 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCTS: A Multi-Reference Chinese Text Simplification Dataset
Jun 05, 2023Text simplification aims to make the text easier to understand by applying rewriting transformations. There has been very little research on Chinese text simplification for a long time. The lack of generic evaluation data is an essential reason for this phenomenon. In this paper, we introduce MCTS, a multi-reference Chinese text simplification dataset. We describe the annotation process of the dataset and provide a detailed analysis of it. Furthermore, we evaluate the performance of some unsupervised methods and advanced large language models. We hope to build a basic understanding of Chinese text simplification through the foundational work and provide references for future research. We release our data at https://github.com/blcuicall/mcts.
Class Semantics-based Attention for Action Detection
Sep 06, 2021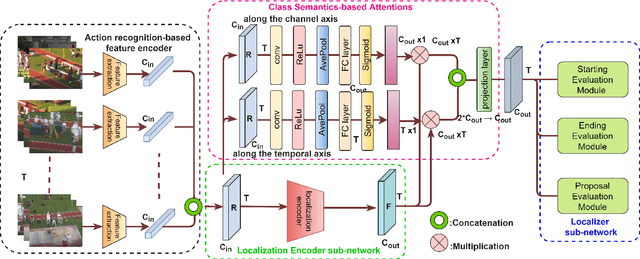
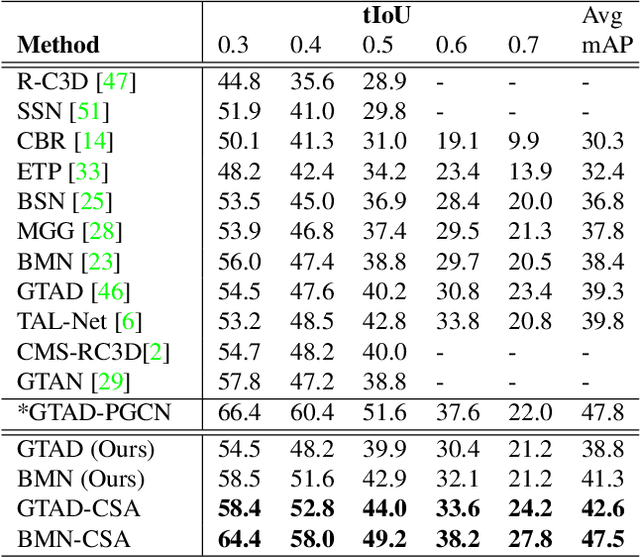
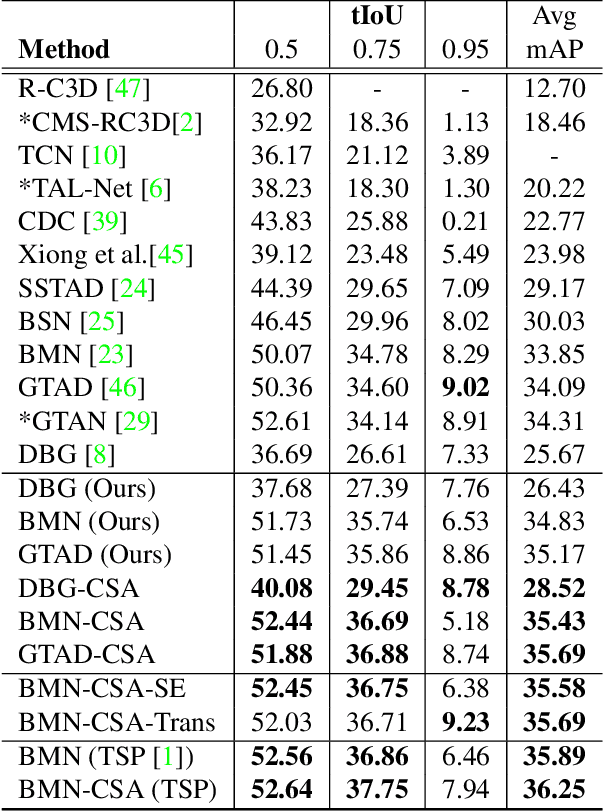
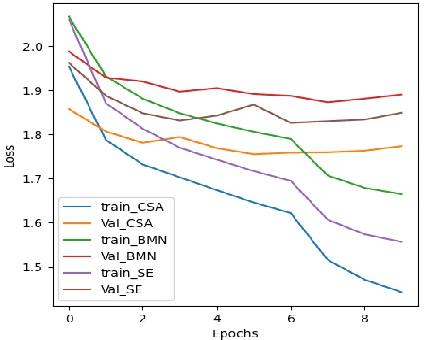
Action localization networks are often structured as a feature encoder sub-network and a localization sub-network, where the feature encoder learns to transform an input video to features that are useful for the localization sub-network to generate reliable action proposals. While some of the encoded features may be more useful for generating action proposals, prior action localization approaches do not include any attention mechanism that enables the localization sub-network to attend more to the more important features. In this paper, we propose a novel attention mechanism, the Class Semantics-based Attention (CSA), that learns from the temporal distribution of semantics of action classes present in an input video to find the importance scores of the encoded features, which are used to provide attention to the more useful encoded features. We demonstrate on two popular action detection datasets that incorporating our novel attention mechanism provides considerable performance gains on competitive action detection models (e.g., around 6.2% improvement over BMN