 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaskBlur: Spatial and Angular Data Augmentation for Light Field Image Super-Resolution
Oct 09, 2024Data augmentation (DA) is an effective approach for enhancing model performance with limited data, such as light field (LF) image super-resolution (SR). LF images inherently possess rich spatial and angular information. Nonetheless, there is a scarcity of DA methodologies explicitly tailored for LF images, and existing works tend to concentrate solely on either the spatial or angular domain. This paper proposes a novel spatial and angular DA strategy named MaskBlur for LF image SR by concurrently addressing spatial and angular aspects. MaskBlur consists of spatial blur and angular dropout two components. Spatial blur is governed by a spatial mask, which controls where pixels are blurred, i.e., pasting pixels between the low-resolution and high-resolution domains. The angular mask is responsible for angular dropout, i.e., selecting which views to perform the spatial blur operation. By doing so, MaskBlur enables the model to treat pixels differently in the spatial and angular domains when super-resolving LF images rather than blindly treating all pixels equally. Extensive experiments demonstrate the efficacy of MaskBlur in significantly enhancing the performance of existing SR methods. We further extend MaskBlur to other LF image tasks such as denoising, deblurring, low-light enhancement, and real-world SR. Code is publicly available at \url{https://github.com/chaowentao/MaskBlur}.
LFSRDiff: Light Field Image Super-Resolution via Diffusion Models
Nov 27, 2023



Light field (LF) image super-resolution (SR) is a challenging problem due to its inherent ill-posed nature, where a single low-resolution (LR) input LF image can correspond to multiple potential super-resolved outcomes. Despite this complexity, mainstream LF image SR methods typically adopt a deterministic approach, generating only a single output supervised by pixel-wise loss functions. This tendency often results in blurry and unrealistic results. Although diffusion models can capture the distribution of potential SR results by iteratively predicting Gaussian noise during the denoising process, they are primarily designed for general images and struggle to effectively handle the unique characteristics and information present in LF images. To address these limitations, we introduce LFSRDiff, the first diffusion-based LF image SR model, by incorporating the LF disentanglement mechanism. Our novel contribution includes the introduction of a disentangled U-Net for diffusion models, enabling more effective extraction and fusion of both spatial and angular information within LF images. Through comprehensive experimental evaluations and comparisons with the state-of-the-art LF image SR methods, the proposed approach consistently produces diverse and realistic SR results. It achieves the highest perceptual metric in terms of LPIPS. It also demonstrates the ability to effectively control the trade-off between perception and distortion. The code is available at \url{https://github.com/chaowentao/LFSRDiff}.
OccCasNet: Occlusion-aware Cascade Cost Volume for Light Field Depth Estimation
May 28, 2023



Light field (LF) depth estimation is a crucial task with numerous practical applications. However, mainstream methods based on the multi-view stereo (MVS) are resource-intensive and time-consuming as they need to construct a finer cost volume. To address this issue and achieve a better trade-off between accuracy and efficiency, we propose an occlusion-aware cascade cost volume for LF depth (disparity) estimation. Our cascaded strategy reduces the sampling number while keeping the sampling interval constant during the construction of a finer cost volume. We also introduce occlusion maps to enhance accuracy in constructing the occlusion-aware cost volume. Specifically, we first obtain the coarse disparity map through the coarse disparity estimation network. Then, the sub-aperture images (SAIs) of side views are warped to the center view based on the initial disparity map. Next, we propose photo-consistency constraints between the warped SAIs and the center SAI to generate occlusion maps for each SAI. Finally, we introduce the coarse disparity map and occlusion maps to construct an occlusion-aware refined cost volume, enabling the refined disparity estimation network to yield a more precise disparity map. Extensive experiments demonstrate the effectiveness of our method. Compared with state-of-the-art methods, our method achieves a superior balance between accuracy and efficiency and ranks first in terms of MSE and Q25 metrics among published methods on the HCI 4D benchmark. The code and model of the proposed method are available at https://github.com/chaowentao/OccCasNet.
