 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpt-Verifier: Unleashing the Power of LLMs for Optimization Modeling via Dual-Side Verification
May 28, 2026Building mathematical optimization models is critical in operations research (OR), while it requires substantial human expertise. Recent advancements have utilized large language models (LLMs) to automate this modeling process. However, existing works often struggle to verify the correctness of the generated optimization models, without checking the rationality of the constraints and variables or the validity of solutions to the generated models. This hampers the subsequent verification and correction steps, and thus it severely hurts the modeling accuracy. To address this challenge, we propose a novel LLM-based framework with Dual-side Verification (Opt-Verifier) from both structure and solution perspectives, thereby improving the modeling accuracy. The structure-side verification ensures that the modeling structure of the generated optimization models aligns with the original problem description, accurately capturing the problem's constraints and requirements. Meanwhile, the solution-side verification interprets and evaluates the solutions' validity, confirming that the optimization models are logically and mathematically sound. Experiments on popular benchmarks demonstrate that our approach achieves over 20\% improvement in accuracy.
State Sequences Prediction via Fourier Transform for Representation Learning
Oct 24, 2023While deep reinforcement learning (RL) has been demonstrated effective in solving complex control tasks, sample efficiency remains a key challenge due to the large amounts of data required for remarkable performance. Existing research explores the application of representation learning for data-efficient RL, e.g., learning predictive representations by predicting long-term future states. However, many existing methods do not fully exploit the structural information inherent in sequential state signals, which can potentially improve the quality of long-term decision-making but is difficult to discern in the time domain. To tackle this problem, we propose State Sequences Prediction via Fourier Transform (SPF), a novel method that exploits the frequency domain of state sequences to extract the underlying patterns in time series data for learning expressive representations efficiently. Specifically, we theoretically analyze the existence of structural information in state sequences, which is closely related to policy performance and signal regularity, and then propose to predict the Fourier transform of infinite-step future state sequences to extract such information. One of the appealing features of SPF is that it is simple to implement while not requiring storage of infinite-step future states as prediction targets. Experiments demonstrate that the proposed method outperforms several state-of-the-art algorithms in terms of both sample efficiency and performance.
Generalization in Visual Reinforcement Learning with the Reward Sequence Distribution
Feb 19, 2023



Generalization in partially observed markov decision processes (POMDPs) is critical for successful applications of visual reinforcement learning (VRL) in real scenarios. A widely used idea is to learn task-relevant representations that encode task-relevant information of common features in POMDPs, i.e., rewards and transition dynamics. As transition dynamics in the latent state space -- which are task-relevant and invariant to visual distractions -- are unknown to the agents, existing methods alternatively use transition dynamics in the observation space to extract task-relevant information in transition dynamics. However, such transition dynamics in the observation space involve task-irrelevant visual distractions, degrading the generalization performance of VRL methods. To tackle this problem, we propose the reward sequence distribution conditioned on the starting observation and the predefined subsequent action sequence (RSD-OA). The appealing features of RSD-OA include that: (1) RSD-OA is invariant to visual distractions, as it is conditioned on the predefined subsequent action sequence without task-irrelevant information from transition dynamics, and (2) the reward sequence captures long-term task-relevant information in both rewards and transition dynamics. Experiments demonstrate that our representation learning approach based on RSD-OA significantly improves the generalization performance on unseen environments, outperforming several state-of-the-arts on DeepMind Control tasks with visual distractions.
Learning Task-relevant Representations for Generalization via Characteristic Functions of Reward Sequence Distributions
May 20, 2022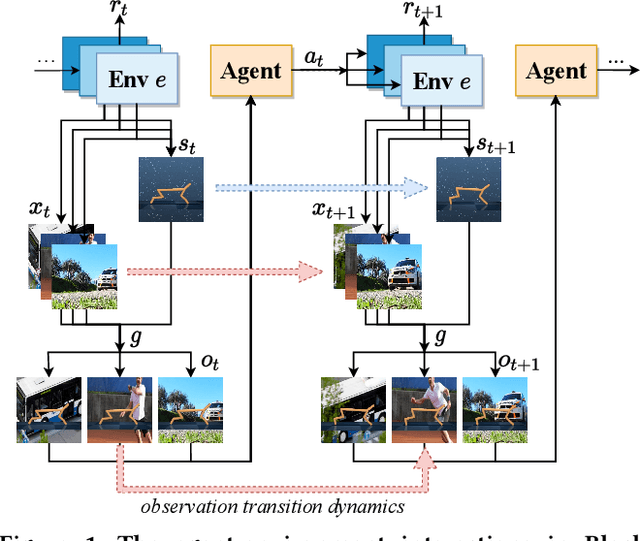
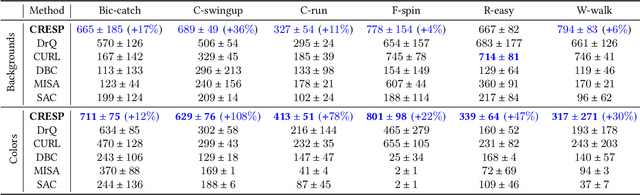
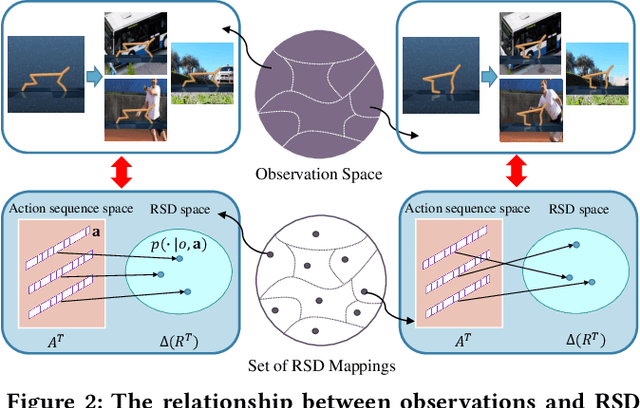
Generalization across different environments with the same tasks is critical for successful applications of visual reinforcement learning (RL) in real scenarios. However, visual distractions -- which are common in real scenes -- from high-dimensional observations can be hurtful to the learned representations in visual RL, thus degrading the performance of generalization. To tackle this problem, we propose a novel approach, namely Characteristic Reward Sequence Prediction (CRESP), to extract the task-relevant information by learning reward sequence distributions (RSDs), as the reward signals are task-relevant in RL and invariant to visual distractions. Specifically, to effectively capture the task-relevant information via RSDs, CRESP introduces an auxiliary task -- that is, predicting the characteristic functions of RSDs -- to learn task-relevant representations, because we can well approximate the high-dimensional distributions by leveraging the corresponding characteristic functions. Experiments demonstrate that CRESP significantly improves the performance of generalization on unseen environments, outperforming several state-of-the-arts on DeepMind Control tasks with different visual distractions.