 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDropout Prompt Learning: Towards Robust and Adaptive Vision-Language Models
Dec 08, 2025Dropout is a widely used regularization technique which improves the generalization ability of a model by randomly dropping neurons. In light of this, we propose Dropout Prompt Learning, which aims for applying dropout to improve the robustness of the vision-language models. Different from the vanilla dropout, we apply dropout on the tokens of the textual and visual branches, where we evaluate the token significance considering both intra-modal context and inter-modal alignment, enabling flexible dropout probabilities for each token. Moreover, to maintain semantic alignment for general knowledge transfer while encouraging the diverse representations that dropout introduces, we further propose residual entropy regularization. Experiments on 15 benchmarks show our method's effectiveness in challenging scenarios like low-shot learning, long-tail classification, and out-of-distribution generalization. Notably, our method surpasses regularization-based methods including KgCoOp by 5.10% and PromptSRC by 2.13% in performance on base-to-novel generalization.
Synergy Between the Strong and the Weak: Spiking Neural Networks are Inherently Self-Distillers
Oct 09, 2025



Brain-inspired spiking neural networks (SNNs) promise to be a low-power alternative to computationally intensive artificial neural networks (ANNs), although performance gaps persist. Recent studies have improved the performance of SNNs through knowledge distillation, but rely on large teacher models or introduce additional training overhead. In this paper, we show that SNNs can be naturally deconstructed into multiple submodels for efficient self-distillation. We treat each timestep instance of the SNN as a submodel and evaluate its output confidence, thus efficiently identifying the strong and the weak. Based on this strong and weak relationship, we propose two efficient self-distillation schemes: (1) \textbf{Strong2Weak}: During training, the stronger "teacher" guides the weaker "student", effectively improving overall performance. (2) \textbf{Weak2Strong}: The weak serve as the "teacher", distilling the strong in reverse with underlying dark knowledge, again yielding significant performance gains. For both distillation schemes, we offer flexible implementations such as ensemble, simultaneous, and cascade distillation. Experiments show that our method effectively improves the discriminability and overall performance of the SNN, while its adversarial robustness is also enhanced, benefiting from the stability brought by self-distillation. This ingeniously exploits the temporal properties of SNNs and provides insight into how to efficiently train high-performance SNNs.
PA-HOI: A Physics-Aware Human and Object Interaction Dataset
Aug 08, 2025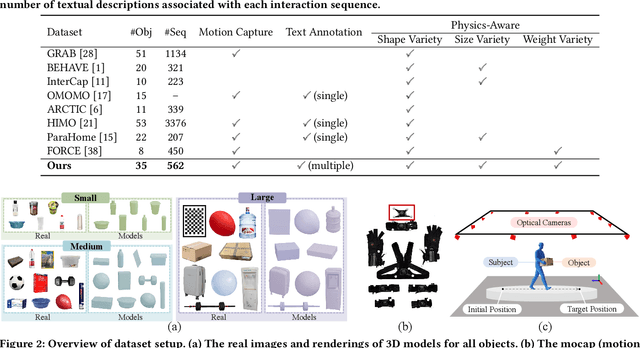
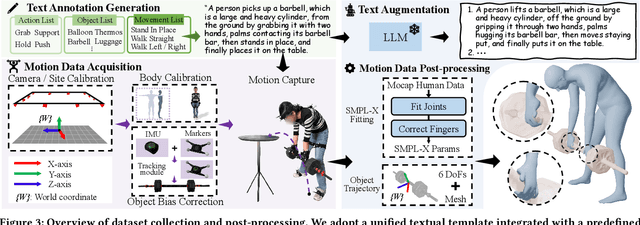
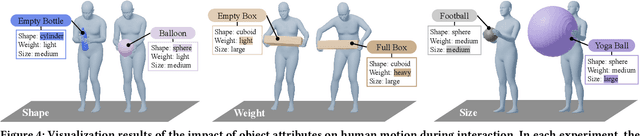
The Human-Object Interaction (HOI) task explores the dynamic interactions between humans and objects in physical environments, providing essential biomechanical and cognitive-behavioral foundations for fields such as robotics, virtual reality, and human-computer interaction. However, existing HOI data sets focus on details of affordance, often neglecting the influence of physical properties of objects on human long-term motion. To bridge this gap, we introduce the PA-HOI Motion Capture dataset, which highlights the impact of objects' physical attributes on human motion dynamics, including human posture, moving velocity, and other motion characteristics. The dataset comprises 562 motion sequences of human-object interactions, with each sequence performed by subjects of different genders interacting with 35 3D objects that vary in size, shape, and weight. This dataset stands out by significantly extending the scope of existing ones for understanding how the physical attributes of different objects influence human posture, speed, motion scale, and interacting strategies. We further demonstrate the applicability of the PA-HOI dataset by integrating it with existing motion generation methods, validating its capacity to transfer realistic physical awareness.
