 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollectionLoRA: Collecting 50 Effects in 1 LoRA via Multi-Teacher On-Policy Distillation
May 27, 2026Customized image editing aims to equip pre-trained diffusion models with specific visual effects using limited paired data, typically via Low-Rank Adaptation (LoRA). As the number of desired effects grows, storing and dynamically loading numerous these effect LoRAs significantly increases deployment overhead. Furthermore, current pipelines typically cascade these effect LoRAs with acceleration modules for fast generation, which triggers severe parameter interference and results in concept bleeding and style degradation. We propose CollectionLoRA, a multi-teacher on-policy distillation framework capable of distilling the concepts of up to 50 different effect LoRAs along with few-step generation capabilities into a single LoRA. This fundamentally resolves the feature interference issue and significantly reduces deployment costs. Specifically, the method introduces (i) a Probabilistic Dual-Stream Routing mechanism that enables the model to randomly switch between data sources during training, effectively enhancing its generalization in unseen scenarios; (ii) an Asymmetric Orthogonal Prompting strategy to achieve concept isolation within the prompt space; (iii) a Coarse-to-Fine Distillation Objective to mitigate the distribution gap between the teacher and student models. Extensive evaluations show that CollectionLoRA distills all customized effects and few-step generation into a single LoRA, reducing deployment overhead while achieving concept fidelity comparable to or better than independently trained teacher models. Code: https://github.com/Qwen-Applications/CollectionLoRA
Bind-Your-Avatar: Multi-Talking-Character Video Generation with Dynamic 3D-mask-based Embedding Router
Jun 24, 2025



Recent years have witnessed remarkable advances in audio-driven talking head generation. However, existing approaches predominantly focus on single-character scenarios. While some methods can create separate conversation videos between two individuals, the critical challenge of generating unified conversation videos with multiple physically co-present characters sharing the same spatial environment remains largely unaddressed. This setting presents two key challenges: audio-to-character correspondence control and the lack of suitable datasets featuring multi-character talking videos within the same scene. To address these challenges, we introduce Bind-Your-Avatar, an MM-DiT-based model specifically designed for multi-talking-character video generation in the same scene. Specifically, we propose (1) A novel framework incorporating a fine-grained Embedding Router that binds `who' and `speak what' together to address the audio-to-character correspondence control. (2) Two methods for implementing a 3D-mask embedding router that enables frame-wise, fine-grained control of individual characters, with distinct loss functions based on observed geometric priors and a mask refinement strategy to enhance the accuracy and temporal smoothness of the predicted masks. (3) The first dataset, to the best of our knowledge, specifically constructed for multi-talking-character video generation, and accompanied by an open-source data processing pipeline, and (4) A benchmark for the dual-talking-characters video generation, with extensive experiments demonstrating superior performance over multiple state-of-the-art methods.
GDO: Gradual Domain Osmosis
Jan 31, 2025



In this paper, we propose a new method called Gradual Domain Osmosis, which aims to solve the problem of smooth knowledge migration from source domain to target domain in Gradual Domain Adaptation (GDA). Traditional Gradual Domain Adaptation methods mitigate domain bias by introducing intermediate domains and self-training strategies, but often face the challenges of inefficient knowledge migration or missing data in intermediate domains. In this paper, we design an optimisation framework based on the hyperparameter $\lambda$ by dynamically balancing the loss weights of the source and target domains, which enables the model to progressively adjust the strength of knowledge migration ($\lambda$ incrementing from 0 to 1) during the training process, thus achieving cross-domain generalisation more efficiently. Specifically, the method incorporates self-training to generate pseudo-labels and iteratively updates the model by minimising a weighted loss function to ensure stability and robustness during progressive adaptation in the intermediate domain. The experimental part validates the effectiveness of the method on rotated MNIST, colour-shifted MNIST, portrait dataset and forest cover type dataset, and the results show that it outperforms existing baseline methods. The paper further analyses the impact of the dynamic tuning strategy of the hyperparameter $\lambda$ on the performance through ablation experiments, confirming the advantages of progressive domain penetration in mitigating the domain bias and enhancing the model generalisation capability. The study provides a theoretical support and practical framework for asymptotic domain adaptation and expands its application potential in dynamic environments.
SWAT: Sliding Window Adversarial Training for Gradual Domain Adaptation
Jan 31, 2025



