 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausalVAD: De-confounding End-to-End Autonomous Driving via Causal Intervention
Mar 19, 2026Planning-oriented end-to-end driving models show great promise, yet they fundamentally learn statistical correlations instead of true causal relationships. This vulnerability leads to causal confusion, where models exploit dataset biases as shortcuts, critically harming their reliability and safety in complex scenarios. To address this, we introduce CausalVAD, a de-confounding training framework that leverages causal intervention. At its core, we design the sparse causal intervention scheme (SCIS), a lightweight, plug-and-play module to instantiate the backdoor adjustment theory in neural networks. SCIS constructs a dictionary of prototypes representing latent driving contexts. It then uses this dictionary to intervene on the model's sparse vectorized queries. This step actively eliminates spurious associations induced by confounders, thereby eliminating spurious factors from the representations for downstream tasks. Extensive experiments on benchmarks like nuScenes show CausalVAD achieves state-of-the-art planning accuracy and safety. Furthermore, our method demonstrates superior robustness against both data bias and noisy scenarios configured to induce causal confusion.
Robust Finetuning of Vision-Language-Action Robot Policies via Parameter Merging
Dec 18, 2025Generalist robot policies, trained on large and diverse datasets, have demonstrated the ability to generalize across a wide spectrum of behaviors, enabling a single policy to act in varied real-world environments. However, they still fall short on new tasks not covered in the training data. When finetuned on limited demonstrations of a new task, these policies often overfit to the specific demonstrations--not only losing their prior abilities to solve a wide variety of generalist tasks but also failing to generalize within the new task itself. In this work, we aim to develop a method that preserves the generalization capabilities of the generalist policy during finetuning, allowing a single policy to robustly incorporate a new skill into its repertoire. Our goal is a single policy that both learns to generalize to variations of the new task and retains the broad competencies gained from pretraining. We show that this can be achieved through a simple yet effective strategy: interpolating the weights of a finetuned model with that of the pretrained model. We show, across extensive simulated and real-world experiments, that such model merging produces a single model that inherits the generalist abilities of the base model and learns to solve the new task robustly, outperforming both the pretrained and finetuned model on out-of-distribution variations of the new task. Moreover, we show that model merging performance scales with the amount of pretraining data, and enables continual acquisition of new skills in a lifelong learning setting, without sacrificing previously learned generalist abilities.
$π^{*}_{0.6}$: a VLA That Learns From Experience
Nov 19, 2025We study how vision-language-action (VLA) models can improve through real-world deployments via reinforcement learning (RL). We present a general-purpose method, RL with Experience and Corrections via Advantage-conditioned Policies (RECAP), that provides for RL training of VLAs via advantage conditioning. Our method incorporates heterogeneous data into the self-improvement process, including demonstrations, data from on-policy collection, and expert teleoperated interventions provided during autonomous execution. RECAP starts by pre-training a generalist VLA with offline RL, which we call $π^{*}_{0.6}$, that can then be specialized to attain high performance on downstream tasks through on-robot data collection. We show that the $π^{*}_{0.6}$ model trained with the full RECAP method can fold laundry in real homes, reliably assemble boxes, and make espresso drinks using a professional espresso machine. On some of the hardest tasks, RECAP more than doubles task throughput and roughly halves the task failure rate.
Compute-Optimal Scaling for Value-Based Deep RL
Aug 20, 2025As models grow larger and training them becomes expensive, it becomes increasingly important to scale training recipes not just to larger models and more data, but to do so in a compute-optimal manner that extracts maximal performance per unit of compute. While such scaling has been well studied for language modeling, reinforcement learning (RL) has received less attention in this regard. In this paper, we investigate compute scaling for online, value-based deep RL. These methods present two primary axes for compute allocation: model capacity and the update-to-data (UTD) ratio. Given a fixed compute budget, we ask: how should resources be partitioned across these axes to maximize sample efficiency? Our analysis reveals a nuanced interplay between model size, batch size, and UTD. In particular, we identify a phenomenon we call TD-overfitting: increasing the batch quickly harms Q-function accuracy for small models, but this effect is absent in large models, enabling effective use of large batch size at scale. We provide a mental model for understanding this phenomenon and build guidelines for choosing batch size and UTD to optimize compute usage. Our findings provide a grounded starting point for compute-optimal scaling in deep RL, mirroring studies in supervised learning but adapted to TD learning.