A Semantic-Enhanced Heterogeneous Graph Learning Method for Flexible Objects Recognition
Mar 28, 2025Flexible objects recognition remains a significant challenge due to its inherently diverse shapes and sizes, translucent attributes, and subtle inter-class differences. Graph-based models, such as graph convolution networks and graph vision models, are promising in flexible objects recognition due to their ability of capturing variable relations within the flexible objects. These methods, however, often focus on global visual relationships or fail to align semantic and visual information. To alleviate these limitations, we propose a semantic-enhanced heterogeneous graph learning method. First, an adaptive scanning module is employed to extract discriminative semantic context, facilitating the matching of flexible objects with varying shapes and sizes while aligning semantic and visual nodes to enhance cross-modal feature correlation. Second, a heterogeneous graph generation module aggregates global visual and local semantic node features, improving the recognition of flexible objects. Additionally, We introduce the FSCW, a large-scale flexible dataset curated from existing sources. We validate our method through extensive experiments on flexible datasets (FDA and FSCW), and challenge benchmarks (CIFAR-100 and ImageNet-Hard), demonstrating competitive performance.
Rethinking Spiking Neural Networks from an Ensemble Learning Perspective
Feb 20, 2025Spiking neural networks (SNNs) exhibit superior energy efficiency but suffer from limited performance. In this paper, we consider SNNs as ensembles of temporal subnetworks that share architectures and weights, and highlight a crucial issue that affects their performance: excessive differences in initial states (neuronal membrane potentials) across timesteps lead to unstable subnetwork outputs, resulting in degraded performance. To mitigate this, we promote the consistency of the initial membrane potential distribution and output through membrane potential smoothing and temporally adjacent subnetwork guidance, respectively, to improve overall stability and performance. Moreover, membrane potential smoothing facilitates forward propagation of information and backward propagation of gradients, mitigating the notorious temporal gradient vanishing problem. Our method requires only minimal modification of the spiking neurons without adapting the network structure, making our method generalizable and showing consistent performance gains in 1D speech, 2D object, and 3D point cloud recognition tasks. In particular, on the challenging CIFAR10-DVS dataset, we achieved 83.20\% accuracy with only four timesteps. This provides valuable insights into unleashing the potential of SNNs.
SWAT: Sliding Window Adversarial Training for Gradual Domain Adaptation
Jan 31, 2025



Domain shifts are critical issues that harm the performance of machine learning. Unsupervised Domain Adaptation (UDA) mitigates this issue but suffers when the domain shifts are steep and drastic. Gradual Domain Adaptation (GDA) alleviates this problem in a mild way by gradually adapting from the source to the target domain using multiple intermediate domains. In this paper, we propose Sliding Window Adversarial Training (SWAT) for Gradual Domain Adaptation. SWAT uses the construction of adversarial streams to connect the feature spaces of the source and target domains. In order to gradually narrow the small gap between adjacent intermediate domains, a sliding window paradigm is designed that moves along the adversarial stream. When the window moves to the end of the stream, i.e., the target domain, the domain shift is drastically reduced. Extensive experiments are conducted on public GDA benchmarks, and the results demonstrate that the proposed SWAT significantly outperforms the state-of-the-art approaches. The implementation is available at: https://anonymous.4open.science/r/SWAT-8677.