Learning Sub-Pixel Disparity Distribution for Light Field Depth Estimation
Aug 20, 2022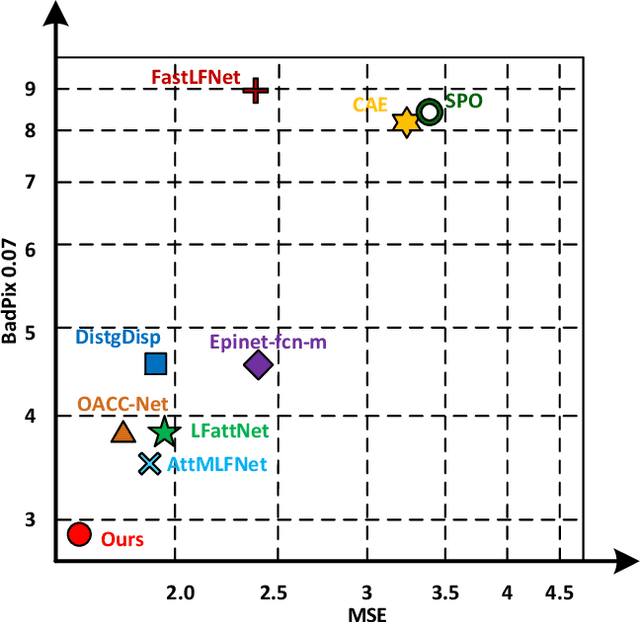
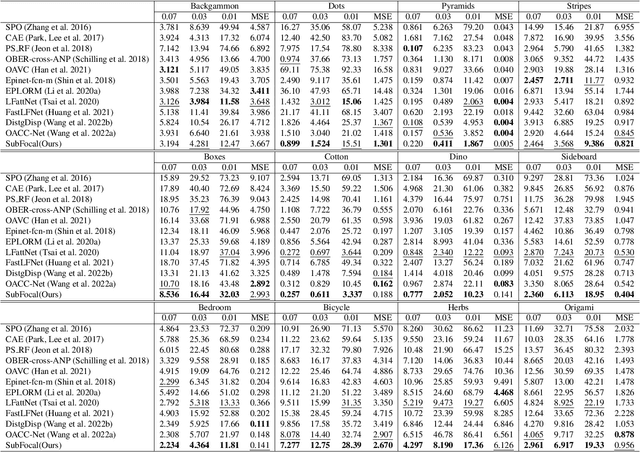
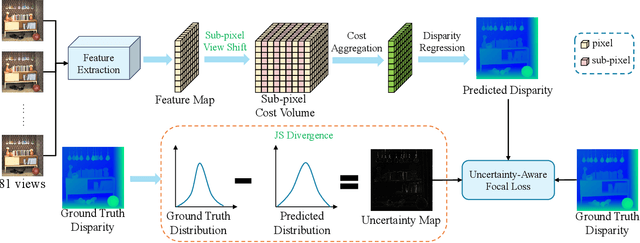
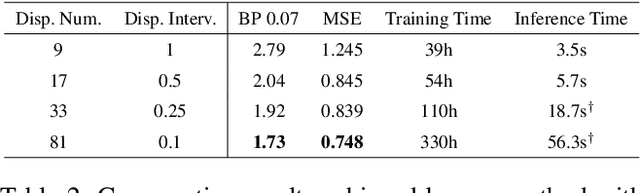
Existing light field (LF) depth estimation methods generally consider depth estimation as a regression problem, supervised by a pixel-wise L1 loss between the regressed disparity map and the groundtruth one. However, the disparity map is only a sub-space projection (i.e., an expectation) of the disparity distribution, while the latter one is more essential for models to learn. In this paper, we propose a simple yet effective method to learn the sub-pixel disparity distribution by fully utilizing the power of deep networks. In our method, we construct the cost volume at sub-pixel level to produce a finer depth distribution and design an uncertainty-aware focal loss to supervise the disparity distribution to be close to the groundtruth one. Extensive experimental results demonstrate the effectiveness of our method. Our method, called SubFocal, ranks the first place among 99 submitted algorithms on the HCI 4D LF Benchmark in terms of all the five accuracy metrics (i.e., BadPix0.01, BadPix0.03, BadPix0.07, MSE and Q25), and significantly outperforms recent state-of-the-art LF depth methods such as OACC-Net and AttMLFNet. Code and model are available at https://github.com/chaowentao/SubFocal.
