 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.
Towards Scale-Aware Low-Light Enhancement via Structure-Guided Transformer Design
Apr 18, 2025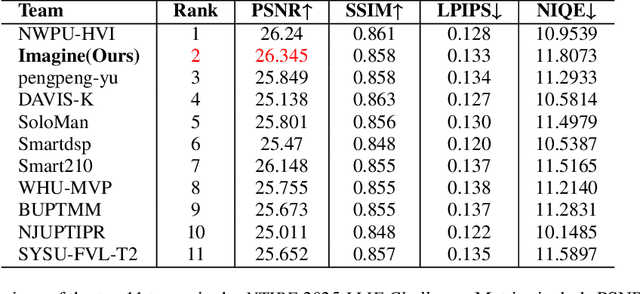



Current Low-light Image Enhancement (LLIE) techniques predominantly rely on either direct Low-Light (LL) to Normal-Light (NL) mappings or guidance from semantic features or illumination maps. Nonetheless, the intrinsic ill-posedness of LLIE and the difficulty in retrieving robust semantics from heavily corrupted images hinder their effectiveness in extremely low-light environments. To tackle this challenge, we present SG-LLIE, a new multi-scale CNN-Transformer hybrid framework guided by structure priors. Different from employing pre-trained models for the extraction of semantics or illumination maps, we choose to extract robust structure priors based on illumination-invariant edge detectors. Moreover, we develop a CNN-Transformer Hybrid Structure-Guided Feature Extractor (HSGFE) module at each scale with in the UNet encoder-decoder architecture. Besides the CNN blocks which excels in multi-scale feature extraction and fusion, we introduce a Structure-Guided Transformer Block (SGTB) in each HSGFE that incorporates structural priors to modulate the enhancement process. Extensive experiments show that our method achieves state-of-the-art performance on several LLIE benchmarks in both quantitative metrics and visual quality. Our solution ranks second in the NTIRE 2025 Low-Light Enhancement Challenge. Code is released at https://github.com/minyan8/imagine.
IMFine: 3D Inpainting via Geometry-guided Multi-view Refinement
Mar 06, 2025Current 3D inpainting and object removal methods are largely limited to front-facing scenes, facing substantial challenges when applied to diverse, "unconstrained" scenes where the camera orientation and trajectory are unrestricted. To bridge this gap, we introduce a novel approach that produces inpainted 3D scenes with consistent visual quality and coherent underlying geometry across both front-facing and unconstrained scenes. Specifically, we propose a robust 3D inpainting pipeline that incorporates geometric priors and a multi-view refinement network trained via test-time adaptation, building on a pre-trained image inpainting model. Additionally, we develop a novel inpainting mask detection technique to derive targeted inpainting masks from object masks, boosting the performance in handling unconstrained scenes. To validate the efficacy of our approach, we create a challenging and diverse benchmark that spans a wide range of scenes. Comprehensive experiments demonstrate that our proposed method substantially outperforms existing state-of-the-art approaches.
Causal Explanations of Image Misclassifications
Jun 28, 2020

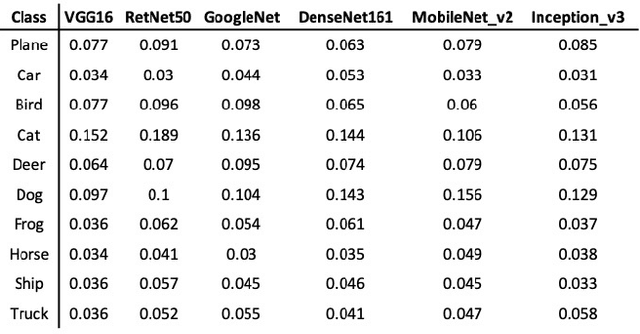
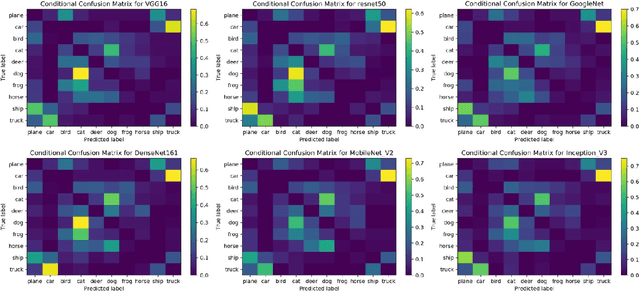
The causal explanation of image misclassifications is an understudied niche, which can potentially provide valuable insights in model interpretability and increase prediction accuracy. This study trains CIFAR-10 on six modern CNN architectures, including VGG16, ResNet50, GoogLeNet, DenseNet161, MobileNet V2, and Inception V3, and explores the misclassification patterns using conditional confusion matrices and misclassification networks. Two causes are identified and qualitatively distinguished: morphological similarity and non-essential information interference. The former cause is not model dependent, whereas the latter is inconsistent across all six models. To reduce the misclassifications caused by non-essential information interference, this study erases the pixels within the bonding boxes anchored at the top 5% pixels of the saliency map. This method first verifies the cause; then by directly modifying the cause it reduces the misclassification. Future studies will focus on quantitatively differentiating the two causes of misclassifications, generalizing the anchor-box based inference modification method to reduce misclassification, exploring the interactions of the two causes in misclassifications.