Reinforcement Learning with Action Chunking
Jul 10, 2025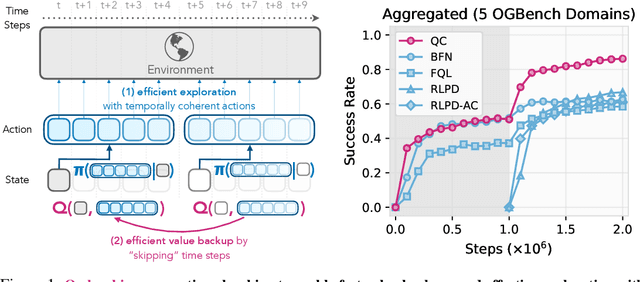
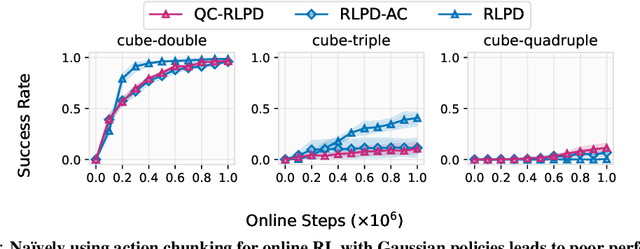

We present Q-chunking, a simple yet effective recipe for improving reinforcement learning (RL) algorithms for long-horizon, sparse-reward tasks. Our recipe is designed for the offline-to-online RL setting, where the goal is to leverage an offline prior dataset to maximize the sample-efficiency of online learning. Effective exploration and sample-efficient learning remain central challenges in this setting, as it is not obvious how the offline data should be utilized to acquire a good exploratory policy. Our key insight is that action chunking, a technique popularized in imitation learning where sequences of future actions are predicted rather than a single action at each timestep, can be applied to temporal difference (TD)-based RL methods to mitigate the exploration challenge. Q-chunking adopts action chunking by directly running RL in a 'chunked' action space, enabling the agent to (1) leverage temporally consistent behaviors from offline data for more effective online exploration and (2) use unbiased $n$-step backups for more stable and efficient TD learning. Our experimental results demonstrate that Q-chunking exhibits strong offline performance and online sample efficiency, outperforming prior best offline-to-online methods on a range of long-horizon, sparse-reward manipulation tasks.
REACT: Runtime-Enabled Active Collision-avoidance Technique for Autonomous Driving
May 16, 2025Achieving rapid and effective active collision avoidance in dynamic interactive traffic remains a core challenge for autonomous driving. This paper proposes REACT (Runtime-Enabled Active Collision-avoidance Technique), a closed-loop framework that integrates risk assessment with active avoidance control. By leveraging energy transfer principles and human-vehicle-road interaction modeling, REACT dynamically quantifies runtime risk and constructs a continuous spatial risk field. The system incorporates physically grounded safety constraints such as directional risk and traffic rules to identify high-risk zones and generate feasible, interpretable avoidance behaviors. A hierarchical warning trigger strategy and lightweight system design enhance runtime efficiency while ensuring real-time responsiveness. Evaluations across four representative high-risk scenarios including car-following braking, cut-in, rear-approaching, and intersection conflict demonstrate REACT's capability to accurately identify critical risks and execute proactive avoidance. Its risk estimation aligns closely with human driver cognition (i.e., warning lead time < 0.4 s), achieving 100% safe avoidance with zero false alarms or missed detections. Furthermore, it exhibits superior real-time performance (< 50 ms latency), strong foresight, and generalization. The lightweight architecture achieves state-of-the-art accuracy, highlighting its potential for real-time deployment in safety-critical autonomous systems.