Toward End-to-End Bearing Fault Diagnosis for Industrial Scenarios with Spiking Neural Networks
Aug 17, 2024Spiking neural networks (SNNs) transmit information via low-power binary spikes and have received widespread attention in areas such as computer vision and reinforcement learning. However, there have been very few explorations of SNNs in more practical industrial scenarios. In this paper, we focus on the application of SNNs in bearing fault diagnosis to facilitate the integration of high-performance AI algorithms and real-world industries. In particular, we identify two key limitations of existing SNN fault diagnosis methods: inadequate encoding capacity that necessitates cumbersome data preprocessing, and non-spike-oriented architectures that constrain the performance of SNNs. To alleviate these problems, we propose a Multi-scale Residual Attention SNN (MRA-SNN) to simultaneously improve the efficiency, performance, and robustness of SNN methods. By incorporating a lightweight attention mechanism, we have designed a multi-scale attention encoding module to extract multiscale fault features from vibration signals and encode them as spatio-temporal spikes, eliminating the need for complicated preprocessing. Then, the spike residual attention block extracts high-dimensional fault features and enhances the expressiveness of sparse spikes with the attention mechanism for end-to-end diagnosis. In addition, the performance and robustness of MRA-SNN is further enhanced by introducing the lightweight attention mechanism within the spiking neurons to simulate the biological dendritic filtering effect. Extensive experiments on MFPT and JNU benchmark datasets demonstrate that MRA-SNN significantly outperforms existing methods in terms of accuracy, energy consumption and noise robustness, and is more feasible for deployment in real-world industrial scenarios.
Temporal Reversed Training for Spiking Neural Networks with Generalized Spatio-Temporal Representation
Aug 17, 2024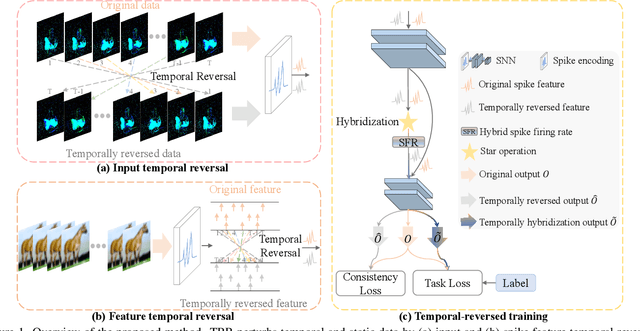
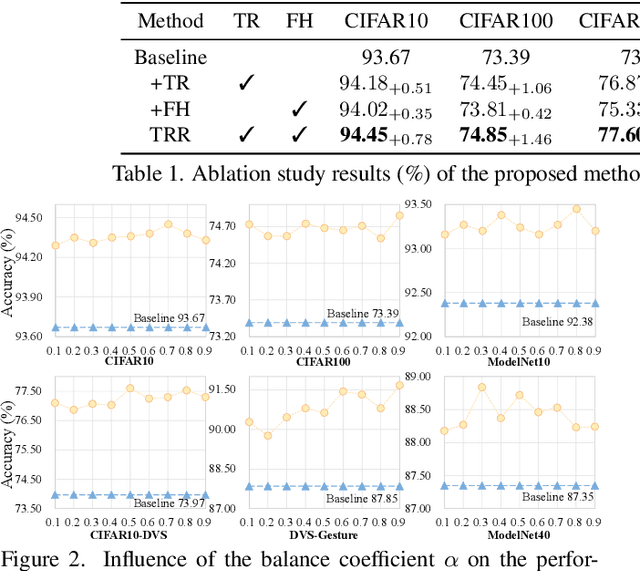

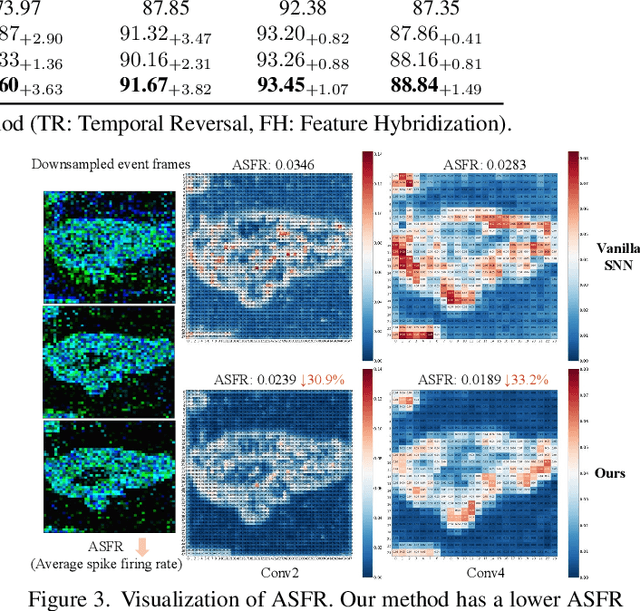
Spiking neural networks (SNNs) have received widespread attention as an ultra-low energy computing paradigm. Recent studies have focused on improving the feature extraction capability of SNNs, but they suffer from inefficient inference and suboptimal performance. In this paper, we propose a simple yet effective temporal reversed training (TRT) method to optimize the spatio-temporal performance of SNNs and circumvent these problems. We perturb the input temporal data by temporal reversal, prompting the SNN to produce original-reversed consistent output logits and to learn perturbation-invariant representations. For static data without temporal dimension, we generalize this strategy by exploiting the inherent temporal property of spiking neurons for spike feature temporal reversal. In addition, we utilize the lightweight ``star operation" (element-wise multiplication) to hybridize the original and temporally reversed spike firing rates and expand the implicit dimensions, which serves as spatio-temporal regularization to further enhance the generalization of the SNN. Our method involves only an additional temporal reversal operation and element-wise multiplication during training, thus incurring negligible training overhead and not affecting the inference efficiency at all. Extensive experiments on static/neuromorphic object/action recognition, and 3D point cloud classification tasks demonstrate the effectiveness and generalizability of our method. In particular, with only two timesteps, our method achieves 74.77\% and 90.57\% accuracy on ImageNet and ModelNet40, respectively.