NTIRE 2021 Challenge on Quality Enhancement of Compressed Video: Methods and Results
May 02, 2021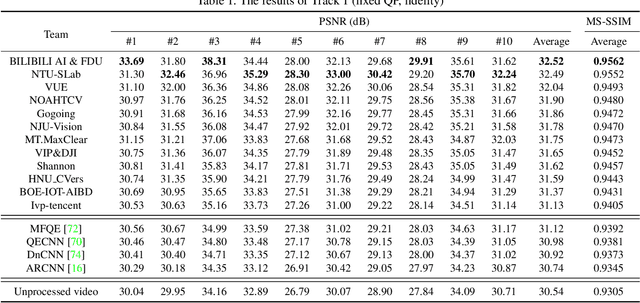
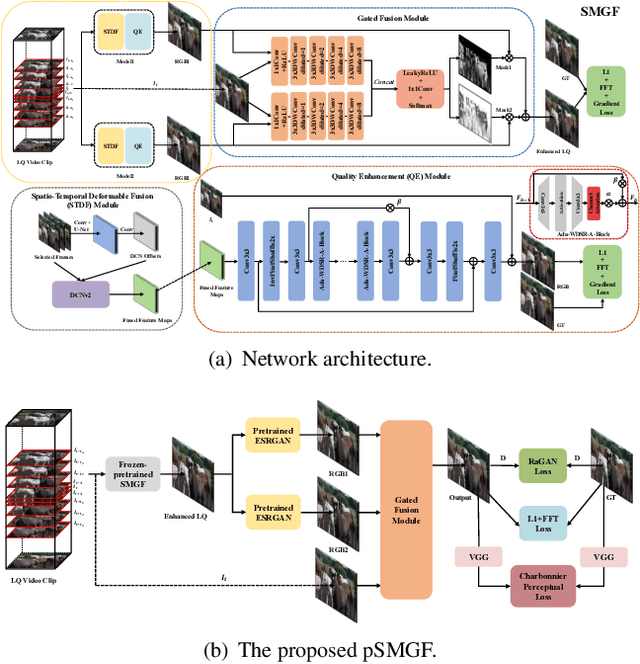
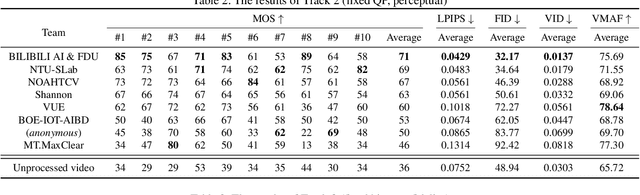
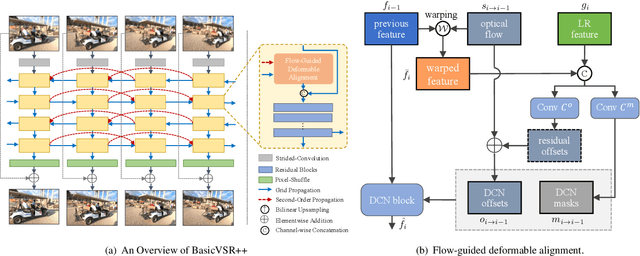
This paper reviews the first NTIRE challenge on quality enhancement of compressed video, with a focus on the proposed methods and results. In this challenge, the new Large-scale Diverse Video (LDV) dataset is employed. The challenge has three tracks. Tracks 1 and 2 aim at enhancing the videos compressed by HEVC at a fixed QP, while Track 3 is designed for enhancing the videos compressed by x265 at a fixed bit-rate. Besides, the quality enhancement of Tracks 1 and 3 targets at improving the fidelity (PSNR), and Track 2 targets at enhancing the perceptual quality. The three tracks totally attract 482 registrations. In the test phase, 12 teams, 8 teams and 11 teams submitted the final results of Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of video quality enhancement. The homepage of the challenge: https://github.com/RenYang-home/NTIRE21_VEnh