Domain shifts are critical issues that harm the performance of machine learning. Unsupervised Domain Adaptation (UDA) mitigates this issue but suffers when the domain shifts are steep and drastic. Gradual Domain Adaptation (GDA) alleviates this problem in a mild way by gradually adapting from the source to the target domain using multiple intermediate domains. In this paper, we propose Sliding Window Adversarial Training (SWAT) for Gradual Domain Adaptation. SWAT uses the construction of adversarial streams to connect the feature spaces of the source and target domains. In order to gradually narrow the small gap between adjacent intermediate domains, a sliding window paradigm is designed that moves along the adversarial stream. When the window moves to the end of the stream, i.e., the target domain, the domain shift is drastically reduced. Extensive experiments are conducted on public GDA benchmarks, and the results demonstrate that the proposed SWAT significantly outperforms the state-of-the-art approaches. The implementation is available at: https://anonymous.4open.science/r/SWAT-8677.
CausalVE: Face Video Privacy Encryption via Causal Video Prediction
Sep 28, 2024



Advanced facial recognition technologies and recommender systems with inadequate privacy technologies and policies for facial interactions increase concerns about bioprivacy violations. With the proliferation of video and live-streaming websites, public-face video distribution and interactions pose greater privacy risks. Existing techniques typically address the risk of sensitive biometric information leakage through various privacy enhancement methods but pose a higher security risk by corrupting the information to be conveyed by the interaction data, or by leaving certain biometric features intact that allow an attacker to infer sensitive biometric information from them. To address these shortcomings, in this paper, we propose a neural network framework, CausalVE. We obtain cover images by adopting a diffusion model to achieve face swapping with face guidance and use the speech sequence features and spatiotemporal sequence features of the secret video for dynamic video inference and prediction to obtain a cover video with the same number of frames as the secret video. In addition, we hide the secret video by using reversible neural networks for video hiding so that the video can also disseminate secret data. Numerous experiments prove that our CausalVE has good security in public video dissemination and outperforms state-of-the-art methods from a qualitative, quantitative, and visual point of view.
LHQ-SVC: Lightweight and High Quality Singing Voice Conversion Modeling
Sep 13, 2024


Singing Voice Conversion (SVC) has emerged as a significant subfield of Voice Conversion (VC), enabling the transformation of one singer's voice into another while preserving musical elements such as melody, rhythm, and timbre. Traditional SVC methods have limitations in terms of audio quality, data requirements, and computational complexity. In this paper, we propose LHQ-SVC, a lightweight, CPU-compatible model based on the SVC framework and diffusion model, designed to reduce model size and computational demand without sacrificing performance. We incorporate features to improve inference quality, and optimize for CPU execution by using performance tuning tools and parallel computing frameworks. Our experiments demonstrate that LHQ-SVC maintains competitive performance, with significant improvements in processing speed and efficiency across different devices. The results suggest that LHQ-SVC can meet
Generative Iris Prior Embedded Transformer for Iris Restoration
Jun 28, 2024



