 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLP Methods for Detecting Novel LLM Jailbreaks and Keyword Analysis with BERT
Oct 02, 2025

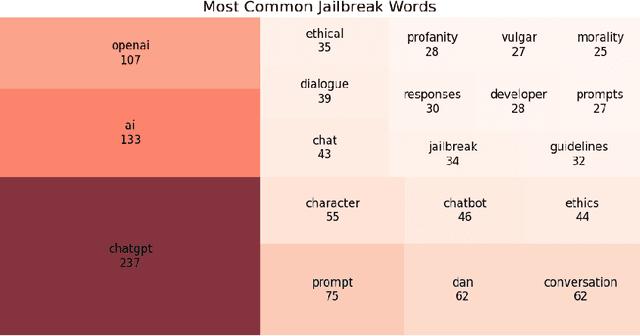
Large Language Models (LLMs) suffer from a range of vulnerabilities that allow malicious users to solicit undesirable responses through manipulation of the input text. These so-called jailbreak prompts are designed to trick the LLM into circumventing the safety guardrails put in place to keep responses acceptable to the developer's policies. In this study, we analyse the ability of different machine learning models to distinguish jailbreak prompts from genuine uses, including looking at our ability to identify jailbreaks that use previously unseen strategies. Our results indicate that using current datasets the best performance is achieved by fine tuning a Bidirectional Encoder Representations from Transformers (BERT) model end-to-end for identifying jailbreaks. We visualise the keywords that distinguish jailbreak from genuine prompts and conclude that explicit reflexivity in prompt structure could be a signal of jailbreak intention.
Evaluation of Google Translate for Mandarin Chinese translation using sentiment and semantic analysis
Sep 08, 2024



Machine translation using large language models (LLMs) is having a significant global impact, making communication easier. Mandarin Chinese is the official language used for communication by the government, education institutes, and media in China. In this study, we provide an automated assessment of machine translation models with human experts using sentiment and semantic analysis. In order to demonstrate our framework, we select classic early twentieth-century novel 'The True Story of Ah Q' with selected Mandarin Chinese to English translations. We also us Google Translate to generate the given text into English and then conduct a chapter-wise sentiment analysis and semantic analysis to compare the extracted sentiments across the different translations. We utilise LLMs for semantic and sentiment analysis. Our results indicate that the precision of Google Translate differs both in terms of semantic and sentiment analysis when compared to human expert translations. We find that Google Translate is unable to translate some of the specific words or phrases in Chinese, such as Chinese traditional allusions. The mistranslations have to its lack of contextual significance and historical knowledge of China. Thus, this framework brought us some new insights about machine translation for Chinese Mandarin. The future work can explore other languages or types of texts with this framework.
Recursive deep learning framework for forecasting the decadal world economic outlook
Jan 25, 2023



Gross domestic product (GDP) is the most widely used indicator in macroeconomics and the main tool for measuring a country's economic ouput. Due to the diversity and complexity of the world economy, a wide range of models have been used, but there are challenges in making decadal GDP forecasts given unexpected changes such as pandemics and wars. Deep learning models are well suited for modeling temporal sequences have been applied for time series forecasting. In this paper, we develop a deep learning framework to forecast the GDP growth rate of the world economy over a decade. We use Penn World Table as the source of our data, taking data from 1980 to 2019, across 13 countries, such as Australia, China, India, the United States and so on. We test multiple deep learning models, LSTM, BD-LSTM, ED-LSTM and CNN, and compared their results with the traditional time series model (ARIMA,VAR). Our results indicate that ED-LSTM is the best performing model. We present a recursive deep learning framework to predict the GDP growth rate in the next ten years. We predict that most countries will experience economic growth slowdown, stagnation or even recession within five years; only China, France and India are predicted to experience stable, or increasing, GDP growth.
Evolutionary bagged ensemble learning
Aug 04, 2022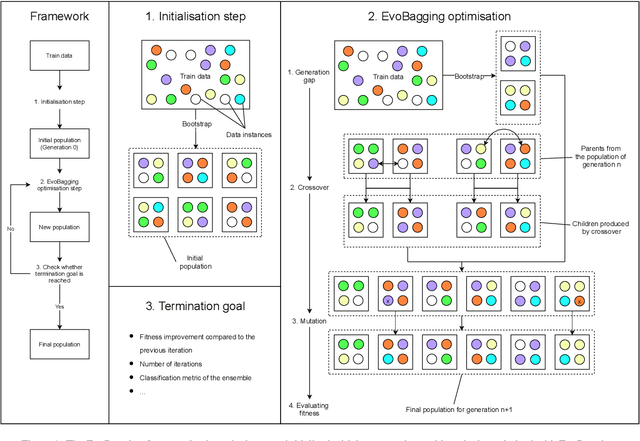


Ensemble learning has gained success in machine learning with major advantages over other learning methods. Bagging is a prominent ensemble learning method that creates subgroups of data, known as bags, that are trained by individual machine learning methods such as decision trees. Random forest is a prominent example of bagging with additional features in the learning process. \textcolor{black}{A limitation of bagging is high bias (model under-fitting) in the aggregated prediction when the individual learners have high biases.} Evolutionary algorithms have been prominent for optimisation problems and also been used for machine learning. Evolutionary algorithms are gradient-free methods with a population of candidate solutions that maintain diversity for creating new solutions. In conventional bagged ensemble learning, the bags are created once and the content, in terms of the training examples, is fixed over the learning process. In our paper, we propose evolutionary bagged ensemble learning, where we utilise evolutionary algorithms to evolve the content of the bags in order to enhance the ensemble by providing diversity in the bags iteratively. The results show that our evolutionary ensemble bagging method outperforms conventional ensemble methods (bagging and random forests) for several benchmark datasets under certain constraints. Evolutionary bagging can inherently sustain a diverse set of bags without sacrificing any data.