 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCamDirector: Towards Long-Term Coherent Video Trajectory Editing
Feb 27, 2026Video (camera) trajectory editing aims to synthesize new videos that follow user-defined camera paths while preserving scene content and plausibly inpainting previously unseen regions, upgrading amateur footage into professionally styled videos. Existing VTE methods struggle with precise camera control and long-range consistency because they either inject target poses through a limited-capacity embedding or rely on single-frame warping with only implicit cross-frame aggregation in video diffusion models. To address these issues, we introduce a new VTE framework that 1) explicitly aggregates information across the entire source video via a hybrid warping scheme. Specifically, static regions are progressively fused into a world cache then rendered to target camera poses, while dynamic regions are directly warped; their fusion yields globally consistent coarse frames that guide refinement. 2) processes video segments jointly with their history via a history-guided autoregressive diffusion model, while the world cache is incrementally updated to reinforce already inpainted content, enabling long-term temporal coherence. Finally, we present iPhone-PTZ, a new VTE benchmark with diverse camera motions and large trajectory variations, and achieve state-of-the-art performance with fewer parameters.
IMFine: 3D Inpainting via Geometry-guided Multi-view Refinement
Mar 06, 2025Current 3D inpainting and object removal methods are largely limited to front-facing scenes, facing substantial challenges when applied to diverse, "unconstrained" scenes where the camera orientation and trajectory are unrestricted. To bridge this gap, we introduce a novel approach that produces inpainted 3D scenes with consistent visual quality and coherent underlying geometry across both front-facing and unconstrained scenes. Specifically, we propose a robust 3D inpainting pipeline that incorporates geometric priors and a multi-view refinement network trained via test-time adaptation, building on a pre-trained image inpainting model. Additionally, we develop a novel inpainting mask detection technique to derive targeted inpainting masks from object masks, boosting the performance in handling unconstrained scenes. To validate the efficacy of our approach, we create a challenging and diverse benchmark that spans a wide range of scenes. Comprehensive experiments demonstrate that our proposed method substantially outperforms existing state-of-the-art approaches.
SCE-MAE: Selective Correspondence Enhancement with Masked Autoencoder for Self-Supervised Landmark Estimation
May 28, 2024Self-supervised landmark estimation is a challenging task that demands the formation of locally distinct feature representations to identify sparse facial landmarks in the absence of annotated data. To tackle this task, existing state-of-the-art (SOTA) methods (1) extract coarse features from backbones that are trained with instance-level self-supervised learning (SSL) paradigms, which neglect the dense prediction nature of the task, (2) aggregate them into memory-intensive hypercolumn formations, and (3) supervise lightweight projector networks to naively establish full local correspondences among all pairs of spatial features. In this paper, we introduce SCE-MAE, a framework that (1) leverages the MAE, a region-level SSL method that naturally better suits the landmark prediction task, (2) operates on the vanilla feature map instead of on expensive hypercolumns, and (3) employs a Correspondence Approximation and Refinement Block (CARB) that utilizes a simple density peak clustering algorithm and our proposed Locality-Constrained Repellence Loss to directly hone only select local correspondences. We demonstrate through extensive experiments that SCE-MAE is highly effective and robust, outperforming existing SOTA methods by large margins of approximately 20%-44% on the landmark matching and approximately 9%-15% on the landmark detection tasks.
SPCL: A New Framework for Domain Adaptive Semantic Segmentation via Semantic Prototype-based Contrastive Learning
Nov 24, 2021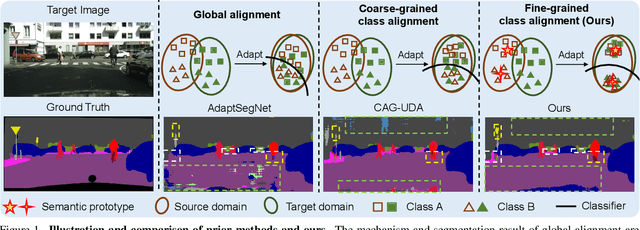
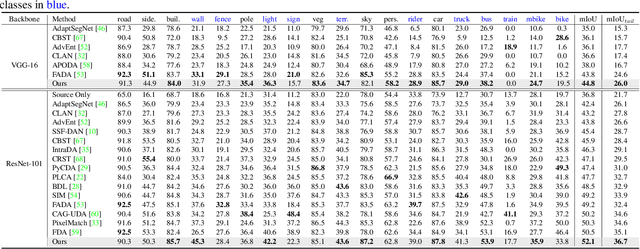
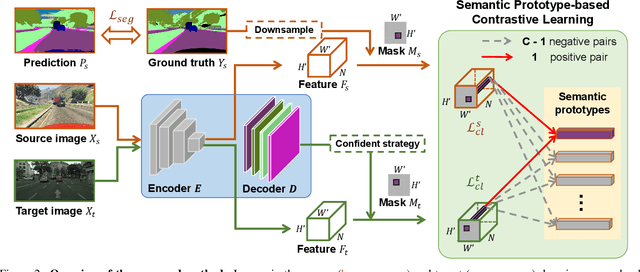

Although there is significant progress in supervised semantic segmentation, it remains challenging to deploy the segmentation models to unseen domains due to domain biases. Domain adaptation can help in this regard by transferring knowledge from a labeled source domain to an unlabeled target domain. Previous methods typically attempt to perform the adaptation on global features, however, the local semantic affiliations accounting for each pixel in the feature space are often ignored, resulting in less discriminability. To solve this issue, we propose a novel semantic prototype-based contrastive learning framework for fine-grained class alignment. Specifically, the semantic prototypes provide supervisory signals for per-pixel discriminative representation learning and each pixel of source and target domains in the feature space is required to reflect the content of the corresponding semantic prototype. In this way, our framework is able to explicitly make intra-class pixel representations closer and inter-class pixel representations further apart to improve the robustness of the segmentation model as well as alleviate the domain shift problem. Our method is easy to implement and attains superior results compared to state-of-the-art approaches, as is demonstrated with a number of experiments. The code is publicly available at [this https URL](https://github.com/BinhuiXie/SPCL).