Unsupervised Feature Selection via Multi-step Markov Transition Probability
May 29, 2020
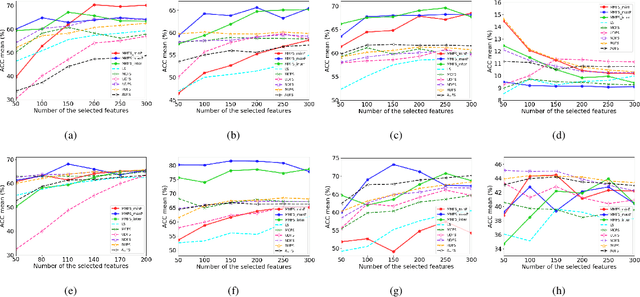
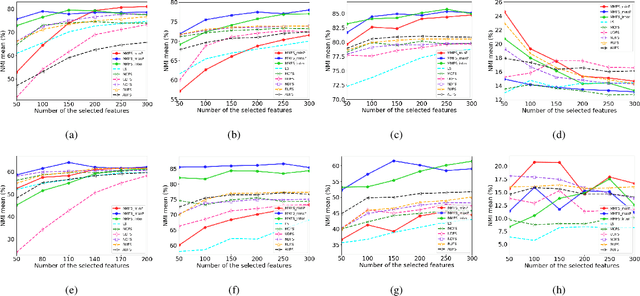
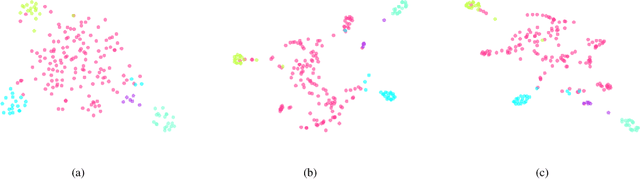
Feature selection is a widely used dimension reduction technique to select feature subsets because of its interpretability. Many methods have been proposed and achieved good results, in which the relationships between adjacent data points are mainly concerned. But the possible associations between data pairs that are may not adjacent are always neglected. Different from previous methods, we propose a novel and very simple approach for unsupervised feature selection, named MMFS (Multi-step Markov transition probability for Feature Selection). The idea is using multi-step Markov transition probability to describe the relation between any data pair. Two ways from the positive and negative viewpoints are employed respectively to keep the data structure after feature selection. From the positive viewpoint, the maximum transition probability that can be reached in a certain number of steps is used to describe the relation between two points. Then, the features which can keep the compact data structure are selected. From the viewpoint of negative, the minimum transition probability that can be reached in a certain number of steps is used to describe the relation between two points. On the contrary, the features that least maintain the loose data structure are selected. And the two ways can also be combined. Thus three algorithms are proposed. Our main contributions are a novel feature section approach which uses multi-step transition probability to characterize the data structure, and three algorithms proposed from the positive and negative aspects for keeping data structure. The performance of our approach is compared with the state-of-the-art methods on eight real-world data sets, and the experimental results show that the proposed MMFS is effective in unsupervised feature selection.