Iris restoration from complexly degraded iris images, aiming to improve iris recognition performance, is a challenging problem. Due to the complex degradation, directly training a convolutional neural network (CNN) without prior cannot yield satisfactory results. In this work, we propose a generative iris prior embedded Transformer model (Gformer), in which we build a hierarchical encoder-decoder network employing Transformer block and generative iris prior. First, we tame Transformer blocks to model long-range dependencies in target images. Second, we pretrain an iris generative adversarial network (GAN) to obtain the rich iris prior, and incorporate it into the iris restoration process with our iris feature modulator. Our experiments demonstrate that the proposed Gformer outperforms state-of-the-art methods. Besides, iris recognition performance has been significantly improved after applying Gformer.
* Our code is available at https://github.com/sawyercharlton/Gformer
Improved Genetic Algorithm Based on Greedy and Simulated Annealing Ideas for Vascular Robot Ordering Strategy
Mar 28, 2024This study presents a comprehensive approach for optimizing the acquisition, utilization, and maintenance of ABLVR vascular robots in healthcare settings. Medical robotics, particularly in vascular treatments, necessitates precise resource allocation and optimization due to the complex nature of robot and operator maintenance. Traditional heuristic methods, though intuitive, often fail to achieve global optimization. To address these challenges, this research introduces a novel strategy, combining mathematical modeling, a hybrid genetic algorithm, and ARIMA time series forecasting. Considering the dynamic healthcare environment, our approach includes a robust resource allocation model for robotic vessels and operators. We incorporate the unique requirements of the adaptive learning process for operators and the maintenance needs of robotic components. The hybrid genetic algorithm, integrating simulated annealing and greedy approaches, efficiently solves the optimization problem. Additionally, ARIMA time series forecasting predicts the demand for vascular robots, further enhancing the adaptability of our strategy. Experimental results demonstrate the superiority of our approach in terms of optimization, transparency, and convergence speed from other state-of-the-art methods.
A Challenger to GPT-4V? Early Explorations of Gemini in Visual Expertise
Dec 20, 2023


