 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft policy optimization using dual-track advantage estimator
Paper and Code
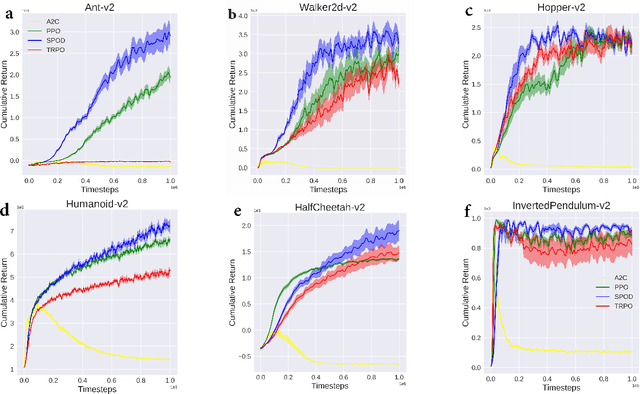
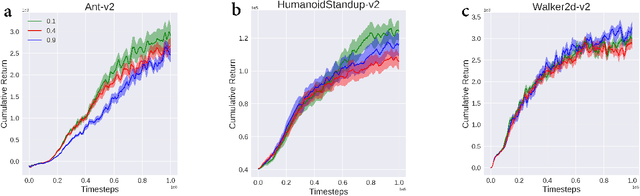
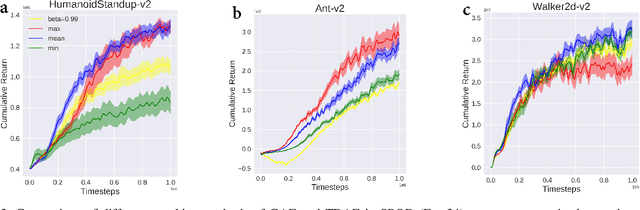
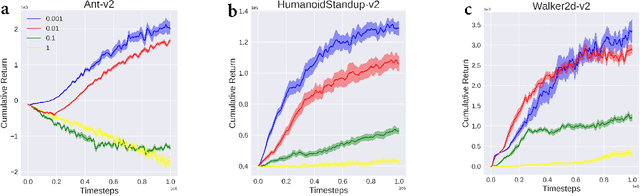
In reinforcement learning (RL), we always expect the agent to explore as many states as possible in the initial stage of training and exploit the explored information in the subsequent stage to discover the most returnable trajectory. Based on this principle, in this paper, we soften the proximal policy optimization by introducing the entropy and dynamically setting the temperature coefficient to balance the opportunity of exploration and exploitation. While maximizing the expected reward, the agent will also seek other trajectories to avoid the local optimal policy. Nevertheless, the increase of randomness induced by entropy will reduce the train speed in the early stage. Integrating the temporal-difference (TD) method and the general advantage estimator (GAE), we propose the dual-track advantage estimator (DTAE) to accelerate the convergence of value functions and further enhance the performance of the algorithm. Compared with other on-policy RL algorithms on the Mujoco environment, the proposed method not only significantly speeds up the training but also achieves the most advanced results in cumulative return.