 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMastering the Game of Go with Self-play Experience Replay
Jan 06, 2026The game of Go has long served as a benchmark for artificial intelligence, demanding sophisticated strategic reasoning and long-term planning. Previous approaches such as AlphaGo and its successors, have predominantly relied on model-based Monte-Carlo Tree Search (MCTS). In this work, we present QZero, a novel model-free reinforcement learning algorithm that forgoes search during training and learns a Nash equilibrium policy through self-play and off-policy experience replay. Built upon entropy-regularized Q-learning, QZero utilizes a single Q-value network to unify policy evaluation and improvement. Starting tabula rasa without human data and trained for 5 months with modest compute resources (7 GPUs), QZero achieved a performance level comparable to that of AlphaGo. This demonstrates, for the first time, the efficiency of using model-free reinforcement learning to master the game of Go, as well as the feasibility of off-policy reinforcement learning in solving large-scale and complex environments.
Evaluation of Google Translate for Mandarin Chinese translation using sentiment and semantic analysis
Sep 08, 2024



Machine translation using large language models (LLMs) is having a significant global impact, making communication easier. Mandarin Chinese is the official language used for communication by the government, education institutes, and media in China. In this study, we provide an automated assessment of machine translation models with human experts using sentiment and semantic analysis. In order to demonstrate our framework, we select classic early twentieth-century novel 'The True Story of Ah Q' with selected Mandarin Chinese to English translations. We also us Google Translate to generate the given text into English and then conduct a chapter-wise sentiment analysis and semantic analysis to compare the extracted sentiments across the different translations. We utilise LLMs for semantic and sentiment analysis. Our results indicate that the precision of Google Translate differs both in terms of semantic and sentiment analysis when compared to human expert translations. We find that Google Translate is unable to translate some of the specific words or phrases in Chinese, such as Chinese traditional allusions. The mistranslations have to its lack of contextual significance and historical knowledge of China. Thus, this framework brought us some new insights about machine translation for Chinese Mandarin. The future work can explore other languages or types of texts with this framework.
LFSRDiff: Light Field Image Super-Resolution via Diffusion Models
Nov 27, 2023



Light field (LF) image super-resolution (SR) is a challenging problem due to its inherent ill-posed nature, where a single low-resolution (LR) input LF image can correspond to multiple potential super-resolved outcomes. Despite this complexity, mainstream LF image SR methods typically adopt a deterministic approach, generating only a single output supervised by pixel-wise loss functions. This tendency often results in blurry and unrealistic results. Although diffusion models can capture the distribution of potential SR results by iteratively predicting Gaussian noise during the denoising process, they are primarily designed for general images and struggle to effectively handle the unique characteristics and information present in LF images. To address these limitations, we introduce LFSRDiff, the first diffusion-based LF image SR model, by incorporating the LF disentanglement mechanism. Our novel contribution includes the introduction of a disentangled U-Net for diffusion models, enabling more effective extraction and fusion of both spatial and angular information within LF images. Through comprehensive experimental evaluations and comparisons with the state-of-the-art LF image SR methods, the proposed approach consistently produces diverse and realistic SR results. It achieves the highest perceptual metric in terms of LPIPS. It also demonstrates the ability to effectively control the trade-off between perception and distortion. The code is available at \url{https://github.com/chaowentao/LFSRDiff}.
OccCasNet: Occlusion-aware Cascade Cost Volume for Light Field Depth Estimation
May 28, 2023



Light field (LF) depth estimation is a crucial task with numerous practical applications. However, mainstream methods based on the multi-view stereo (MVS) are resource-intensive and time-consuming as they need to construct a finer cost volume. To address this issue and achieve a better trade-off between accuracy and efficiency, we propose an occlusion-aware cascade cost volume for LF depth (disparity) estimation. Our cascaded strategy reduces the sampling number while keeping the sampling interval constant during the construction of a finer cost volume. We also introduce occlusion maps to enhance accuracy in constructing the occlusion-aware cost volume. Specifically, we first obtain the coarse disparity map through the coarse disparity estimation network. Then, the sub-aperture images (SAIs) of side views are warped to the center view based on the initial disparity map. Next, we propose photo-consistency constraints between the warped SAIs and the center SAI to generate occlusion maps for each SAI. Finally, we introduce the coarse disparity map and occlusion maps to construct an occlusion-aware refined cost volume, enabling the refined disparity estimation network to yield a more precise disparity map. Extensive experiments demonstrate the effectiveness of our method. Compared with state-of-the-art methods, our method achieves a superior balance between accuracy and efficiency and ranks first in terms of MSE and Q25 metrics among published methods on the HCI 4D benchmark. The code and model of the proposed method are available at https://github.com/chaowentao/OccCasNet.
