 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCTS: A Multi-Reference Chinese Text Simplification Dataset
Jun 05, 2023Text simplification aims to make the text easier to understand by applying rewriting transformations. There has been very little research on Chinese text simplification for a long time. The lack of generic evaluation data is an essential reason for this phenomenon. In this paper, we introduce MCTS, a multi-reference Chinese text simplification dataset. We describe the annotation process of the dataset and provide a detailed analysis of it. Furthermore, we evaluate the performance of some unsupervised methods and advanced large language models. We hope to build a basic understanding of Chinese text simplification through the foundational work and provide references for future research. We release our data at https://github.com/blcuicall/mcts.
BLCU-ICALL at SemEval-2022 Task 1: Cross-Attention Multitasking Framework for Definition Modeling
Apr 16, 2022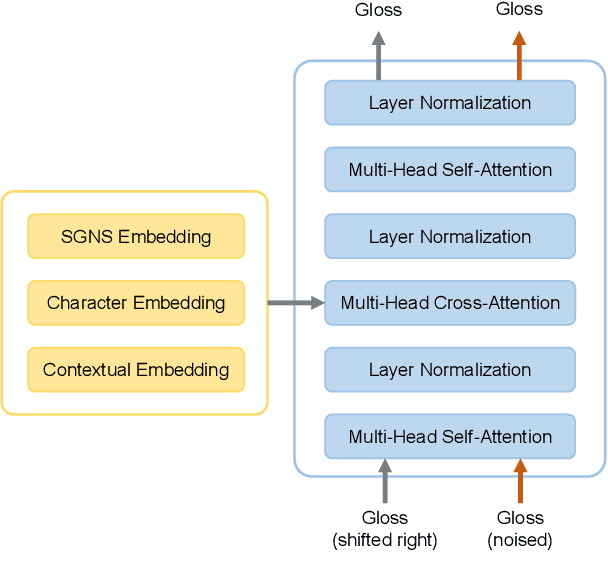
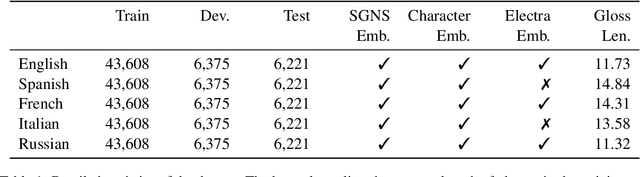
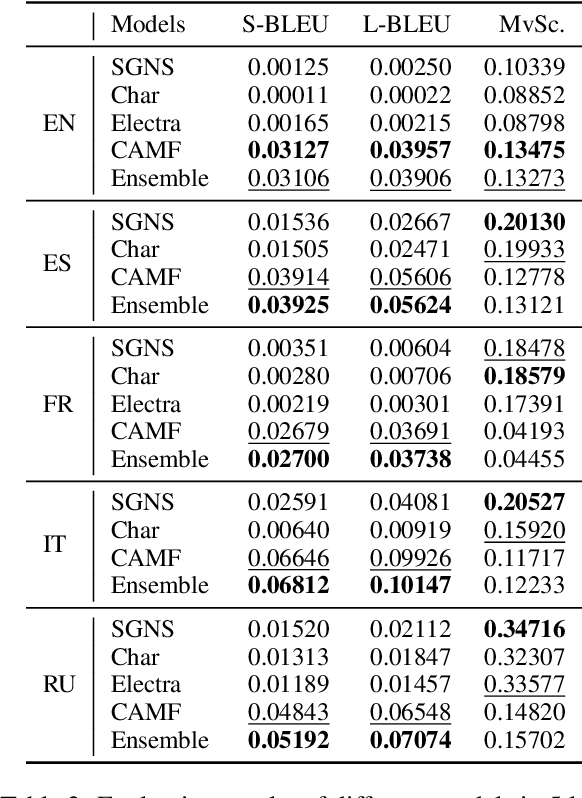
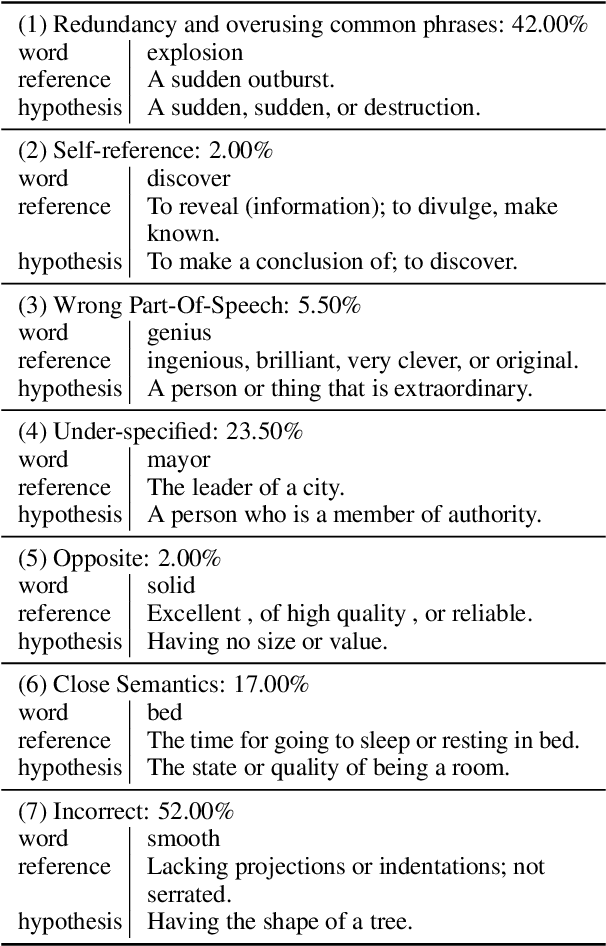
This paper describes the BLCU-ICALL system used in the SemEval-2022 Task 1 Comparing Dictionaries and Word Embeddings, the Definition Modeling subtrack, achieving 1st on Italian, 2nd on Spanish and Russian, and 3rd on English and French. We propose a transformer-based multitasking framework to explore the task. The framework integrates multiple embedding architectures through the cross-attention mechanism, and captures the structure of glosses through a masking language model objective. Additionally, we also investigate a simple but effective model ensembling strategy to further improve the robustness. The evaluation results show the effectiveness of our solution. We release our code at: https://github.com/blcuicall/SemEval2022-Task1-DM.