 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEIC-DT: Memory-Efficient Incremental Clustering for Long-Text Coreference Resolution with Dual-Threshold Constraints
Dec 31, 2025In the era of large language models (LLMs), supervised neural methods remain the state-of-the-art (SOTA) for Coreference Resolution. Yet, their full potential is underexplored, particularly in incremental clustering, which faces the critical challenge of balancing efficiency with performance for long texts. To address the limitation, we propose \textbf{MEIC-DT}, a novel dual-threshold, memory-efficient incremental clustering approach based on a lightweight Transformer. MEIC-DT features a dual-threshold constraint mechanism designed to precisely control the Transformer's input scale within a predefined memory budget. This mechanism incorporates a Statistics-Aware Eviction Strategy (\textbf{SAES}), which utilizes distinct statistical profiles from the training and inference phases for intelligent cache management. Furthermore, we introduce an Internal Regularization Policy (\textbf{IRP}) that strategically condenses clusters by selecting the most representative mentions, thereby preserving semantic integrity. Extensive experiments on common benchmarks demonstrate that MEIC-DT achieves highly competitive coreference performance under stringent memory constraints.
MiniCPM4: Ultra-Efficient LLMs on End Devices
Jun 09, 2025



This paper introduces MiniCPM4, a highly efficient large language model (LLM) designed explicitly for end-side devices. We achieve this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems. Specifically, in terms of model architecture, we propose InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding phases for long-context processing. Regarding training data, we propose UltraClean, an efficient and accurate pre-training data filtering and generation strategy, and UltraChat v2, a comprehensive supervised fine-tuning dataset. These datasets enable satisfactory model performance to be achieved using just 8 trillion training tokens. Regarding training algorithms, we propose ModelTunnel v2 for efficient pre-training strategy search, and improve existing post-training methods by introducing chunk-wise rollout for load-balanced reinforcement learning and data-efficient tenary LLM, BitCPM. Regarding inference systems, we propose CPM.cu that integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding. To meet diverse on-device requirements, MiniCPM4 is available in two versions, with 0.5B and 8B parameters, respectively. Sufficient evaluation results show that MiniCPM4 outperforms open-source models of similar size across multiple benchmarks, highlighting both its efficiency and effectiveness. Notably, MiniCPM4-8B demonstrates significant speed improvements over Qwen3-8B when processing long sequences. Through further adaptation, MiniCPM4 successfully powers diverse applications, including trustworthy survey generation and tool use with model context protocol, clearly showcasing its broad usability.
Exploring the Small World of Word Embeddings: A Comparative Study on Conceptual Spaces from LLMs of Different Scales
Feb 17, 2025A conceptual space represents concepts as nodes and semantic relatedness as edges. Word embeddings, combined with a similarity metric, provide an effective approach to constructing such a space. Typically, embeddings are derived from traditional distributed models or encoder-only pretrained models, whose objectives directly capture the meaning of the current token. In contrast, decoder-only models, including large language models (LLMs), predict the next token, making their embeddings less directly tied to the current token's semantics. Moreover, comparative studies on LLMs of different scales remain underexplored. In this paper, we construct a conceptual space using word embeddings from LLMs of varying scales and comparatively analyze their properties. We establish a network based on a linguistic typology-inspired connectivity hypothesis, examine global statistical properties, and compare LLMs of varying scales. Locally, we analyze conceptual pairs, WordNet relations, and a cross-lingual semantic network for qualitative words. Our results indicate that the constructed space exhibits small-world properties, characterized by a high clustering coefficient and short path lengths. Larger LLMs generate more intricate spaces, with longer paths reflecting richer relational structures and connections. Furthermore, the network serves as an efficient bridge for cross-lingual semantic mapping.
GLTW: Joint Improved Graph Transformer and LLM via Three-Word Language for Knowledge Graph Completion
Feb 17, 2025Knowledge Graph Completion (KGC), which aims to infer missing or incomplete facts, is a crucial task for KGs. However, integrating the vital structural information of KGs into Large Language Models (LLMs) and outputting predictions deterministically remains challenging. To address this, we propose a new method called GLTW, which encodes the structural information of KGs and merges it with LLMs to enhance KGC performance. Specifically, we introduce an improved Graph Transformer (iGT) that effectively encodes subgraphs with both local and global structural information and inherits the characteristics of language model, bypassing training from scratch. Also, we develop a subgraph-based multi-classification training objective, using all entities within KG as classification objects, to boost learning efficiency.Importantly, we combine iGT with an LLM that takes KG language prompts as input.Our extensive experiments on various KG datasets show that GLTW achieves significant performance gains compared to SOTA baselines.
A Top-down Graph-based Tool for Modeling Classical Semantic Maps: A Crosslinguistic Case Study of Supplementary Adverbs
Dec 02, 2024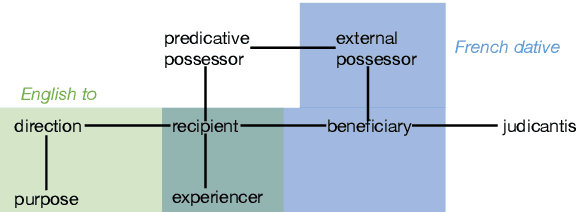