On Path to Multimodal Generalist: General-Level and General-Bench
May 07, 2025The Multimodal Large Language Model (MLLM) is currently experiencing rapid growth, driven by the advanced capabilities of LLMs. Unlike earlier specialists, existing MLLMs are evolving towards a Multimodal Generalist paradigm. Initially limited to understanding multiple modalities, these models have advanced to not only comprehend but also generate across modalities. Their capabilities have expanded from coarse-grained to fine-grained multimodal understanding and from supporting limited modalities to arbitrary ones. While many benchmarks exist to assess MLLMs, a critical question arises: Can we simply assume that higher performance across tasks indicates a stronger MLLM capability, bringing us closer to human-level AI? We argue that the answer is not as straightforward as it seems. This project introduces General-Level, an evaluation framework that defines 5-scale levels of MLLM performance and generality, offering a methodology to compare MLLMs and gauge the progress of existing systems towards more robust multimodal generalists and, ultimately, towards AGI. At the core of the framework is the concept of Synergy, which measures whether models maintain consistent capabilities across comprehension and generation, and across multiple modalities. To support this evaluation, we present General-Bench, which encompasses a broader spectrum of skills, modalities, formats, and capabilities, including over 700 tasks and 325,800 instances. The evaluation results that involve over 100 existing state-of-the-art MLLMs uncover the capability rankings of generalists, highlighting the challenges in reaching genuine AI. We expect this project to pave the way for future research on next-generation multimodal foundation models, providing a robust infrastructure to accelerate the realization of AGI. Project page: https://generalist.top/
AutoEval: Autonomous Evaluation of Generalist Robot Manipulation Policies in the Real World
Mar 31, 2025Scalable and reproducible policy evaluation has been a long-standing challenge in robot learning. Evaluations are critical to assess progress and build better policies, but evaluation in the real world, especially at a scale that would provide statistically reliable results, is costly in terms of human time and hard to obtain. Evaluation of increasingly generalist robot policies requires an increasingly diverse repertoire of evaluation environments, making the evaluation bottleneck even more pronounced. To make real-world evaluation of robotic policies more practical, we propose AutoEval, a system to autonomously evaluate generalist robot policies around the clock with minimal human intervention. Users interact with AutoEval by submitting evaluation jobs to the AutoEval queue, much like how software jobs are submitted with a cluster scheduling system, and AutoEval will schedule the policies for evaluation within a framework supplying automatic success detection and automatic scene resets. We show that AutoEval can nearly fully eliminate human involvement in the evaluation process, permitting around the clock evaluations, and the evaluation results correspond closely to ground truth evaluations conducted by hand. To facilitate the evaluation of generalist policies in the robotics community, we provide public access to multiple AutoEval scenes in the popular BridgeData robot setup with WidowX robot arms. In the future, we hope that AutoEval scenes can be set up across institutions to form a diverse and distributed evaluation network.
SafeDrive: Knowledge- and Data-Driven Risk-Sensitive Decision-Making for Autonomous Vehicles with Large Language Models
Dec 19, 2024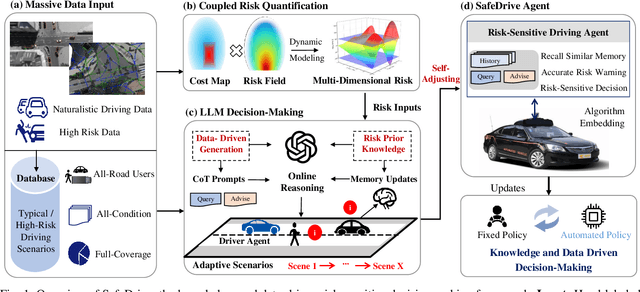
