 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactNet: A Billion-Scale Knowledge Graph for Multilingual Factual Grounding
Feb 03, 2026While LLMs exhibit remarkable fluency, their utility is often compromised by factual hallucinations and a lack of traceable provenance. Existing resources for grounding mitigate this but typically enforce a dichotomy: they offer either structured knowledge without textual context (e.g., knowledge bases) or grounded text with limited scale and linguistic coverage. To bridge this gap, we introduce FactNet, a massive, open-source resource designed to unify 1.7 billion atomic assertions with 3.01 billion auditable evidence pointers derived exclusively from 316 Wikipedia editions. Unlike recent synthetic approaches, FactNet employs a strictly deterministic construction pipeline, ensuring that every evidence unit is recoverable with byte-level precision. Extensive auditing confirms a high grounding precision of 92.1%, even in long-tail languages. Furthermore, we establish FactNet-Bench, a comprehensive evaluation suite for Knowledge Graph Completion, Question Answering, and Fact Checking. FactNet provides the community with a foundational, reproducible resource for training and evaluating trustworthy, verifiable multilingual systems.
MEIC-DT: Memory-Efficient Incremental Clustering for Long-Text Coreference Resolution with Dual-Threshold Constraints
Dec 31, 2025In the era of large language models (LLMs), supervised neural methods remain the state-of-the-art (SOTA) for Coreference Resolution. Yet, their full potential is underexplored, particularly in incremental clustering, which faces the critical challenge of balancing efficiency with performance for long texts. To address the limitation, we propose \textbf{MEIC-DT}, a novel dual-threshold, memory-efficient incremental clustering approach based on a lightweight Transformer. MEIC-DT features a dual-threshold constraint mechanism designed to precisely control the Transformer's input scale within a predefined memory budget. This mechanism incorporates a Statistics-Aware Eviction Strategy (\textbf{SAES}), which utilizes distinct statistical profiles from the training and inference phases for intelligent cache management. Furthermore, we introduce an Internal Regularization Policy (\textbf{IRP}) that strategically condenses clusters by selecting the most representative mentions, thereby preserving semantic integrity. Extensive experiments on common benchmarks demonstrate that MEIC-DT achieves highly competitive coreference performance under stringent memory constraints.
From Unaligned to Aligned: Scaling Multilingual LLMs with Multi-Way Parallel Corpora
May 20, 2025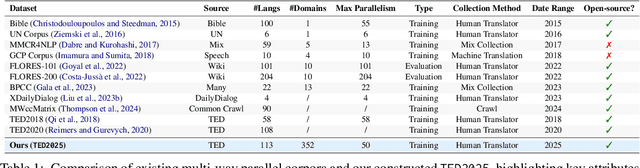

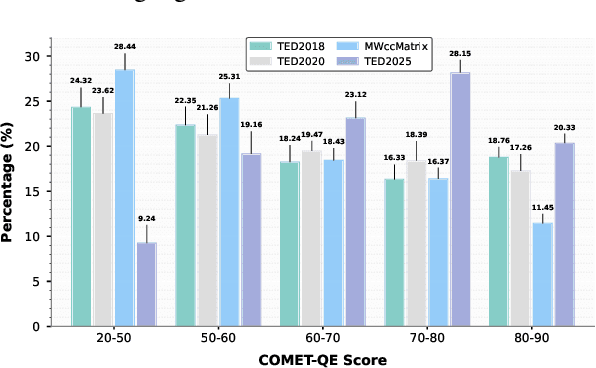
Continued pretraining and instruction tuning on large-scale multilingual data have proven to be effective in scaling large language models (LLMs) to low-resource languages. However, the unaligned nature of such data limits its ability to effectively capture cross-lingual semantics. In contrast, multi-way parallel data, where identical content is aligned across multiple languages, provides stronger cross-lingual consistency and offers greater potential for improving multilingual performance. In this paper, we introduce a large-scale, high-quality multi-way parallel corpus, TED2025, based on TED Talks. The corpus spans 113 languages, with up to 50 languages aligned in parallel, ensuring extensive multilingual coverage. Using this dataset, we investigate best practices for leveraging multi-way parallel data to enhance LLMs, including strategies for continued pretraining, instruction tuning, and the analysis of key influencing factors. Experiments on six multilingual benchmarks show that models trained on multiway parallel data consistently outperform those trained on unaligned multilingual data.
GLTW: Joint Improved Graph Transformer and LLM via Three-Word Language for Knowledge Graph Completion
Feb 17, 2025Knowledge Graph Completion (KGC), which aims to infer missing or incomplete facts, is a crucial task for KGs. However, integrating the vital structural information of KGs into Large Language Models (LLMs) and outputting predictions deterministically remains challenging. To address this, we propose a new method called GLTW, which encodes the structural information of KGs and merges it with LLMs to enhance KGC performance. Specifically, we introduce an improved Graph Transformer (iGT) that effectively encodes subgraphs with both local and global structural information and inherits the characteristics of language model, bypassing training from scratch. Also, we develop a subgraph-based multi-classification training objective, using all entities within KG as classification objects, to boost learning efficiency.Importantly, we combine iGT with an LLM that takes KG language prompts as input.Our extensive experiments on various KG datasets show that GLTW achieves significant performance gains compared to SOTA baselines.
DCAD-2000: A Multilingual Dataset across 2000+ Languages with Data Cleaning as Anomaly Detection
Feb 17, 2025The rapid development of multilingual large language models (LLMs) highlights the need for high-quality, diverse, and clean multilingual datasets. In this paper, we introduce DCAD-2000 (Data Cleaning as Anomaly Detection), a large-scale multilingual corpus built using newly extracted Common Crawl data and existing multilingual datasets. DCAD-2000 includes over 2,282 languages, 46.72TB of data, and 8.63 billion documents, spanning 155 high- and medium-resource languages and 159 writing scripts. To overcome the limitations of current data cleaning methods, which rely on manual heuristic thresholds, we propose reframing data cleaning as an anomaly detection task. This dynamic filtering approach significantly enhances data quality by identifying and removing noisy or anomalous content. We evaluate the quality of DCAD-2000 on the FineTask benchmark, demonstrating substantial improvements in multilingual dataset quality and task performance.