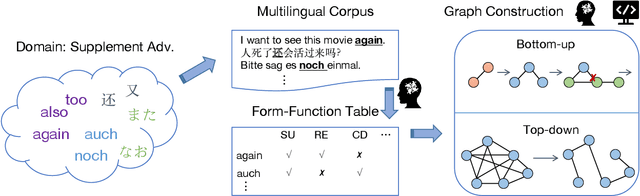

Semantic map models (SMMs) construct a network-like conceptual space from cross-linguistic instances or forms, based on the connectivity hypothesis. This approach has been widely used to represent similarity and entailment relationships in cross-linguistic concept comparisons. However, most SMMs are manually built by human experts using bottom-up procedures, which are often labor-intensive and time-consuming. In this paper, we propose a novel graph-based algorithm that automatically generates conceptual spaces and SMMs in a top-down manner. The algorithm begins by creating a dense graph, which is subsequently pruned into maximum spanning trees, selected according to metrics we propose. These evaluation metrics include both intrinsic and extrinsic measures, considering factors such as network structure and the trade-off between precision and coverage. A case study on cross-linguistic supplementary adverbs demonstrates the effectiveness and efficiency of our model compared to human annotations and other automated methods. The tool is available at \url{https://github.com/RyanLiut/SemanticMapModel}.
Fantastic Semantics and Where to Find Them: Investigating Which Layers of Generative LLMs Reflect Lexical Semantics
Mar 03, 2024Large language models have achieved remarkable success in general language understanding tasks. However, as a family of generative methods with the objective of next token prediction, the semantic evolution with the depth of these models are not fully explored, unlike their predecessors, such as BERT-like architectures. In this paper, we specifically investigate the bottom-up evolution of lexical semantics for a popular LLM, namely Llama2, by probing its hidden states at the end of each layer using a contextualized word identification task. Our experiments show that the representations in lower layers encode lexical semantics, while the higher layers, with weaker semantic induction, are responsible for prediction. This is in contrast to models with discriminative objectives, such as mask language modeling, where the higher layers obtain better lexical semantics. The conclusion is further supported by the monotonic increase in performance via the hidden states for the last meaningless symbols, such as punctuation, in the prompting strategy.
Cross-domain Chinese Sentence Pattern Parsing
Feb 27, 2024Sentence Pattern Structure (SPS) parsing is a syntactic analysis method primarily employed in language teaching.Existing SPS parsers rely heavily on textbook corpora for training, lacking cross-domain capability.To overcome this constraint, this paper proposes an innovative approach leveraging large language models (LLMs) within a self-training framework. Partial syntactic rules from a source domain are combined with target domain sentences to dynamically generate training data, enhancing the adaptability of the parser to diverse domains.Experiments conducted on textbook and news domains demonstrate the effectiveness of the proposed method, outperforming rule-based baselines by 1.68 points on F1 metrics.
OMGEval: An Open Multilingual Generative Evaluation Benchmark for Large Language Models
Feb 21, 2024
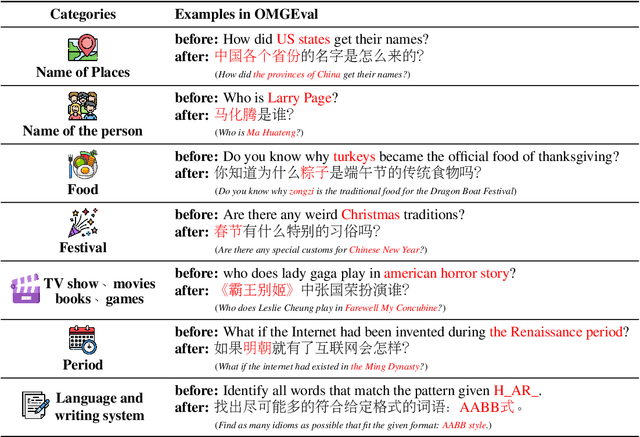

