approach, namely Characteristic Reward Sequence Prediction (CRESP), to extract the task-relevant information by learning reward sequence distributions (RSDs), as the reward signals are task-relevant in RL and invariant to visual distractions. Specifically, to effectively capture the task-relevant information via RSDs, CRESP introduces an auxiliary task -- that is, predicting the characteristic functions of RSDs -- to learn task-relevant representations, because we can well approximate the high-dimensional distributions by leveraging the corresponding characteristic functions. Experiments demonstrate that CRESP significantly improves the performance of generalization on unseen environments, outperforming several state-of-the-arts on DeepMind Control tasks with different visual distractions.