 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Task-relevant Representations for Generalization via Characteristic Functions of Reward Sequence Distributions
Paper and Code
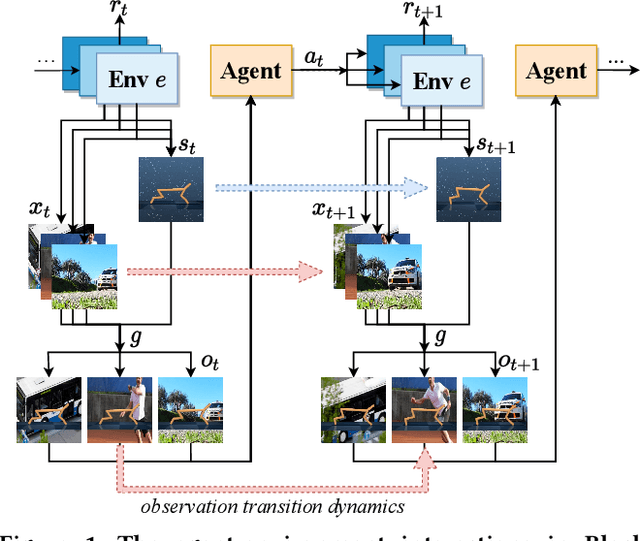
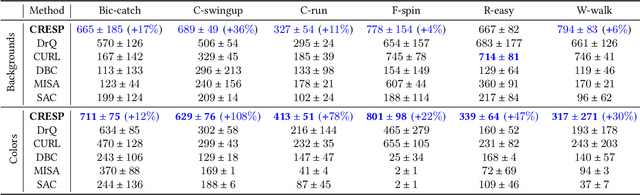
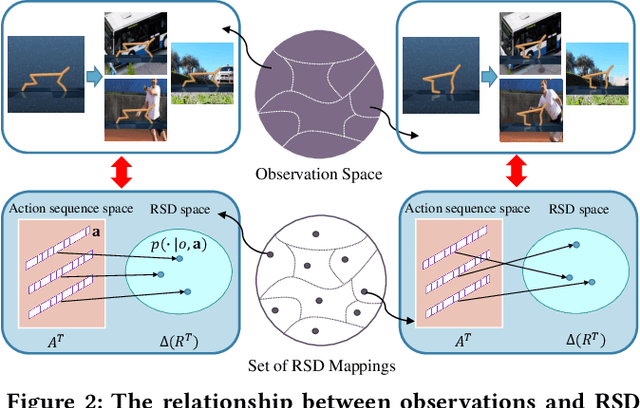
Generalization across different environments with the same tasks is critical for successful applications of visual reinforcement learning (RL) in real scenarios. However, visual distractions -- which are common in real scenes -- from high-dimensional observations can be hurtful to the learned representations in visual RL, thus degrading the performance of generalization. To tackle this problem, we propose a novel approach, namely Characteristic Reward Sequence Prediction (CRESP), to extract the task-relevant information by learning reward sequence distributions (RSDs), as the reward signals are task-relevant in RL and invariant to visual distractions. Specifically, to effectively capture the task-relevant information via RSDs, CRESP introduces an auxiliary task -- that is, predicting the characteristic functions of RSDs -- to learn task-relevant representations, because we can well approximate the high-dimensional distributions by leveraging the corresponding characteristic functions. Experiments demonstrate that CRESP significantly improves the performance of generalization on unseen environments, outperforming several state-of-the-arts on DeepMind Control tasks with different visual distractions.