Multi-Bit Mechanism: A Novel Information Transmission Paradigm for Spiking Neural Networks
Jul 08, 2024Since proposed, spiking neural networks (SNNs) gain recognition for their high performance, low power consumption and enhanced biological interpretability. However, while bringing these advantages, the binary nature of spikes also leads to considerable information loss in SNNs, ultimately causing performance degradation. We claim that the limited expressiveness of current binary spikes, resulting in substantial information loss, is the fundamental issue behind these challenges. To alleviate this, our research introduces a multi-bit information transmission mechanism for SNNs. This mechanism expands the output of spiking neurons from the original single bit to multiple bits, enhancing the expressiveness of the spikes and reducing information loss during the forward process, while still maintaining the low energy consumption advantage of SNNs. For SNNs, this represents a new paradigm of information transmission. Moreover, to further utilize the limited spikes, we extract effective signals from the previous layer to re-stimulate the neurons, thus encouraging full spikes emission across various bit levels. We conducted extensive experiments with our proposed method using both direct training method and ANN-SNN conversion method, and the results show consistent performance improvements.
Self-Distillation Learning Based on Temporal-Spatial Consistency for Spiking Neural Networks
Jun 12, 2024Spiking neural networks (SNNs) have attracted considerable attention for their event-driven, low-power characteristics and high biological interpretability. Inspired by knowledge distillation (KD), recent research has improved the performance of the SNN model with a pre-trained teacher model. However, additional teacher models require significant computational resources, and it is tedious to manually define the appropriate teacher network architecture. In this paper, we explore cost-effective self-distillation learning of SNNs to circumvent these concerns. Without an explicit defined teacher, the SNN generates pseudo-labels and learns consistency during training. On the one hand, we extend the timestep of the SNN during training to create an implicit temporal ``teacher" that guides the learning of the original ``student", i.e., the temporal self-distillation. On the other hand, we guide the output of the weak classifier at the intermediate stage by the final output of the SNN, i.e., the spatial self-distillation. Our temporal-spatial self-distillation (TSSD) learning method does not introduce any inference overhead and has excellent generalization ability. Extensive experiments on the static image datasets CIFAR10/100 and ImageNet as well as the neuromorphic datasets CIFAR10-DVS and DVS-Gesture validate the superior performance of the TSSD method. This paper presents a novel manner of fusing SNNs with KD, providing insights into high-performance SNN learning methods.