action detection baseline to obtain 47.5% mAP on the THUMOS-14 dataset), and a new state-of-the-art of 36.25% mAP on the ActivityNet v1.3 dataset. Further, the CSA localization model family which includes BMN-CSA, was part of the second-placed submission at the 2021 ActivityNet action localization challenge. Our attention mechanism outperforms prior self-attention modules such as the squeeze-and-excitation in action detection task. We also observe that our attention mechanism is complementary to such self-attention modules in that performance improvements are seen when both are used together.
Gumbel-softmax-based Optimization: A Simple General Framework for Optimization Problems on Graphs
Apr 14, 2020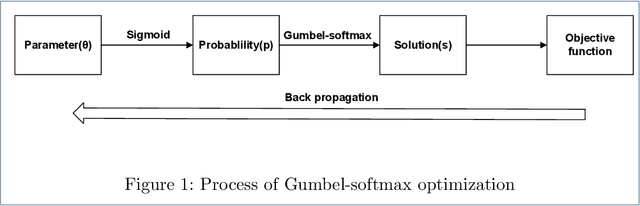


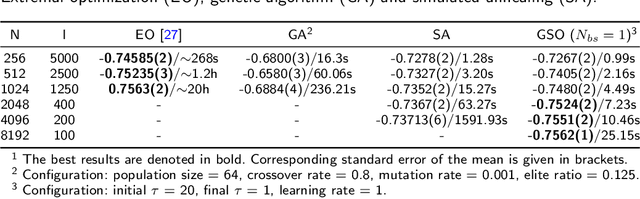
In computer science, there exist a large number of optimization problems defined on graphs, that is to find a best node state configuration or a network structure such that the designed objective function is optimized under some constraints. However, these problems are notorious for their hardness to solve because most of them are NP-hard or NP-complete. Although traditional general methods such as simulated annealing (SA), genetic algorithms (GA) and so forth have been devised to these hard problems, their accuracy and time consumption are not satisfying in practice. In this work, we proposed a simple, fast, and general algorithm framework based on advanced automatic differentiation technique empowered by deep learning frameworks. By introducing Gumbel-softmax technique, we can optimize the objective function directly by gradient descent algorithm regardless of the discrete nature of variables. We also introduce evolution strategy to parallel version of our algorithm. We test our algorithm on three representative optimization problems on graph including modularity optimization from network science, Sherrington-Kirkpatrick (SK) model from statistical physics, maximum independent set (MIS) and minimum vertex cover (MVC) problem from combinatorial optimization on graph. High-quality solutions can be obtained with much less time consuming compared to traditional approaches.