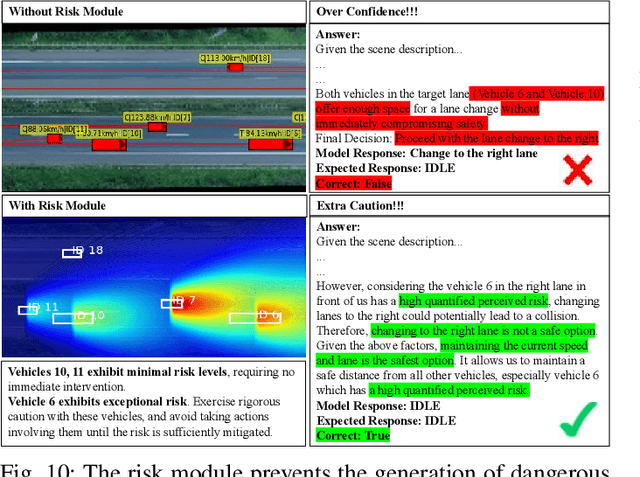
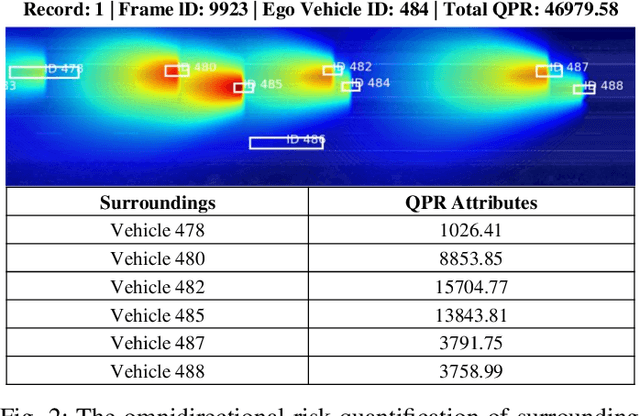
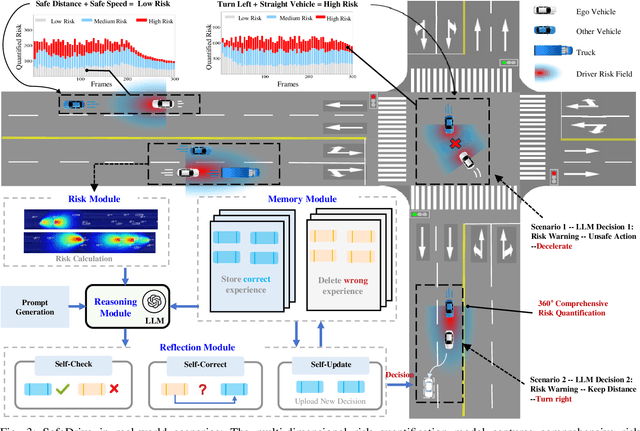
Recent advancements in autonomous vehicles (AVs) use Large Language Models (LLMs) to perform well in normal driving scenarios. However, ensuring safety in dynamic, high-risk environments and managing safety-critical long-tail events remain significant challenges. To address these issues, we propose SafeDrive, a knowledge- and data-driven risk-sensitive decision-making framework to enhance AV safety and adaptability. The proposed framework introduces a modular system comprising: (1) a Risk Module for quantifying multi-factor coupled risks involving driver, vehicle, and road interactions; (2) a Memory Module for storing and retrieving typical scenarios to improve adaptability; (3) a LLM-powered Reasoning Module for context-aware safety decision-making; and (4) a Reflection Module for refining decisions through iterative learning. By integrating knowledge-driven insights with adaptive learning mechanisms, the framework ensures robust decision-making under uncertain conditions. Extensive evaluations on real-world traffic datasets, including highways (HighD), intersections (InD), and roundabouts (RounD), validate the framework's ability to enhance decision-making safety (achieving a 100% safety rate), replicate human-like driving behaviors (with decision alignment exceeding 85%), and adapt effectively to unpredictable scenarios. SafeDrive establishes a novel paradigm for integrating knowledge- and data-driven methods, highlighting significant potential to improve safety and adaptability of autonomous driving in high-risk traffic scenarios. Project Page: https://mezzi33.github.io/SafeDrive/
Efficient Online Reinforcement Learning Fine-Tuning Need Not Retain Offline Data
Dec 10, 2024



The modern paradigm in machine learning involves pre-training on diverse data, followed by task-specific fine-tuning. In reinforcement learning (RL), this translates to learning via offline RL on a diverse historical dataset, followed by rapid online RL fine-tuning using interaction data. Most RL fine-tuning methods require continued training on offline data for stability and performance. However, this is undesirable because training on diverse offline data is slow and expensive for large datasets, and in principle, also limit the performance improvement possible because of constraints or pessimism on offline data. In this paper, we show that retaining offline data is unnecessary as long as we use a properly-designed online RL approach for fine-tuning offline RL initializations. To build this approach, we start by analyzing the role of retaining offline data in online fine-tuning. We find that continued training on offline data is mostly useful for preventing a sudden divergence in the value function at the onset of fine-tuning, caused by a distribution mismatch between the offline data and online rollouts. This divergence typically results in unlearning and forgetting the benefits of offline pre-training. Our approach, Warm-start RL (WSRL), mitigates the catastrophic forgetting of pre-trained initializations using a very simple idea. WSRL employs a warmup phase that seeds the online RL run with a very small number of rollouts from the pre-trained policy to do fast online RL. The data collected during warmup helps ``recalibrate'' the offline Q-function to the online distribution, allowing us to completely discard offline data without destabilizing the online RL fine-tuning. We show that WSRL is able to fine-tune without retaining any offline data, and is able to learn faster and attains higher performance than existing algorithms irrespective of whether they retain offline data or not.