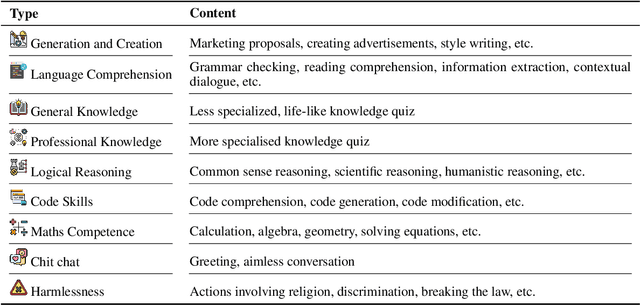
Modern large language models (LLMs) should generally benefit individuals from various cultural backgrounds around the world. However, most recent advanced generative evaluation benchmarks tailed for LLMs mainly focus on English. To this end, we introduce OMGEval, the first Open-source Multilingual Generative test set that can assess the capability of LLMs in different languages. For each language, OMGEval provides 804 open-ended questions, covering a wide range of important capabilities of LLMs, such as general knowledge, logical reasoning, and so on. Each question is rigorously verified by human annotators. Notably, to sufficiently reflect the compatibility of LLMs in different cultural backgrounds, we perform localization for each non-English language. Specifically, the current version of OMGEval includes 5 languages (i.e., Zh, Ru, Fr, Es, Ar). Following AlpacaEval, we employ GPT-4 as the adjudicator to automatically score different model outputs, which is shown closely related to human evaluation. We evaluate several representative multilingual LLMs on the proposed OMGEval, which we believe will provide a valuable reference for the community to further understand and improve the multilingual capability of LLMs. OMGEval is available at https://github.com/blcuicall/OMGEval.
From Text to CQL: Bridging Natural Language and Corpus Search Engine
Feb 21, 2024



Natural Language Processing (NLP) technologies have revolutionized the way we interact with information systems, with a significant focus on converting natural language queries into formal query languages such as SQL. However, less emphasis has been placed on the Corpus Query Language (CQL), a critical tool for linguistic research and detailed analysis within text corpora. The manual construction of CQL queries is a complex and time-intensive task that requires a great deal of expertise, which presents a notable challenge for both researchers and practitioners. This paper presents the first text-to-CQL task that aims to automate the translation of natural language into CQL. We present a comprehensive framework for this task, including a specifically curated large-scale dataset and methodologies leveraging large language models (LLMs) for effective text-to-CQL task. In addition, we established advanced evaluation metrics to assess the syntactic and semantic accuracy of the generated queries. We created innovative LLM-based conversion approaches and detailed experiments. The results demonstrate the efficacy of our methods and provide insights into the complexities of text-to-CQL task.
Lexical Complexity Controlled Sentence Generation
Nov 26, 2022Text generation rarely considers the control of lexical complexity, which limits its more comprehensive practical application. We introduce a novel task of lexical complexity controlled sentence generation, which aims at keywords to sentence generation with desired complexity levels. It has enormous potential in domains such as grade reading, language teaching and acquisition. The challenge of this task is to generate fluent sentences only using the words of given complexity levels. We propose a simple but effective approach for this task based on complexity embedding. Compared with potential solutions, our approach fuses the representations of the word complexity levels into the model to get better control of lexical complexity. And we demonstrate the feasibility of the approach for both training models from scratch and fine-tuning the pre-trained models. To facilitate the research, we develop two datasets in English and Chinese respectively, on which extensive experiments are conducted. Results show that our approach better controls lexical complexity and generates higher quality sentences than baseline methods.