 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoPDE: Reliable Agentic PDE Solving via Explicitly Represented Solver Strategies
Jun 09, 2026Numerical solvers for partial differential equations (PDEs) are core computational tools in science and engineering. Building reliable PDE solvers requires not only executable code, but a numerical solver strategy, a set of decisions about discretization, stabilization, solver configuration, and resolution control, that matches the PDE structure. Recent LLM-based coding agents have begun to reduce the programming burden by generating and debugging solver implementations. However, they typically move directly from a PDE problem to solver code, leaving the solver strategy implicit in implementation details. Feedback from a failed solve is therefore routed back to code edits rather than to the underlying strategy, so numerical decisions remain hard to check before code is generated and hard to revise using numerical evidence when it fails. To address this limitation, we propose AutoPDE, a code agent that maintains the solver strategy as an explicitly represented object throughout the solving process: an independent, inspectable object that is built before any code is written and can be revised, using numerical evidence, whenever a solve fails. AutoPDE builds and maintains this object in three stages, all drawing from a library of reusable PDE-solving skills: PDE analysis identifies the equation type and algebraic structure; numerical method selection chooses a numerical method that matches the analysis result and commits to a discretization, stabilization, and linear solver accordingly; and adaptive tuning runs low-cost pilot solves to calibrate resolution and tolerances under the prescribed accuracy and runtime budget. We evaluate AutoPDE on the PDE Agent Bench, where experimental results show that AutoPDE achieves a pass rate of $54.5%$, improving over the strongest baseline by $14.2$ percentage points.
Accurate and Scalable Graph Neural Networks via Message Invariance
Feb 27, 2025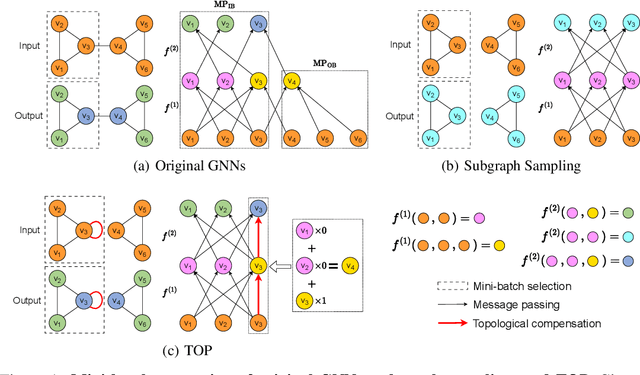

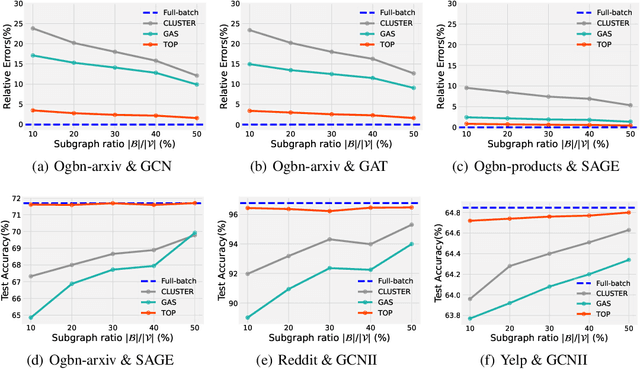

Message passing-based graph neural networks (GNNs) have achieved great success in many real-world applications. For a sampled mini-batch of target nodes, the message passing process is divided into two parts: message passing between nodes within the batch (MP-IB) and message passing from nodes outside the batch to those within it (MP-OB). However, MP-OB recursively relies on higher-order out-of-batch neighbors, leading to an exponentially growing computational cost with respect to the number of layers. Due to the neighbor explosion, the whole message passing stores most nodes and edges on the GPU such that many GNNs are infeasible to large-scale graphs. To address this challenge, we propose an accurate and fast mini-batch approach for large graph transductive learning, namely topological compensation (TOP), which obtains the outputs of the whole message passing solely through MP-IB, without the costly MP-OB. The major pillar of TOP is a novel concept of message invariance, which defines message-invariant transformations to convert costly MP-OB into fast MP-IB. This ensures that the modified MP-IB has the same output as the whole message passing. Experiments demonstrate that TOP is significantly faster than existing mini-batch methods by order of magnitude on vast graphs (millions of nodes and billions of edges) with limited accuracy degradation.
Soft policy optimization using dual-track advantage estimator
Sep 15, 2020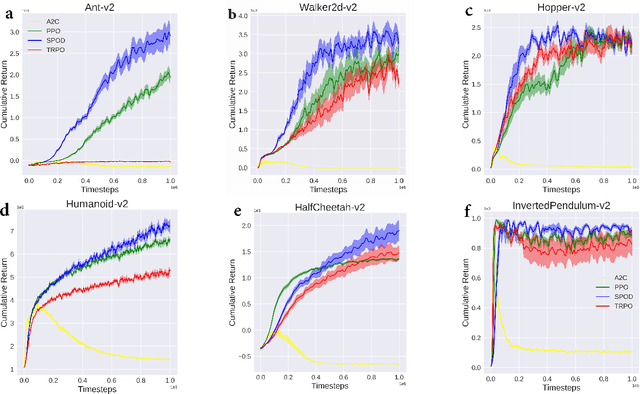
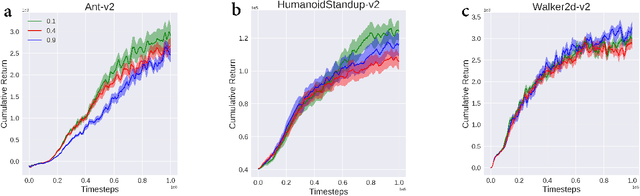
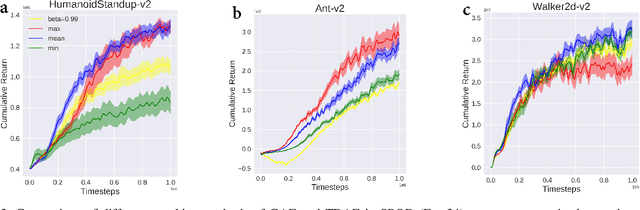
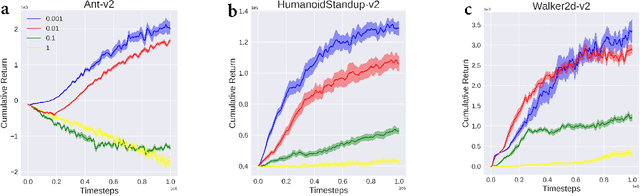
In reinforcement learning (RL), we always expect the agent to explore as many states as possible in the initial stage of training and exploit the explored information in the subsequent stage to discover the most returnable trajectory. Based on this principle, in this paper, we soften the proximal policy optimization by introducing the entropy and dynamically setting the temperature coefficient to balance the opportunity of exploration and exploitation. While maximizing the expected reward, the agent will also seek other trajectories to avoid the local optimal policy. Nevertheless, the increase of randomness induced by entropy will reduce the train speed in the early stage. Integrating the temporal-difference (TD) method and the general advantage estimator (GAE), we propose the dual-track advantage estimator (DTAE) to accelerate the convergence of value functions and further enhance the performance of the algorithm. Compared with other on-policy RL algorithms on the Mujoco environment, the proposed method not only significantly speeds up the training but also achieves the most advanced results in cumulative return.