Learning Sub-Pixel Disparity Distribution for Light Field Depth Estimation
Aug 20, 2022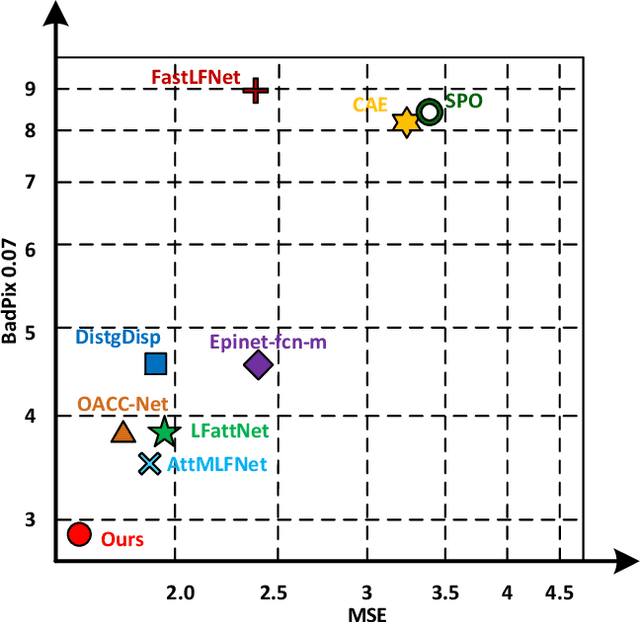
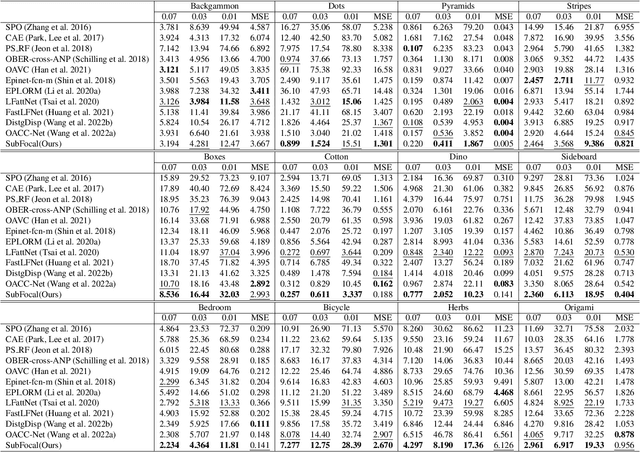
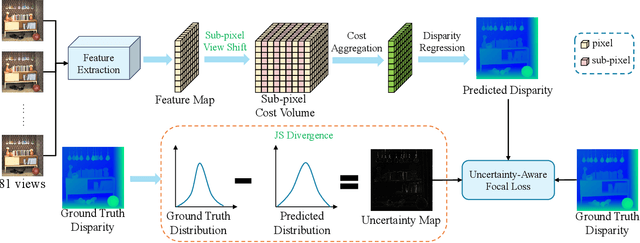
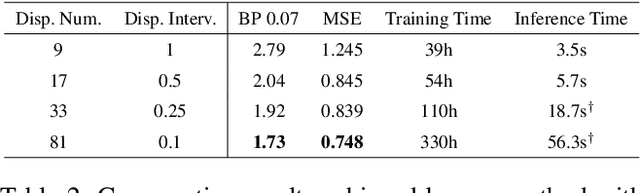
Existing light field (LF) depth estimation methods generally consider depth estimation as a regression problem, supervised by a pixel-wise L1 loss between the regressed disparity map and the groundtruth one. However, the disparity map is only a sub-space projection (i.e., an expectation) of the disparity distribution, while the latter one is more essential for models to learn. In this paper, we propose a simple yet effective method to learn the sub-pixel disparity distribution by fully utilizing the power of deep networks. In our method, we construct the cost volume at sub-pixel level to produce a finer depth distribution and design an uncertainty-aware focal loss to supervise the disparity distribution to be close to the groundtruth one. Extensive experimental results demonstrate the effectiveness of our method. Our method, called SubFocal, ranks the first place among 99 submitted algorithms on the HCI 4D LF Benchmark in terms of all the five accuracy metrics (i.e., BadPix0.01, BadPix0.03, BadPix0.07, MSE and Q25), and significantly outperforms recent state-of-the-art LF depth methods such as OACC-Net and AttMLFNet. Code and model are available at https://github.com/chaowentao/SubFocal.