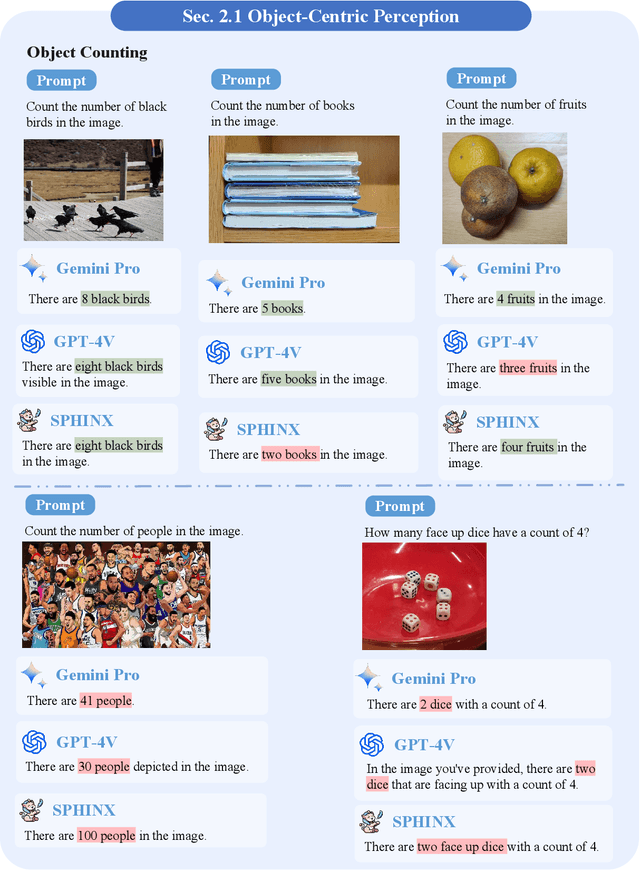
The surge of interest towards Multi-modal Large Language Models (MLLMs), e.g., GPT-4V(ision) from OpenAI, has marked a significant trend in both academia and industry. They endow Large Language Models (LLMs) with powerful capabilities in visual understanding, enabling them to tackle diverse multi-modal tasks. Very recently, Google released Gemini, its newest and most capable MLLM built from the ground up for multi-modality. In light of the superior reasoning capabilities, can Gemini challenge GPT-4V's leading position in multi-modal learning? In this paper, we present a preliminary exploration of Gemini Pro's visual understanding proficiency, which comprehensively covers four domains: fundamental perception, advanced cognition, challenging vision tasks, and various expert capacities. We compare Gemini Pro with the state-of-the-art GPT-4V to evaluate its upper limits, along with the latest open-sourced MLLM, Sphinx, which reveals the gap between manual efforts and black-box systems. The qualitative samples indicate that, while GPT-4V and Gemini showcase different answering styles and preferences, they can exhibit comparable visual reasoning capabilities, and Sphinx still trails behind them concerning domain generalizability. Specifically, GPT-4V tends to elaborate detailed explanations and intermediate steps, and Gemini prefers to output a direct and concise answer. The quantitative evaluation on the popular MME benchmark also demonstrates the potential of Gemini to be a strong challenger to GPT-4V. Our early investigation of Gemini also observes some common issues of MLLMs, indicating that there still remains a considerable distance towards artificial general intelligence. Our project for tracking the progress of MLLM is released at https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models.
Soft policy optimization using dual-track advantage estimator
Sep 15, 2020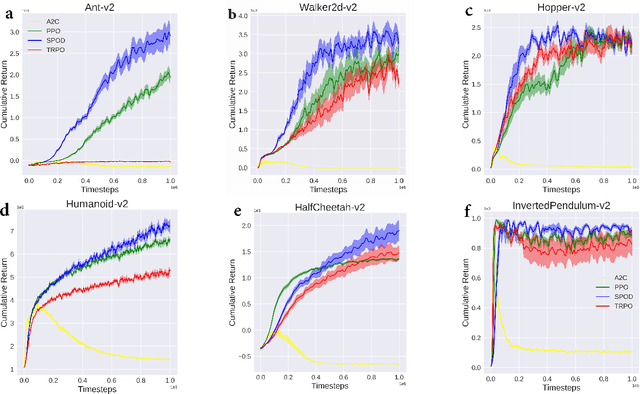
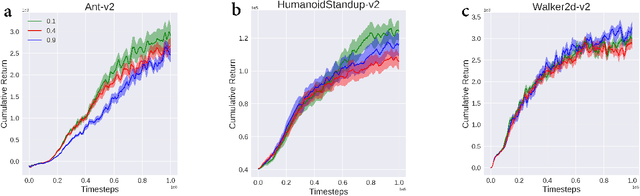
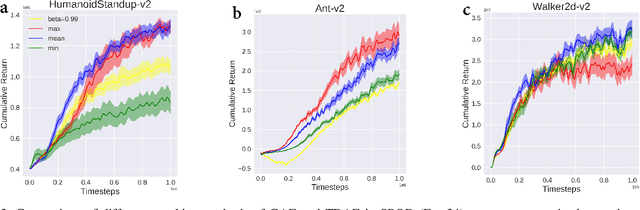
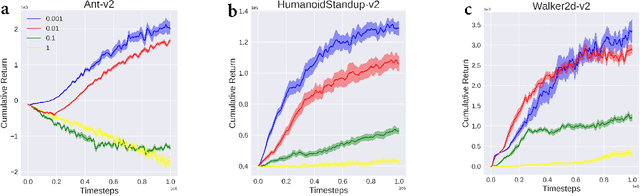
In reinforcement learning (RL), we always expect the agent to explore as many states as possible in the initial stage of training and exploit the explored information in the subsequent stage to discover the most returnable trajectory. Based on this principle, in this paper, we soften the proximal policy optimization by introducing the entropy and dynamically setting the temperature coefficient to balance the opportunity of exploration and exploitation. While maximizing the expected reward, the agent will also seek other trajectories to avoid the local optimal policy. Nevertheless, the increase of randomness induced by entropy will reduce the train speed in the early stage. Integrating the temporal-difference (TD) method and the general advantage estimator (GAE), we propose the dual-track advantage estimator (DTAE) to accelerate the convergence of value functions and further enhance the performance of the algorithm. Compared with other on-policy RL algorithms on the Mujoco environment, the proposed method not only significantly speeds up the training but also achieves the most advanced results in cumulative return.