Soft policy optimization using dual-track advantage estimator
Sep 15, 2020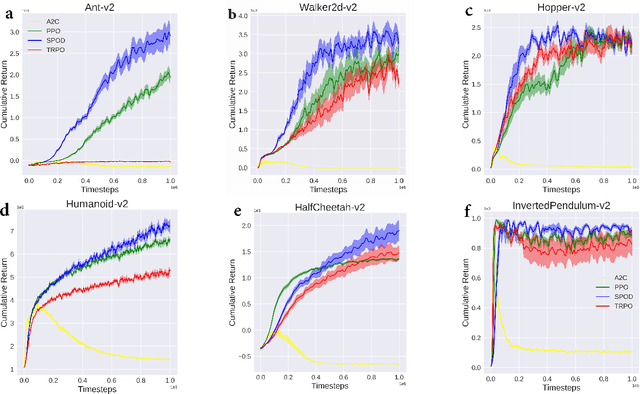
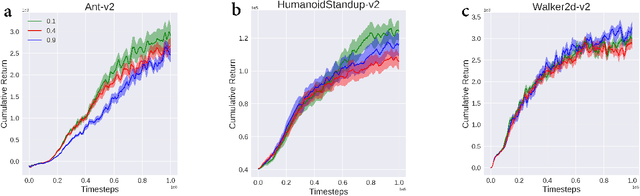
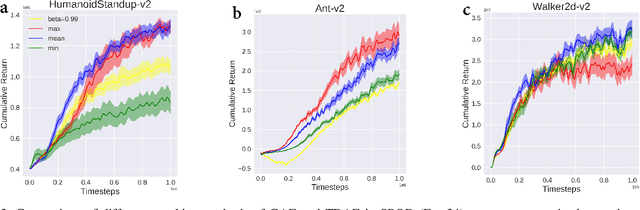
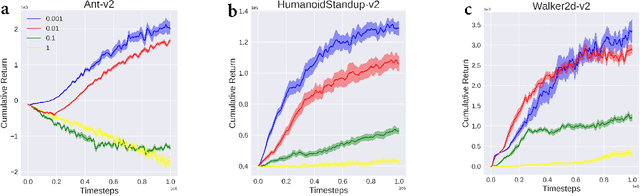
In reinforcement learning (RL), we always expect the agent to explore as many states as possible in the initial stage of training and exploit the explored information in the subsequent stage to discover the most returnable trajectory. Based on this principle, in this paper, we soften the proximal policy optimization by introducing the entropy and dynamically setting the temperature coefficient to balance the opportunity of exploration and exploitation. While maximizing the expected reward, the agent will also seek other trajectories to avoid the local optimal policy. Nevertheless, the increase of randomness induced by entropy will reduce the train speed in the early stage. Integrating the temporal-difference (TD) method and the general advantage estimator (GAE), we propose the dual-track advantage estimator (DTAE) to accelerate the convergence of value functions and further enhance the performance of the algorithm. Compared with other on-policy RL algorithms on the Mujoco environment, the proposed method not only significantly speeds up the training but also achieves the most advanced results in cumulative return.